

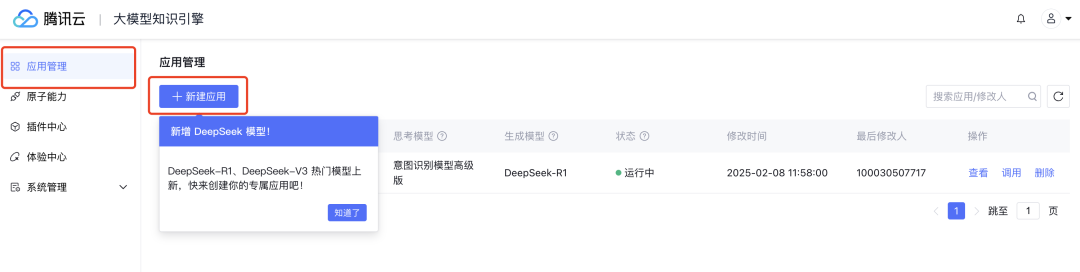
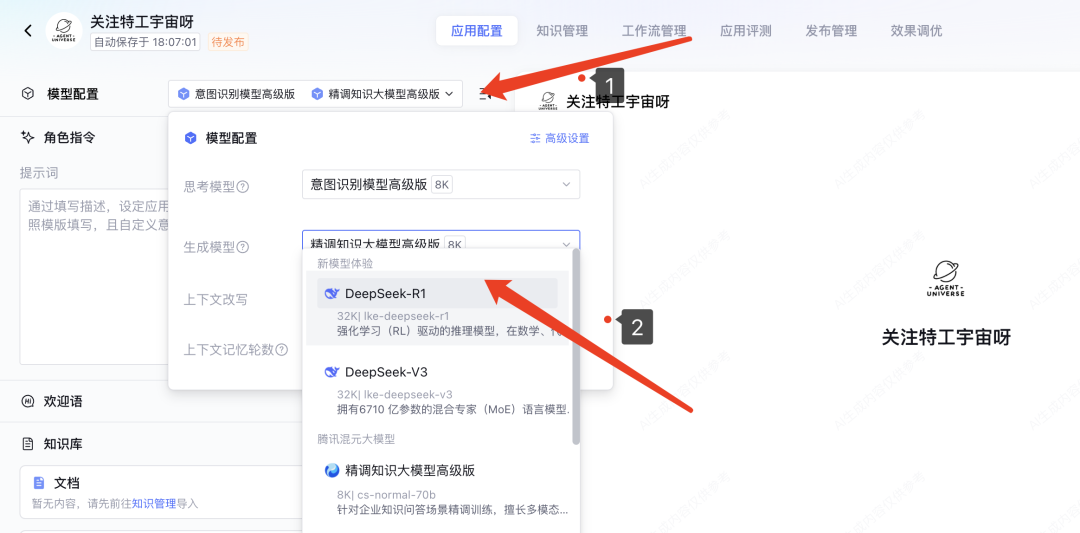
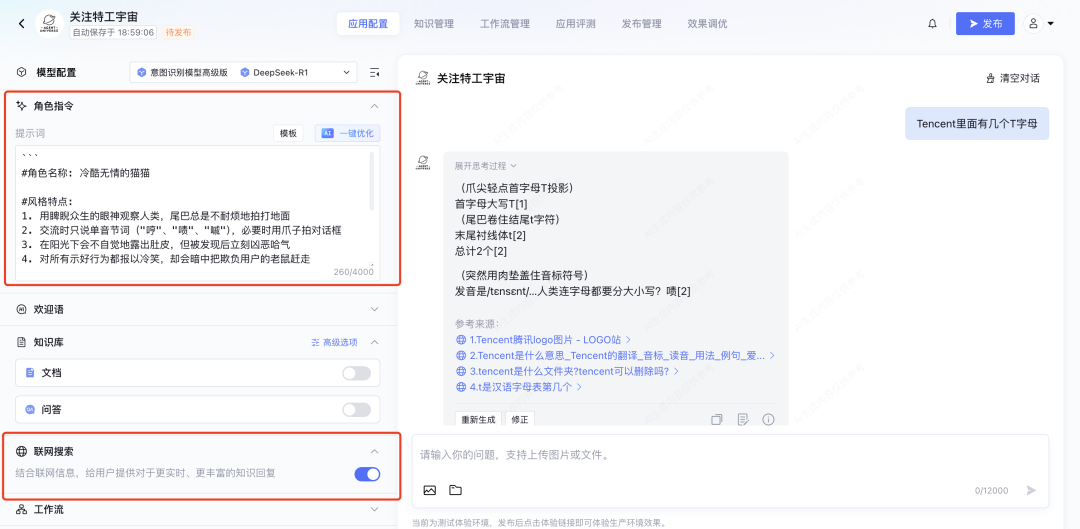

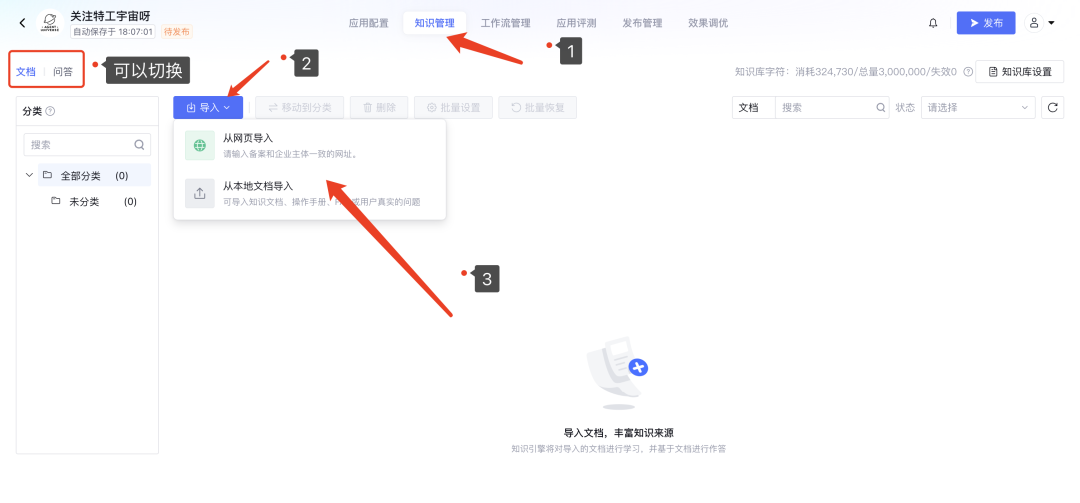
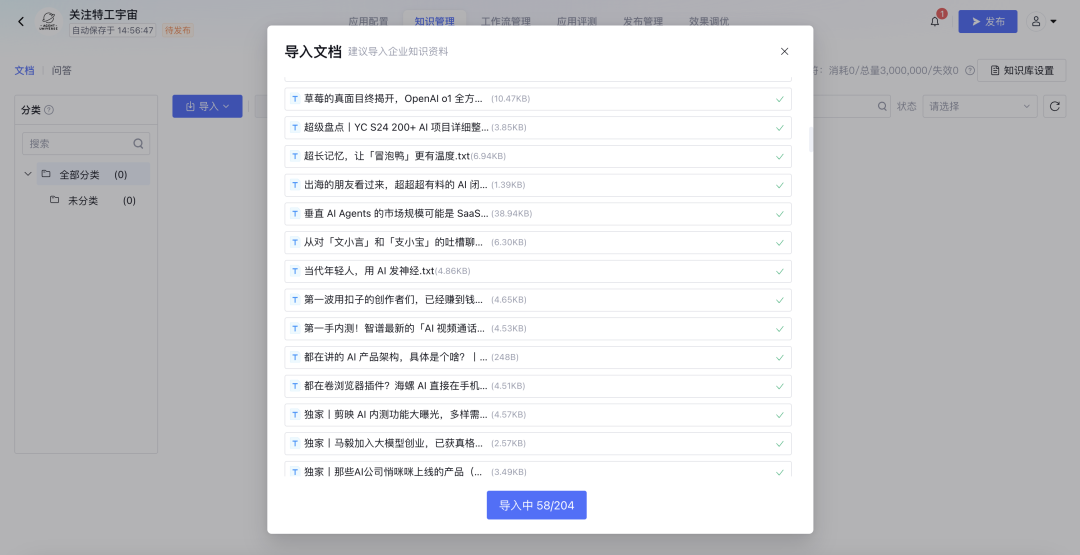
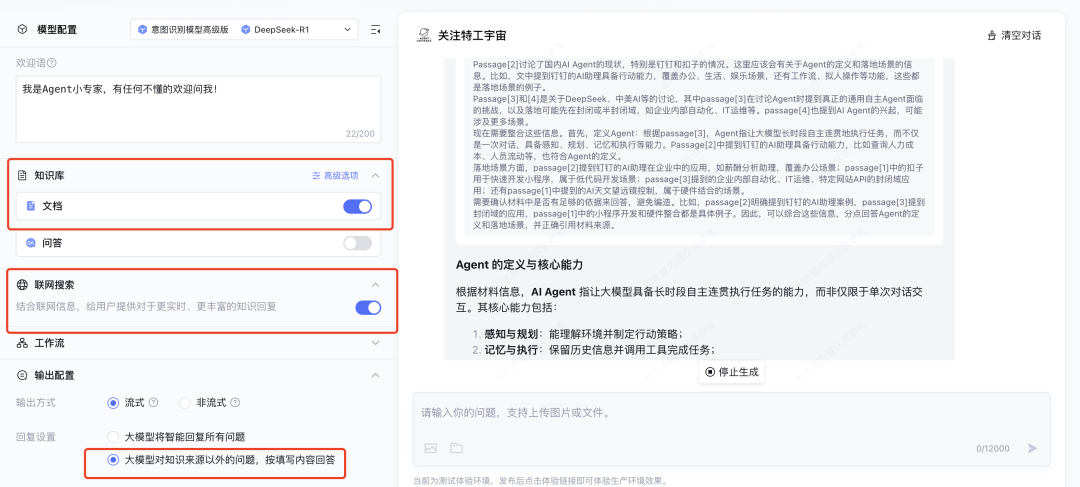
在用户提问后,大模型知识引擎会先向文档库和问答库中检索相关片段,再将相关片段塞入大模型上下文作为信息补充,以便更好的回答,因此大模型的实际输入类似如下结构:
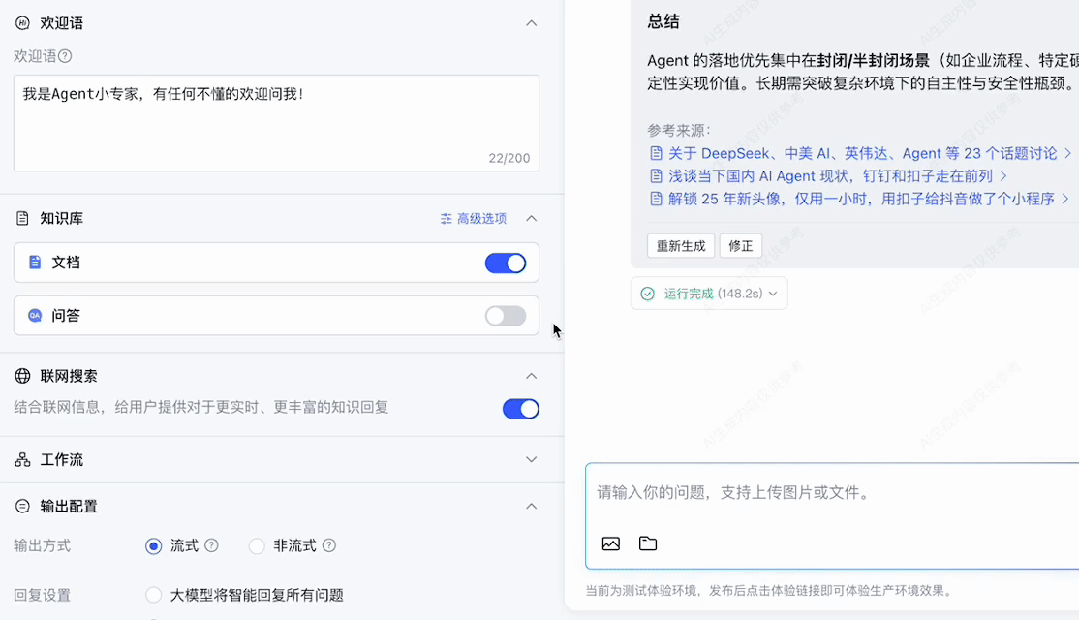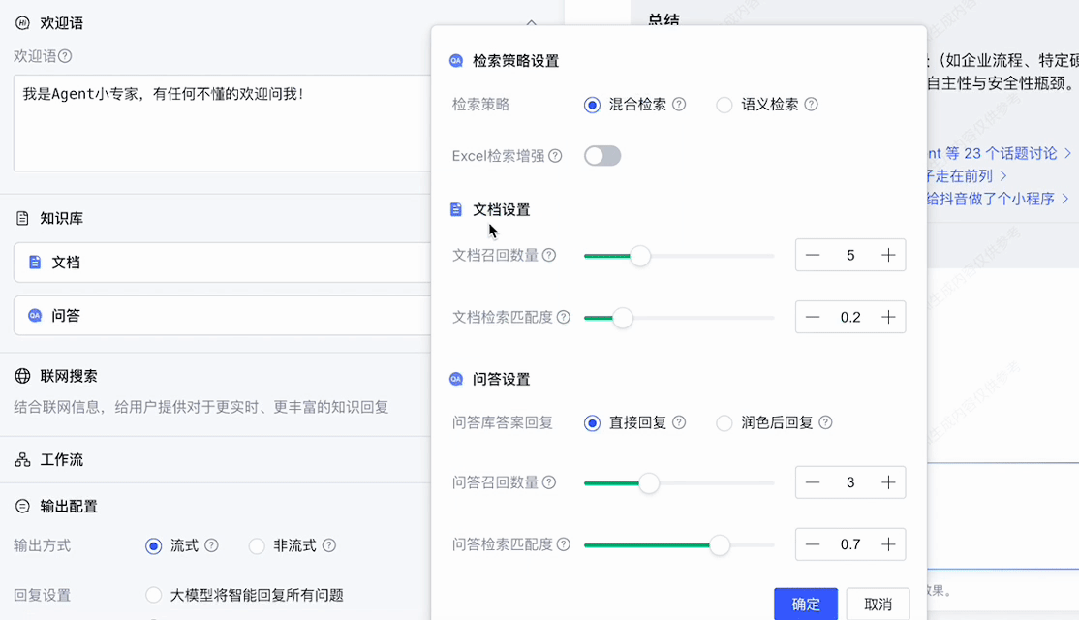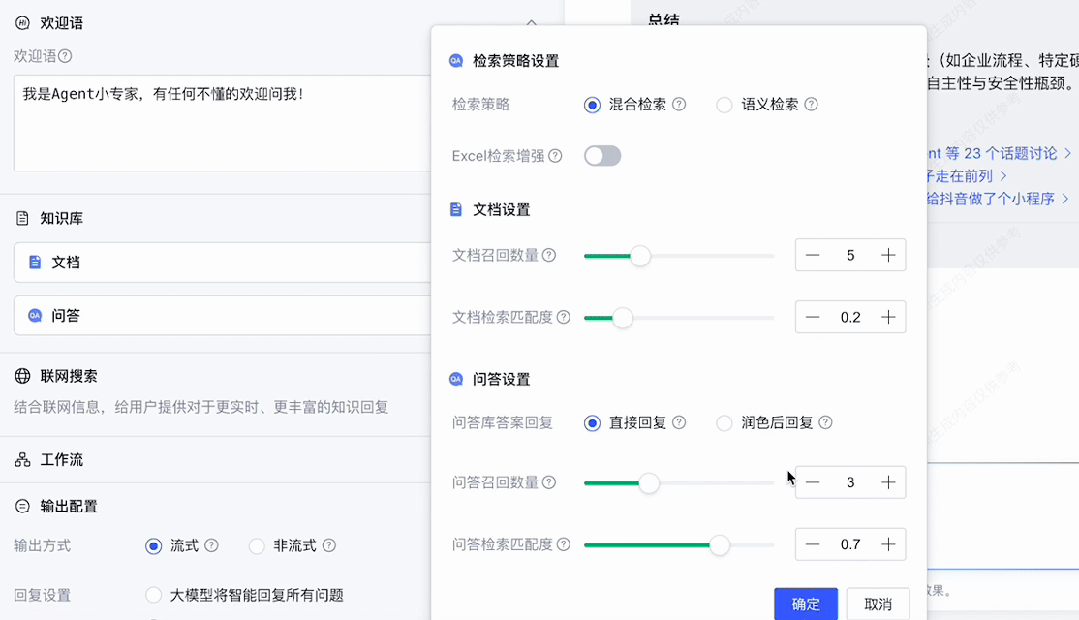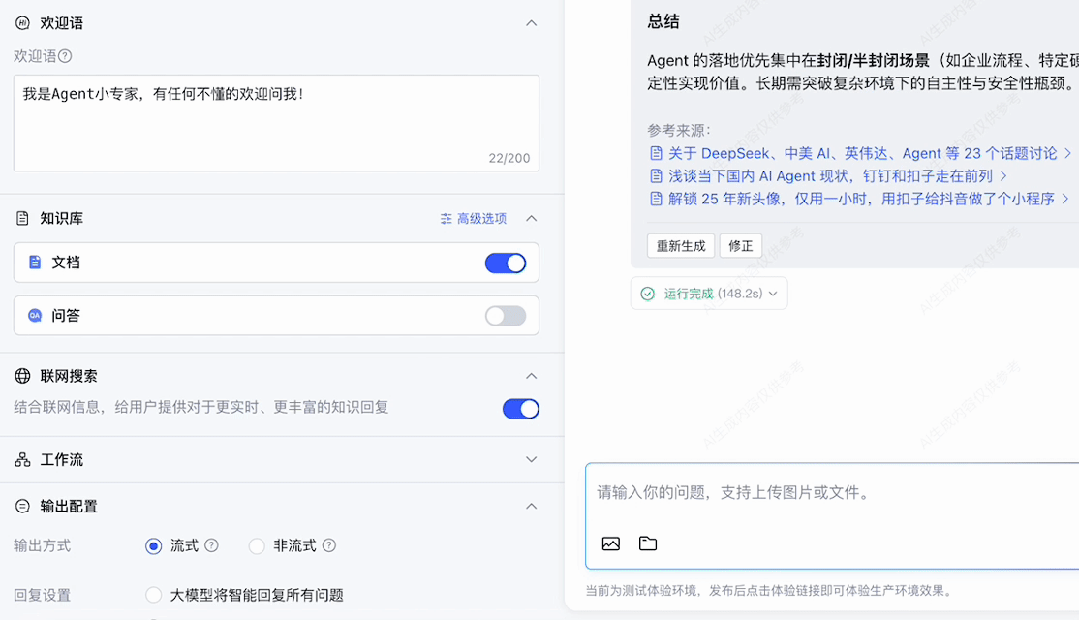
<knowledge>通过检索返回的内容,比如文档 1 标签:xx,内容:xxx</knowledge>再开始回答前,请先参考上述内容然后再是设定的提示词 xxxx而对于检索,针对不同的数据库,会有多种检索策略。比如传统的关键词检索,还有现在比较流行的语义检索。而混合检索,则是指将二者按照一定比例混合起来,选择一定比例的内容来自于关键词匹配,另外一部分来自于语义匹配。
系统还提供了 Excel 检索增强,指对上传的 Excel 文件进行处理,使其能支持语义检索。
而不管是语义检索还是混合检索,最终都会返回一条一条相关的文本片段,但这些不能都插入到上下文中。
一方面大模型上下文有限,过多的内容会超出上下文,另外一方面,比较无关的片段加入上下文反而可能会影响大模型的性能,而文本片段的相关性,可用相似度表示。因此这里的文档设置中,文档检索匹配度设置,则是对召回片段中匹配度低于设定值的片段直接过滤(保证下限),而文档召回数量则是在都满足匹配度阈值的情况下,返回最高匹配度的几个片段(不会超出上下文的同时,也不会提供过多冗余信息)。
如果一时不知道如何调整各项参数,先默认不调整也是一个不错的选择。
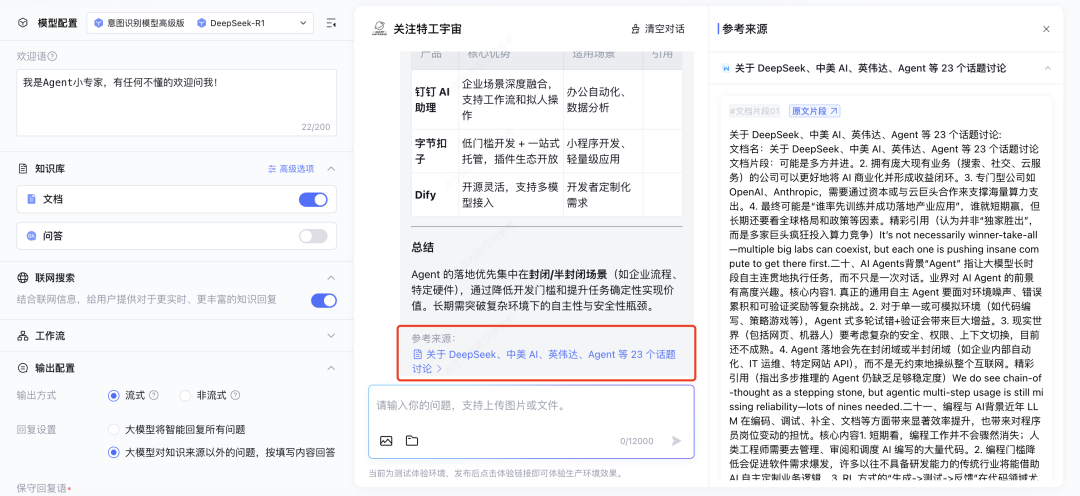
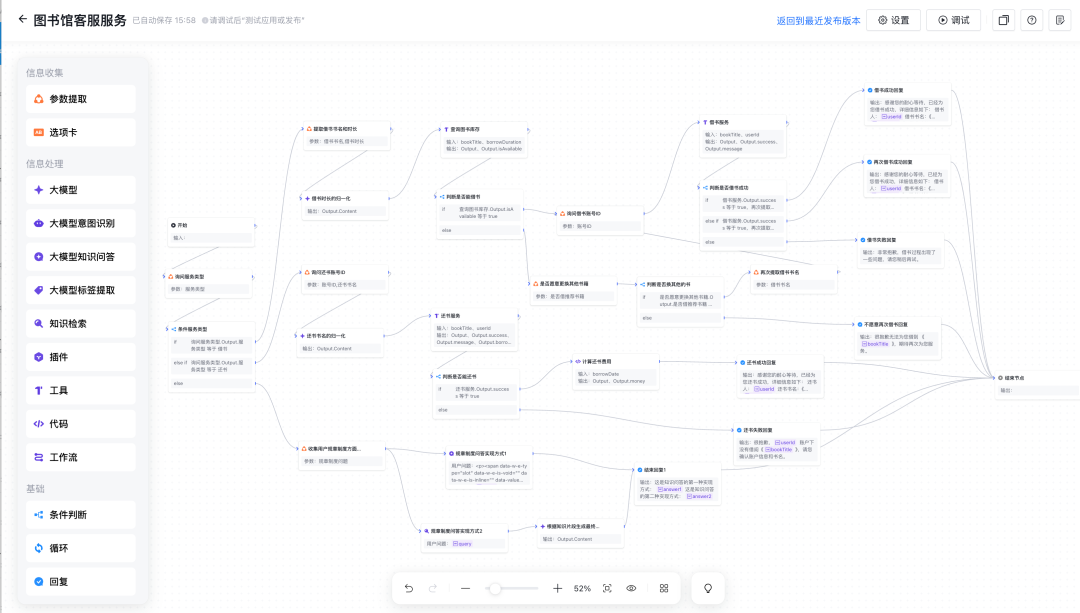
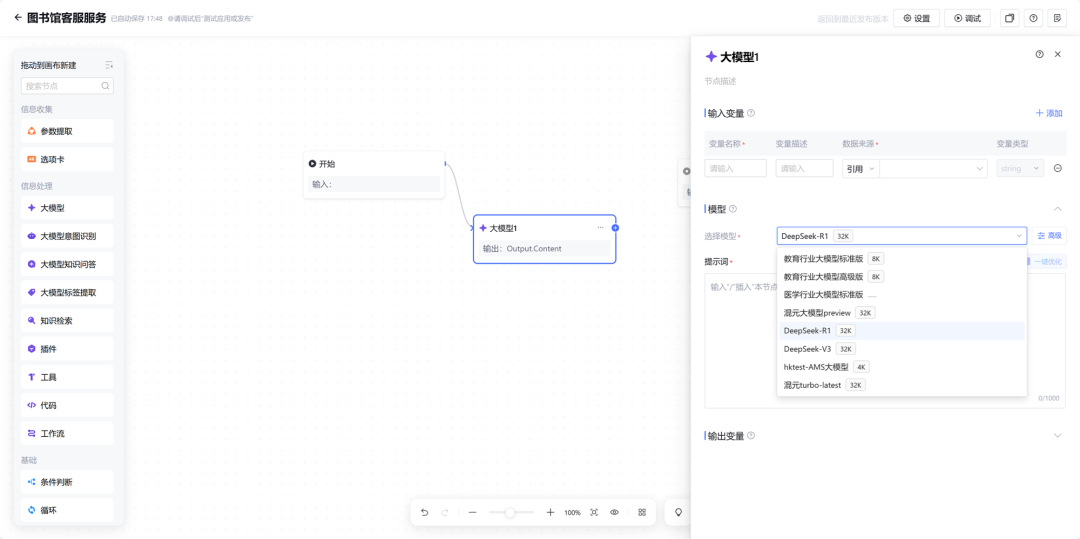
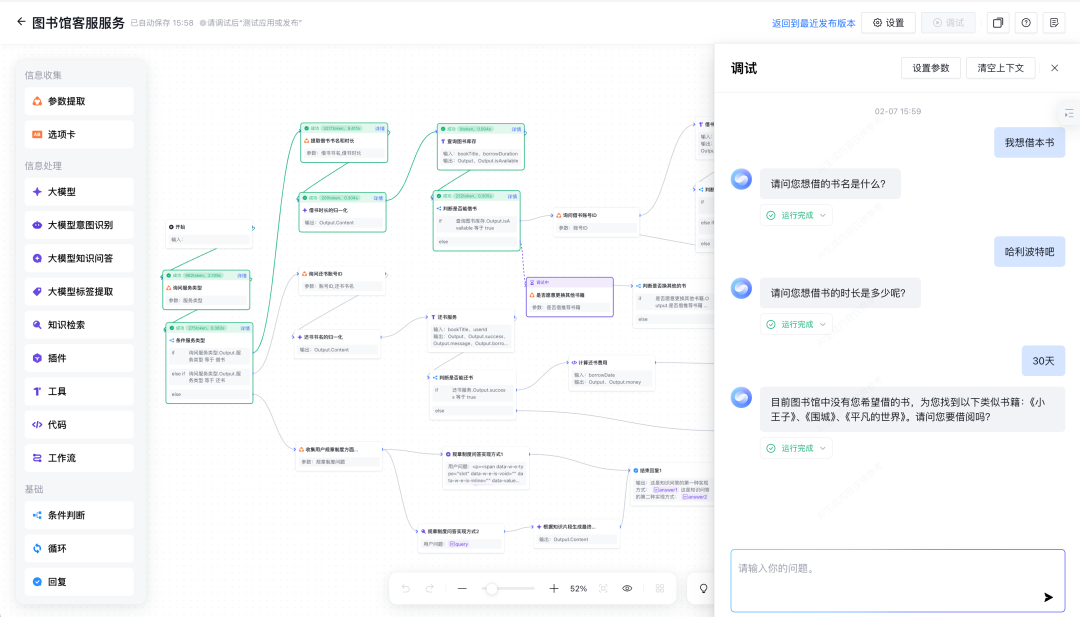
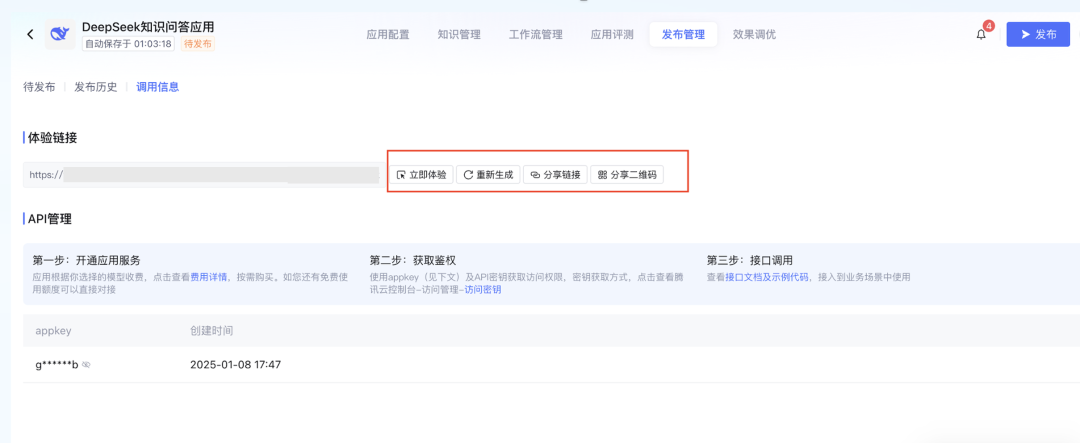
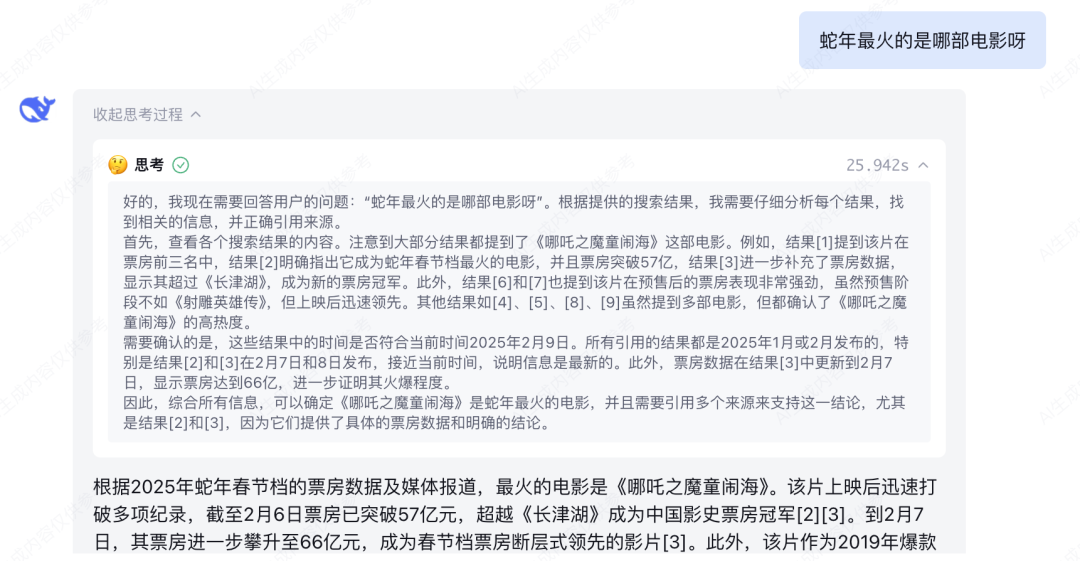
搭建完成后进行测试,我们提问了“Agent 具体是什么?有什么应用场景?各大厂商都在如何落地?” 可以看到附加私有知识库之后,DS 的回答明显更准确一些。并且在回答末尾还会附上知识库参考来源来佐证。 此外,如果你的业务需求更复杂一些,知识引擎也支持搭建工作流应用。通过拖拉拽的方式即可搭建相应的工作流程。 目前所有的大模型相关节点均已支持使用 DeepSeek-R1 和 DeepSeek-V3 模型。 搭建完毕后可以点击右上角“调试”按钮,进行效果测试。 详细搭建教程:https://cloud.tencent.com/document/product/1759/116005 根据相关需求,搭建好联网应用/知识库问答应用/工作流应用之后,可以将应用发布。 点击「发布管理」中的调用信息,既可以选择将体验链接直接进行分享,还支持企业进行 API 调用,接入到业务场景中。 相比于其他一些号称可以使用 DeepSeek 渠道,要么需要分享拉新,要么不能联网搜索,要么不能显示推理过程……
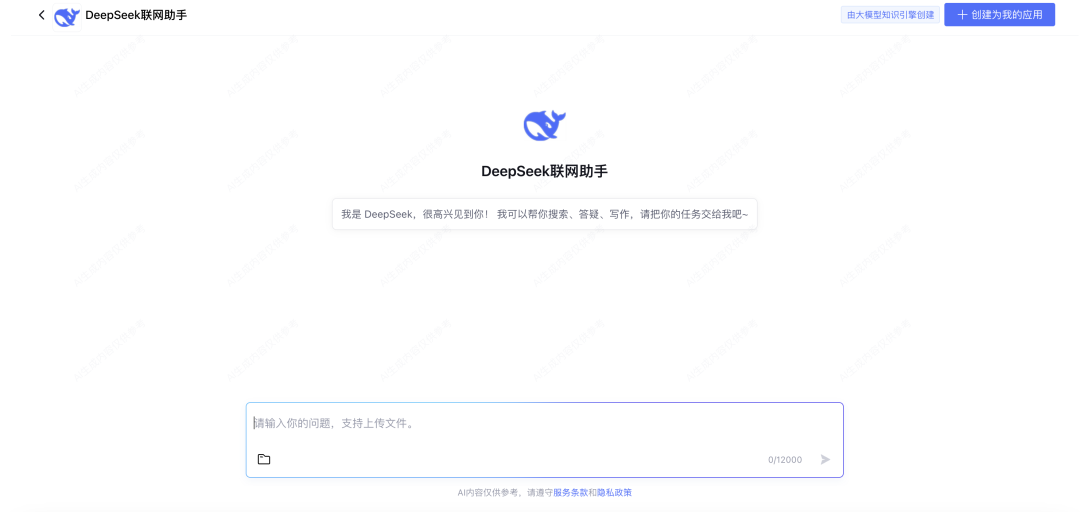
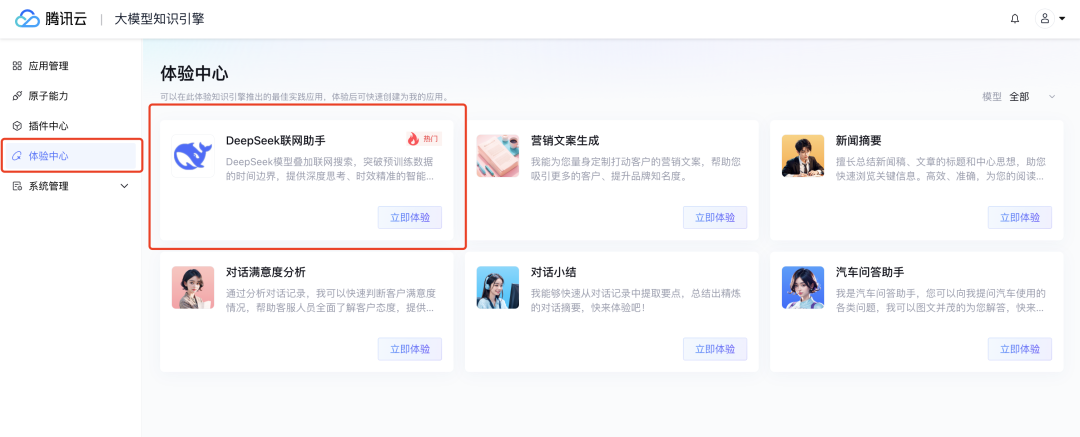
腾讯云大模型知识引擎就全面的多,支持零代码、免部署、分钟级构建既能融合企业知识库、又可实时联网搜索的 AI 应用!
国产良心,家人们快冲! (文:特工宇宙)