

今天是2025年02月09日,星期日,北京,天气晴。
数据工程是个有趣的事情,这是决定模型能力的重要因素,我们可以来看看其中一些关于数据方面的一些问题。
当然,社区也有了一些对应的测试,所以有个讨论,也蛮有意思。分享出来给大家。
专题化,体系化,会有更多深度思考。大家一起加油。
一、明确让deepseek如何思考很重要引来的社区讨论
昨天,有个很有趣的观点,社区几位成员聊到深夜,主要来源于成员的一个有趣的尝试:
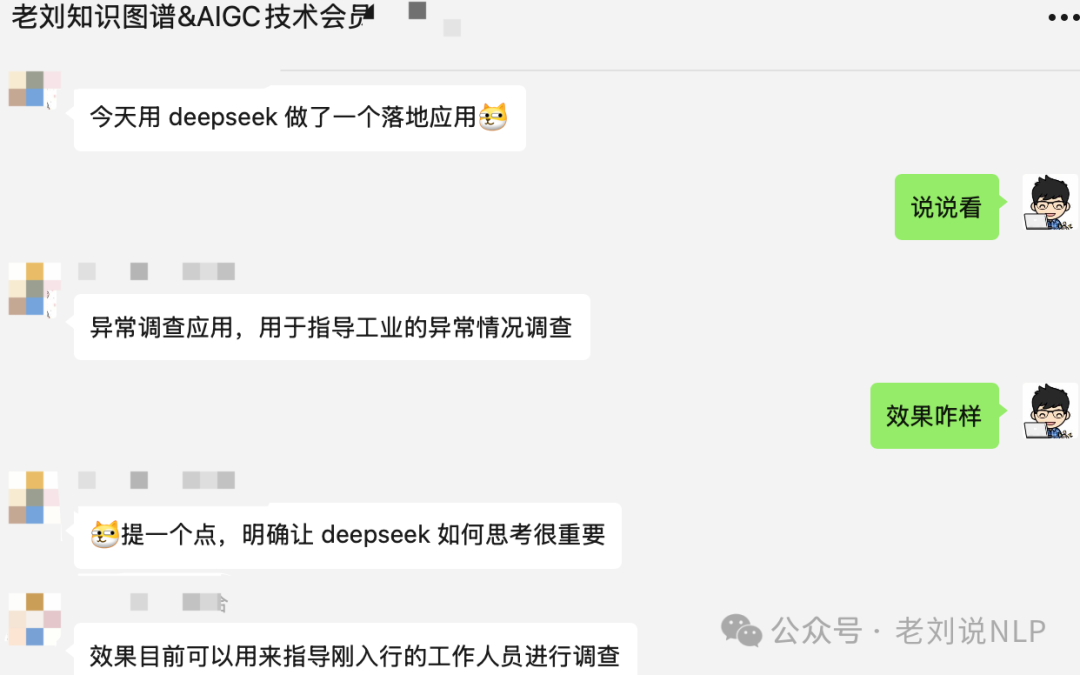
B:今天用deepseek做了一个落地应用,异常调查应用,用于指导工业的异常情况调查,提一个点,明确让deepseek如何思考很重要,效果目前可以用来指导刚入行的工作人员进行调查。
这其实就是对社区在刘说NLP技术社区第37讲《Deepseek R1类推理大模型的习得过程、认知误区、场景机会及技术风险》 分享后,大家从论文层面得到的一些尝试启发,去生成适合自己领域的推理数据。
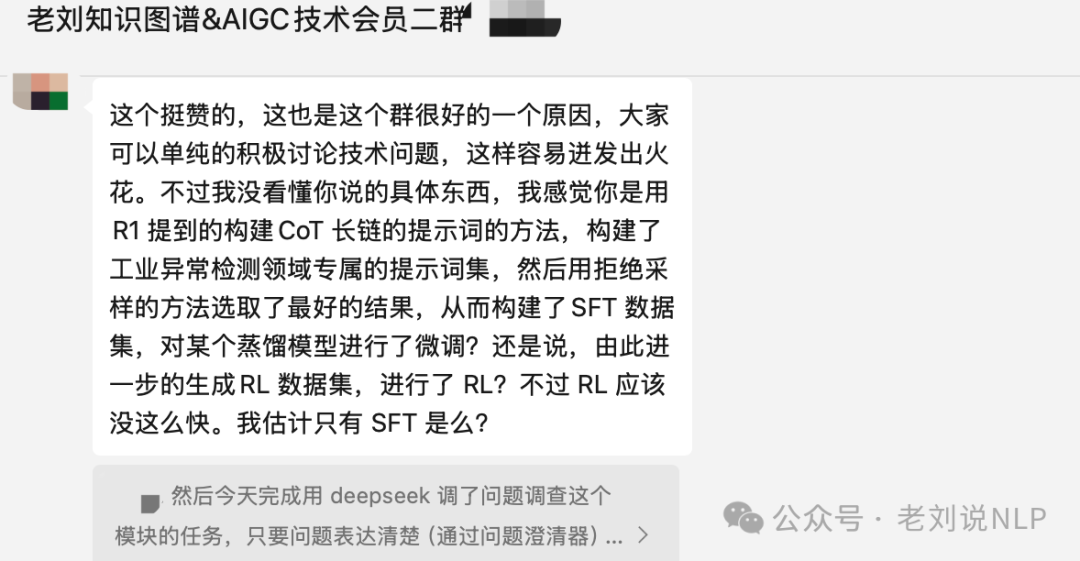
这里做的是一个专属提示词的场景,做的过程中发现用当前调提示词方法产生的 think 数据很不错,可以循环迭代。
这又引出了一些新的思考。以下是部分对话,可以看看,标记为A、B、C、D、E五个人。
A:开始,我想,原理是:如果观察R1的训练路径,会发现,它用了 3 次SFT+RL,而每次 RL 基本保持一致,但是 SFT 所用的数据集都在提升质量。第一次是用来生成 V3 的数据集,这部分来自于R1-lite,应该是一样经过拒绝采样以及人工格式化,这次因为R1-lite 可能是基于V2 做的,所以性能会不好,输出也会较为普通,此轮SFT+RL 的结果是R1-Zero;第二次 SFT,用的是 R1-Zero 生成的数据集,同样经过拒绝采样和人工格式化,然后这轮SFT+RL 的结果是之前我图中所说的R1-beta;然后第三次SFT,其中最主要的推理部分来自于R1-beta,此次SFT+RL 的结果就是最终的R1。从这个流程可以看出,不是冷启动的数据关键,而是SFT 数据很重要,但是通过SFT+RL 这个流程的循环,我们可以不断产生更高质量的SFT 数据。冷启动的那个只是其中一环。而且这个循环不一定就是要停止于第三轮,我们甚至可以进一步的循环以及加大数据量和多样性,从而产生出更高性能的模型。
B:但是我感觉他应该对数据质量也做了一个约束,因为 R1 的 think 是在一定框架内固化的思考方法。除非你给他指定一个思考方式。
A:那我明白你的意思了,这可能和第一次生成冷启动数据时,所做的人工选择和人工格式化有关系。选择的多样性不高,所以后续都在对这几种思维模式进行延伸?就好像一个学生看过例题之后,就总是习惯用例题的方式解题,除非你给他另一个教材的解题方法做例子,否则他不容易跳出这个框架。
B:是的,而且还有一个特点,1.think 的有效性集中在第二段和第四段;2.较大概率(提示词不完善情况下),在第二段末端文字表达和第三段开头的思维链就会出错。;3.较大概率(提示词完善情况下)在第二段末端文字表达或者第三段末端的思考是很准确。但是输出会较大概率不按照这部分输出。这个较大概率在同一个数据集下,90 的情况出现的。不知道为啥
A:我也不知道为啥,但是我记得好像听人说过,R1 的思考过程特别容易放弃,导致观察其思考过程的时候,可以看到有些失败的思考,其实中间环节离正确答案很接近了,但是碰到一些阻力,他就换另一个途径了。
C:思考过程特别容易放弃:这个是什么意思,停止思考还是?
A:我记得是说思考到一个位置,就开始说或许我们可以从另一个方法,然后就从另一个角度开始思考了。并不是结束思考。那应该是思考到了一半发现这条路走不通,就换一条路走吧。思考着思考着就觉得似乎不对,于是就换一条路走。但是,其实并不是绝对走不通,只不过需要进一步的思考罢了。就好像我们做题,有时候解到一半,感觉不靠谱,就开始从别的角度思考,但实际上如果把碰到的卡点突破后,就是答案了。R1 有这种情况,就是碰到卡点后,就跳过,换思路了,然后在多个思路中跳来跳去最终导致回答错误。这是我看到一个人在分析 R1 失败例子时提到的情况。
B:这个看来是我的prompt里会指定思考方式有关系。但是我好奇这个情况,是什么因素触发他会重新思考,什么因素让他觉得思考不对。什么样的数据集会有这种能力。在我的数据集范围内,他错了就一直错了。
D:所以就要去思考,为什么他换了一条思考路径,最终会导致错误。因为我们如果觉得一条路走不通,其实换一条路是为了走到正确的道路,但是你的意思是r1的换思考思考有可能会导向错误的结果。我挺好奇为什么会出现这种情况,而且出现错误的结果,对于模型来说是不是就是出现了幻觉?还是什么。如何定义由于换思考路径而导致错误结果的r1行为。而且有意思的是,对于同一个问题,如果直接问r1,或许会得到错误的结果,但是如果换种方式去问,比如让r1作为某种角色,又能答对。
B:但是,因为 r1 没有事实认定的能力本质他不应该会中断思考,换一条路线。给 r1 的提示词一定要带角色,因为有效数据集里都是明确问题背景和角色的。
C:他真的会用不用的思考去解决一个问题,会质问自己很多遍。他好害怕自己出错,反反复复地确认。
E:我今天试了一个case,让r1做一道无解的countdown问题,他的think非常长,而且最后找不到正确答案,在answer部分同样没法给出答案,但是他自作主张的把题改掉使得等式成立了。整个过程用了将近15分钟。
D:这是不是说明他太害怕得不到正确答案,害怕出错。
E:是的,我也有这感觉。所以哪怕最后思考到山穷水尽也得不到正确答案的时候,就致幻了,跟人好像啊。o1反正就是回答不对这个问题。03 mini明明推理的时候答对了,但是最终答案错了。
B:我更加确认一个事情。因为并不是具备真实的推理能力。模型依旧是见人说人话,见鬼说鬼话,推理模型不过是更高级的人话罢了。依旧是在模仿。这种感觉挺奇怪的,感觉好像内外顺序颠倒了。我们是因为理解了道理,逻辑,规律,才说的人话;而模型是学会了人话,却不明白真正的道理逻辑和规律。因此只是在表达层面拟合人话。这可能是跟我们训练的方式有关系,也跟模型的结构有关系。
D:会不会因为推理模型所需要的算力更高,所以对于openai就随机开放了推理能力。也就是说,不是所有人都能灰度到真正的推理模型。有时候可以有时候不可以。
A:训练方面,我们一直在让模型模仿人类说话,现在推理模型的训练实际上是有些跨出这个边界,促进模型思考,但是这个思考目前还很浅层,所以还是模拟为主,逻辑很弱。在模型结构方面,整个模型从头到尾都是token 贯穿始终,所以一直都是在关注如何理解token 和输出token,或许应该在中间的表意向量空间里进行思考,头尾只不过是理解和表达的人类文字和表意向量空间的转换罢了。
所以关于推理、关于目前DeepSeek-R1的用法,大家现在都在尝试,也都在想着可解释性,这是技术层面的探索,有很多想象空间。后续有更多的测试结果出来,社区继续跟进。
一、DeepSeek-R1中11个数据问题与通俗理解
文章不错,DeepSeek-R1的100问:https://blog.sciencenet.cn/blog-439941-1469698.html,来自王雄科学网博客,原文有100个问题。转载给大家,供大家一起参考。其中关于数据工程部分的几个问题,摘取出来,供大家参考。
1、问题1:DeepSeek-R1-Zero如何通过纯强化学习(RL)实现推理能力的突破?
DeepSeek-R1-Zero的核心创新在于直接从基础模型(DeepSeek-V3-Base)出发,完全依赖大规模强化学习(RL)提升推理能力,跳过了传统的监督微调(SFT)步骤。其采用GRPO(Group Relative Policy Optimization)算法,通过组内归一化奖励信号优化策略。具体来说,GRPO通过采样一组输出(组大小G=16),计算组内奖励的均值和标准差,生成优势函数(advantage),从而避免传统PPO中需要额外训练价值模型的高成本。
这种纯RL训练促使模型自主探索长思维链(CoT)、自我验证和反思等复杂推理行为,最终在数学(AIME 2024 Pass@1从15.6%提升至71.0%)和代码任务中取得显著提升。
想象你教一个机器人解数学题,传统方法是先给它看很多例题(监督学习),再让它自己练习(强化学习)。而DeepSeek-R1-Zero直接让机器人通过“试错”学习,不需要例题。它用一种聪明的算法(GRPO)来评估每次尝试的得分,自动调整策略,最终学会复杂的解题步骤,比如检查自己的答案是否正确,或者换一种思路重新尝试。
2、问题2:为何在DeepSeek-R1中引入冷启动数据(cold-start data)?其核心优势是什么?
冷启动数据用于解决DeepSeek-R1-Zero的可读性和语言混合问题。具体来说,冷启动数据包含数千条高质量的长思维链(CoT)示例,通过人工标注和格式过滤(如使用<reasoning>和<summary>标签),强制模型生成结构清晰、语言一致的内容。其核心优势在于:
-
稳定性:为RL训练提供高质量的初始策略,避免早期探索阶段的输出混乱。 -
可读性:通过模板化输出(如总结模块)提升生成内容的用户友好性。 -
加速收敛:减少RL训练所需的步数,实验表明冷启动后AIME Pass@1进一步提升至79.8%(接近OpenAI-o1-1217的79.2%)。
冷启动数据就像给模型一本“参考答案格式手册”。虽然纯RL能让模型学会解题,但它的答案可能写得乱七八糟。通过先教模型如何规范地写步骤和总结,再让它自由发挥,最终答案既正确又容易看懂。
3、问题3:论文提到“语言混合”(language mixing)问题,具体表现和解决思路是什么?
表现:模型在处理多语言提示时,可能在同一思维链中混合使用中英文(如中文问题用英文推理)。
解决思路:
-
语言一致性奖励:在RL阶段增加奖励项,计算目标语言词汇占比(如中文任务中中文词比例需超过阈值)。 -
数据过滤:冷启动阶段人工筛选单语言示例,强化模型的语言对齐能力。 -
模板约束:强制要求推理和答案部分使用统一语言标签(如 <think zh>和<answer zh>)。
就像一个人学双语时可能混用单词,模型也可能在解题时中英文混杂。解决方法类似“语言考试”:如果题目是中文,就要求全程用中文写答案,否则扣分。模型为了得高分,自然会遵守规则。
4、问题4:蒸馏技术的核心目标是什么?为何小模型通过蒸馏能超越直接RL训练?
目标:将大模型(如DeepSeek-R1)的推理能力迁移到小模型(如7B参数),使其在有限计算资源下接近大模型性能。
原因:
-
数据效率:蒸馏直接复用大模型生成的800k高质量推理数据,而直接RL需从头探索,计算成本高。 -
知识继承:小模型通过模仿大模型的输出模式(如CoT结构),跳过RL的试错阶段。 -
实验验证:蒸馏后的Qwen-7B在AIME 2024达到55.5%,远超直接RL训练的Qwen-32B(47.0%)。
蒸馏就像“学霸笔记”。小模型不用自己从头学解题,而是直接背学霸(大模型)的解题步骤和技巧,这样既省时间又考得更好。
5、问题14:冷启动数据规模仅为数千条,如何保证训练效果?
数据质量 > 数量:
-
多样性覆盖:涵盖数学、代码、科学等核心推理类型,每类数百条。 -
标注严格性:人工筛选可读性高、逻辑连贯的CoT,避免噪声。 -
增强泛化:在RL阶段通过数据扩增(如变量替换、问题重构)生成多样性样本。实证结果:冷启动后模型在AIME任务上收敛速度提升3倍。
冷启动数据像“精品习题集”,虽然题量少,但每道题代表一类典型问题。模型学会方法后,能举一反三解新题。
6、问题19:论文中提到的“自我认知”(self-cognition)数据具体指什么?
自我认知数据用于训练模型回答关于自身能力的问题,例如:
-
示例问题:“你能解决微积分问题吗?”
-
预期回答:“我可以处理基础的微积分计算,但对于复杂证明可能需要更多信息。”
此类数据通过SFT阶段注入,确保模型在开放域对话中合理评估自身局限性,避免过度自信或错误承诺。
教模型“有自知之明”,就像培训客服人员,既要展示能力,也要明确说明哪些问题无法解决,避免误导用户。
7、问题23:冷启动数据如何构造?为何需要人工标注与格式过滤?
构造流程:
-
种子问题收集:从数学竞赛(如AIME)、编程题库(LeetCode)中选取代表性题目。 -
答案生成:使用DeepSeek-R1-Zero生成初始CoT,人工修正逻辑错误并统一格式。 -
模板化:强制要求 <think>和<answer>标签,并添加总结模块(如<summary>关键步骤:...</summary>)。
人工标注的必要性
-
可读性保障:自动生成的CoT可能含无关内容或语言混杂,需人工过滤。 -
格式一致性:确保后续RL训练中奖励信号稳定(如格式错误直接扣分)。
冷启动数据像“标准答案模板”,人工筛选和润色后,模型能学会如何清晰、规范地写出解题过程,而不是乱涂乱画。
8、问题25:拒绝采样(rejection sampling)在SFT阶段的作用是什么?如何筛选高质量数据?
作用:从RL生成的候选答案中筛选高正确率、高可读性的样本,用于监督微调(SFT)。
筛选策略:
-
规则过滤:答案需符合格式(如包含\boxed{})且通过编译/数学验证。 -
奖励阈值:仅保留奖励分高于预设值(如Top 10%)的样本。 -
多样性控制:对同一问题保留最多3种不同解法,避免数据冗余。结果:生成约600k高质量推理数据,错误率低于2%。
拒绝采样像“择优录取”——从模型生成的100个答案中,只挑出最正确、最规范的10个作为学习资料,剩下的不及格答案直接扔掉。
9、问题28:训练模板中<think>与<answer>标签的设计逻辑是什么?
设计目标:
-
结构化输出:强制模型分离推理过程与最终答案,便于规则化奖励计算(如仅验证 <answer>内容)。 -
注意力引导:通过位置编码约束,使模型在生成 <think>时聚焦逻辑推导,<answer>时聚焦结果精度。 -
可解释性:用户可直观查看中间步骤,提升信任度。
技术实现:
-
在输入模板中硬性插入标签,如: User: {问题} Assistant: <think>... </think> <answer>... </answer> -
训练初期通过掩码(masking)强化标签预测准确性。科普解释:标签像“答题卡分区”——模型必须先写草稿( <think>),再填正式答案(<answer>),避免跳步或混乱。
10、问题31:为何在第二阶段RL中引入“多样性提示分布”?
目的:防止模型过拟合初期训练的STEM任务,提升通用性。
实现方式:
-
混合多种提示类型:20%数学/代码题,30%开放式问答,50%多领域任务(如创意写作、翻译)。 -
动态调整比例:每1000步根据模型表现增加弱势任务权重(如写作胜率低则提升其比例)。效果:AlpacaEval胜率从单阶段RL的70%提升至87.6%,且拒绝回答率下降5%。
第二阶段训练像“综合体能训练”——不再只练举重(数学),而是加入跑步(写作)、游泳(翻译),让模型全面发展。
11、问题33:冷启动数据中的“总结”(summary)模块如何提升可读性?
总结模块通过强制模型提炼推理过程的关键步骤,提升输出结构化:
-
信息压缩:要求模型用1-2句话概括最终结论,如 <summary>解为x=2,关键步骤:平方消去根号</summary>。 -
用户友好:用户可直接阅读总结而无需解析长CoT,降低使用门槛。 -
奖励引导:总结的清晰度通过规则化评分(如关键词覆盖率)纳入奖励函数。结果:人工评测显示,带总结的输出可读性评分提升41%。
总结像“论文摘要”——用户不用读完10页推导,只看最后一段就能抓住重点,省时省力。
参考文献
1、https://blog.sciencenet.cn/blog-439941-1469698.html
(文:老刘说NLP)