

今天是2025年7月27日,星期日,北京,晴。
我们继续来回到大模型推理的问题,这是社区的四大主题之一。这个主要是今天社区有说到Qwen3模型将思考和非思考模型分开的话题,进而引出了让大模型自己决定是否要进行思考的有趣话题。
当然,针对这个思考的问题,在技术方案上,我们已经说过8篇,如下:
例如,《如何测量大模型是否过度思考?兼看最近GraphRAG及多模态RAG进展》(https://mp.weixin.qq.com/s/C8rPn-9wa9eE2-kk6zSneg)
《Claude 3.7、QwQ-Max-Preview等推理大模型发布跟踪:兼看大模型逻辑推理技术总结及几点思考》(https://mp.weixin.qq.com/s/T_uBvDlgAihuF9JK3p6caQ)
《近期RAG误区再认识及Claude3.7的混合模型推理机制解析》(https://mp.weixin.qq.com/s/dufuxz5_tLwMx0Zx1E9wIA)
《再看如何控制大模型思考时间?从S1预算控制到L1长度约束强化学习》(https://mp.weixin.qq.com/s/vA0-qSiJkjhfcXZCK2HL0w)
《再看行业R1模型如何构建及减少推理大模型过度思考》(https://mp.weixin.qq.com/s/tHN_DXNlasZb-Yz8AEmKWw)
《Qwen3的混合思考模式再探析及推理大模型系列专题指引》(https://mp.weixin.qq.com/s/H6oRbZ8iTXlT0u9-pKXc8A)
《如何借助分类路由让Qwen3实现思考模式自动切换?兼看DeepFlow等技术进展》(https://mp.weixin.qq.com/s/uEwvZMnH008CFiMeDW4cCw)
《推理大模型思考长度控制策略Thinkless:DeGRPO+short/think标记控制》(https://mp.weixin.qq.com/s/sof9OoO87Y_cLxyG6wqayA)
今天,我们来看这个系列的第9篇,看两个点,一个是Qwen3模型将思考和非思考模型分开的思考,一个是大模型思考切换的过程judge+强化方案-KAT-V1。
技术滚滚向前,让我们聚焦、深度,其中的核心还是梳理清楚逻辑,多思考。
一、Qwen3模型将思考和非思考模型分开的思考
今年4月底,Qwen3系列模型开源,将 “思考模式”和”非思考模式”整合到一个统一的框架中 。”思考模式”专为复杂的、需要多步推理的任务设计,而”非思考模式”则适用于需要快速、基于上下文的回应。还引入了”思考预算”机制。这就像是给模型分配”思考时间”,允许用户在推理过程中根据任务复杂度自适应地分配计算资源。具体实现上,可以通过/think和/no_think指令或API参数动态切换模式,还能设置”思考预算”控制资源分配。
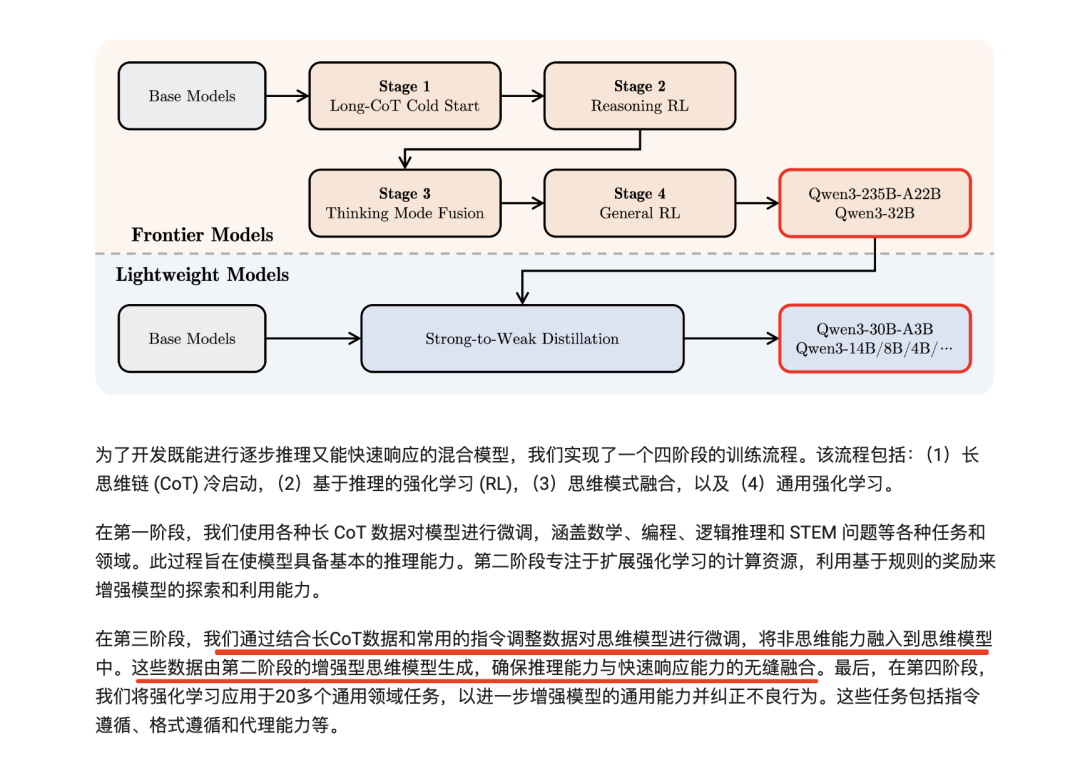
如https://qwenlm.github.io/blog/qwen3/中所述的训练方式,这个核心是:SFT数据集,结合了“思考”和“非思考”的数据。
为了保证该阶段SFT不影响上一阶段的性能,“思考”数据是用第二阶段模型对第一阶段问题进行拒绝采样生成的。
“非思考”数据是精心准备的代码、数学、指令遵循、多语言任务、创意写作、问答和角色扮演等数据。为了更好地融合两种模式,使用户能够动态切换模型的思考过程,Qwen3设计了聊天模板
但近3个月后,这个发生了变化,把这两个模式分开了,思考和非思考两条线同时发展。,分别是非思考模型Qwen3-235B-A22B-Instruct-2507以及思考模型Qwen3-235B-A22B-Thinking-2507,或许是苦think久已?
例如,Qwen3系列新版本Qwen3-235B-A22B-Instruct-2507开源,停用了混合思考模型,新版Qwen3是一个非思推理,又回到了指令微调模型,地址:https://huggingface.co/Qwen/Qwen3-235B-A22B-Instruct-2507,https://modelscope.cn/models/Qwen/Qwen3-235B-A22B-Instruct-2507,也就是说,该模型仅支持非思考模式,并且不会在其输出中生成 <think></think> 块。同时,不再需要指定 enable_thinking=False
但是,过了几天,Qwen3-235B-A22B思考模型升级版本Qwen3-235B-A22B-Thinking-2507发布,还发了个论文,https://arxiv.org/pdf/2507.18071,核心是提出了GRPO的升级版算法GSPO,通过基于序列似然定义重要性比率,并在序列级别进行裁剪、奖励和优化,提高训练效率和性能,对应的地址在QwenChat:https://chat.qwen.ai,https://www.modelscope.cn/models/Qwen/Qwen3-235B-A22B-Thinking-2507;Hugging Face:https://huggingface.co/Qwen/Qwen3-235B-A22B-Thinking-2507
其背后的原因,其实是很有趣的,或许可以从以下几个方面去看。
1、难以掩盖的能力互斥跟边界模糊
思考模式(慢思考)需生成详细推理链(
初始设计中,二者通过/think和/no_think指令切换,但同一模型需同时维护两种能力,会导致参数冲突。如上面所述,这其实高度依赖于SFT数据中的思考数据和非思考数据之间的比例,但两个数据集其实并没有太明确的界限。
而这种边界,或许又直接导致了推理能力和非推理能力都被妥协了,这个证据看第二点。
2、为了更好的性能
Qwen3-235B-A22B-Instruct-2507在优化方式上,大幅增加了多语言长尾知识的覆盖范围,更好地符合用户在主观和开放式任务中的偏好,能够提供更有帮助的响应和更高质量的文本生成。
如下图,混合模型Qwen3-235B-A22B Non-thinking(开启非思考模型) vs Qwen3-235B-A22B-Instruct-2507的差距,很明显:
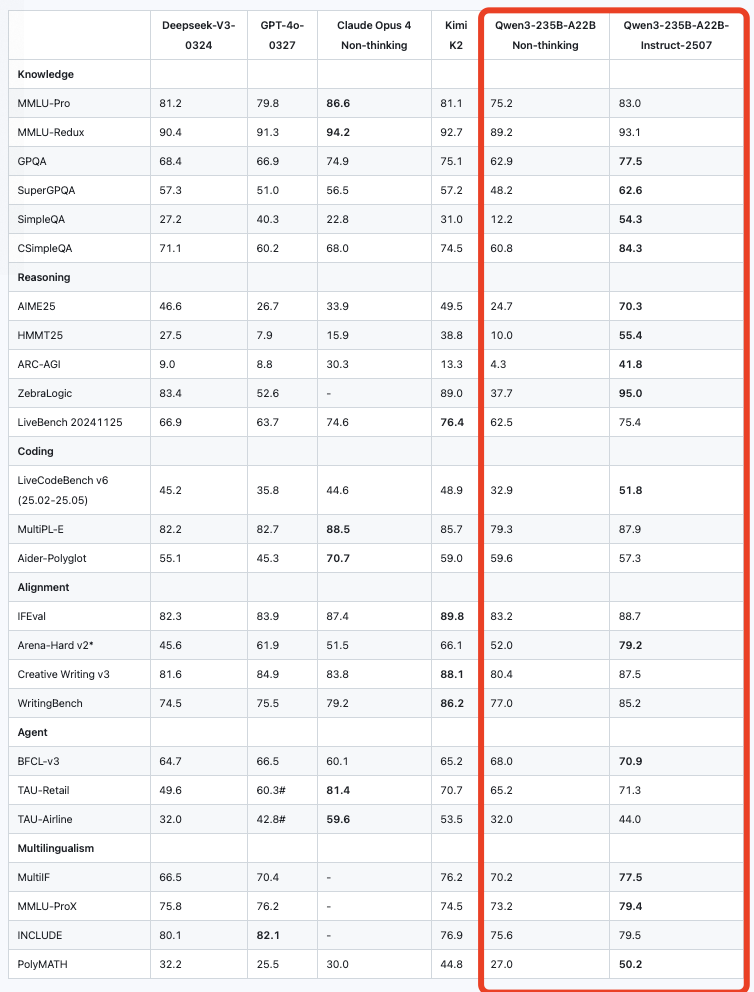
尤其是写作任务(WritingBench)达85.2分。
尤其是Qwen3-235B-A22B-Instruct-2507 在多项基准测试中相较前代有显著提升,特别是在推理、编程和多语言任务上,是否意味着混在一起,会直接制约非思考模型的推理性能?
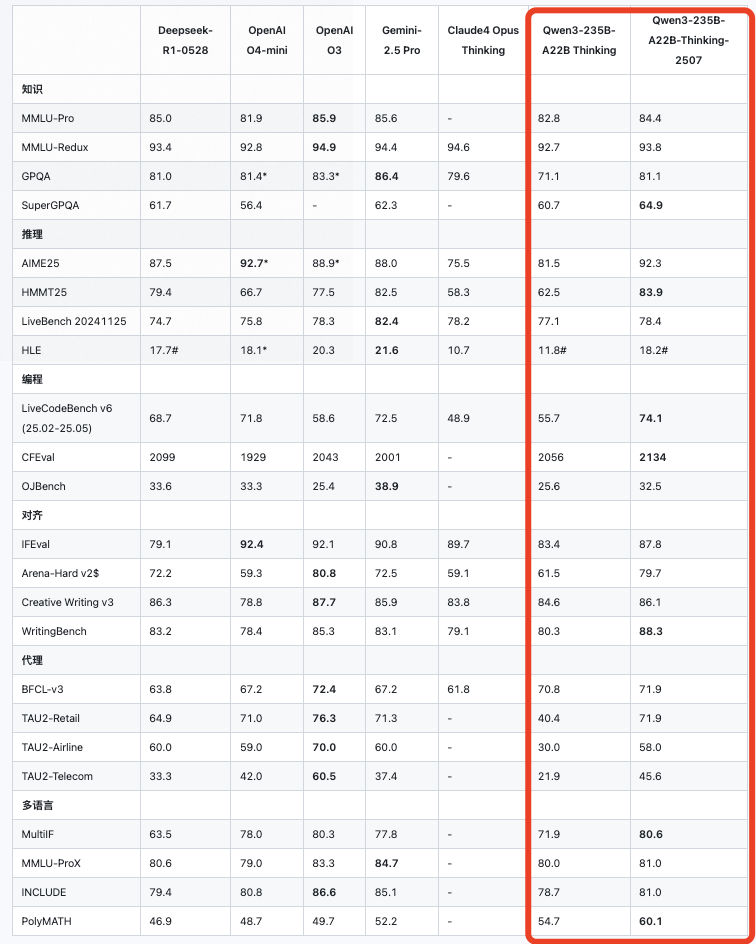
Qwen3-235B-A22B-Thinking-2507继续提升了Qwen3-235B-A22B的思考能力,提高了推理的质量和深度,在逻辑推理、数学、科学、编码和通常需要人类专业知识的学术基准等推理任务上的显著提升性能。
如下图:Qwen3-235B-A22B-Thinking-2507 vs Qwen3-235B-A22B Thinking,也可以看到,相较于原先版本,其实有较大的提升。
3、为了更适配应用场景
用户可能更倾向明确场景选择。提到社区反馈:需要深度推理时选Thinking版,常规任务用Instruct版更高效,这种分野让产品定位更清晰。
实际上,在真实使用场景下,并不是很清晰地将其分开,有些场景的任务数据,在sft 阶段并没见过,所以是否思考表现的也并不稳定,所以,在更多时候,用户实际更倾向明确选择模式,而非依赖自动切换。
我们去看qwen3的 github,里面其实有关于think的不少使用的badcase,也印证了这一点,主要体现就是:混合模式中“强制思考”导致简单任务延迟过高,而“强制非思考”又降低复杂任务成功率。
最后做个总结,从“混合”到“分离”的转变,本质是模型专业化与场景精细化的必然结果。短期内,独立模型能最大化极端性能需求(速度/深度),通用性与专精性难以兼得,为了通用牺牲精度,其实会导致哪个都做不好。但是,这个路线并不说是错的,知识方式目前有折中,混合推理依旧是长期方向,这点跟rag 中的 when to retrieval 问题是一致的。
二、大模型思考切换的过程judge+强化方案-KAT-V1
当然,即便qwen3的转变已经发生,但是依旧还是有一些工作,依旧按着融合的思路在走。
例如,今年6月份的KwaiCoder-AutoThink-preview,https://huggingface.co/Kwaipilot/KwaiCoder-AutoThink-preview,这块的方案在:https://mp.weixin.qq.com/s/EcH4GMRtVkvGByonRU5H-Q,其实现思路也很自然,如下图所示:
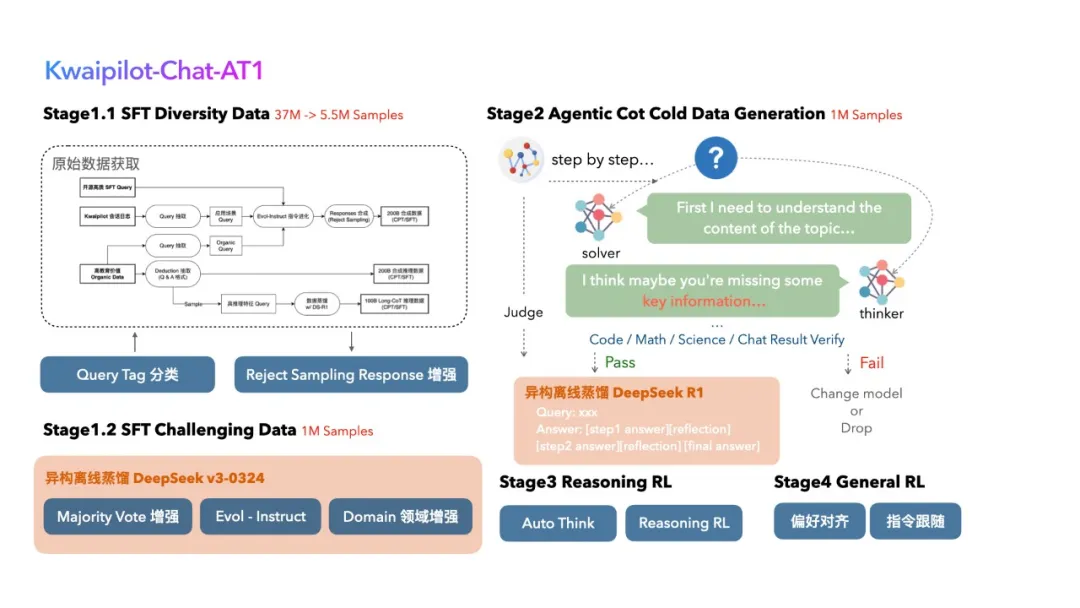
采用了两步式训练方法,首先通过Agentic 方法构造长短思考的Cold Start数据让模型在进行思考之前先进行一个“pre-think”,判断一下问题的难度。
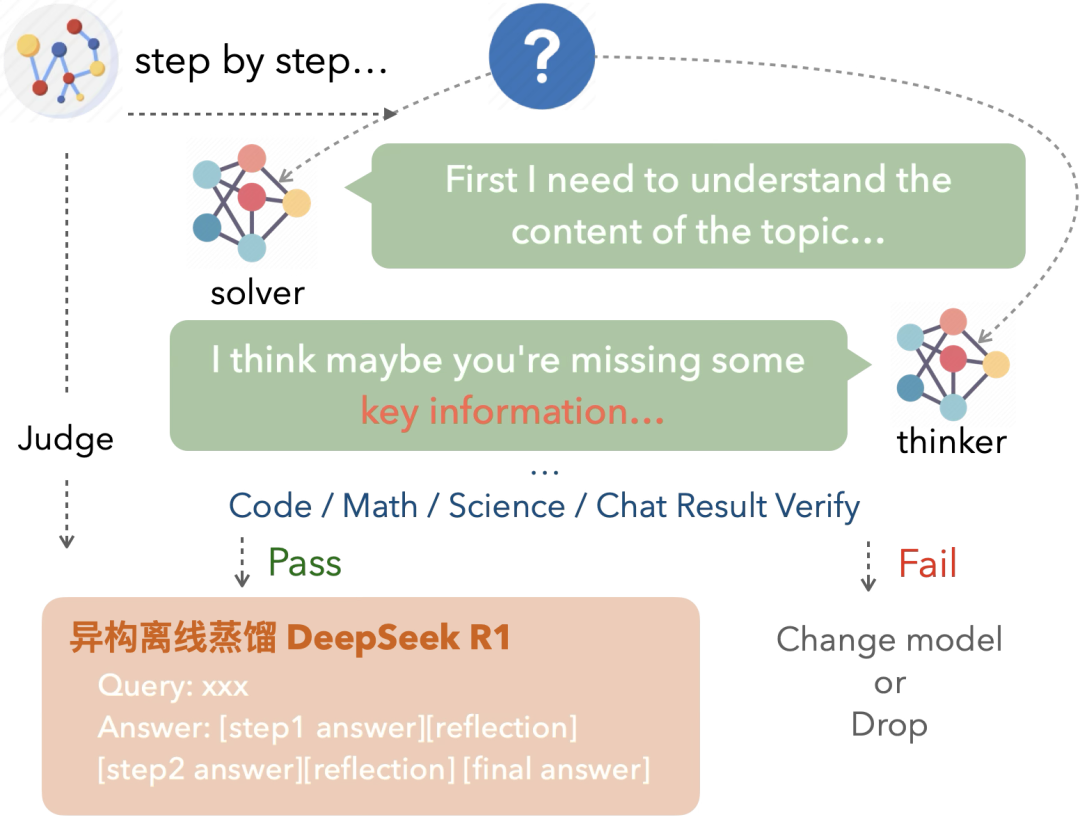
然后再使用加上专门为Auto Think任务设计的带有过程监督的Step-SRPO增强模型对各种任务难以程度判断的准确性,但是细节并未说的很清楚。
然后,后续工作KAT-V1,https://huggingface.co/Kwaipilot/KAT-V1-40B,40B和200B(目前未开源)两个版本,则说的更详细些,其主要想解决推理密集型任务中的过度思考问题,通过提出一种自动思维训练范式,根据任务复杂度动态切换推理与非推理模式。40B由Qwen2.5-32B扩展而来,通过分层定向扩展的策略,将模型参数量有选择地扩展到40B。
方案在《KAT-V1: Kwai-AutoThink Technical Report》,https://arxiv.org/pdf/2507.08297,也可以参考官方技术博客,https://mp.weixin.qq.com/s/VQo5uRAJGGqhwlf7it1GlA,这里的思考叫做Think-On,非思考叫做Think-Off。
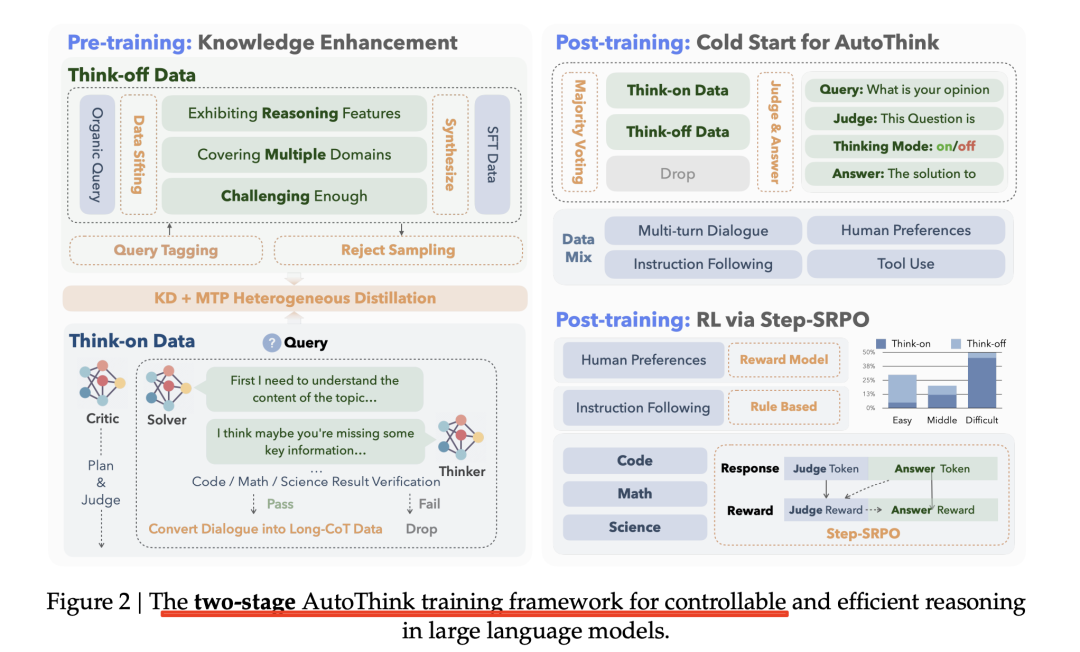
我们核心看几点:
1、思考/非思考数据构建
对于非思考数据,为了保证问题的广泛性,从预先收集的5TB tokens预训练数据中,抽取出部分带有推理特征、具有一定难度的多领域数据,总共大约1000万个示例的语料,其中约34.8%的数据为思考数据,约65.2%的数据为非思考数据,数据涵盖了科学、代码、数学、工具调用和通用知识等领域。
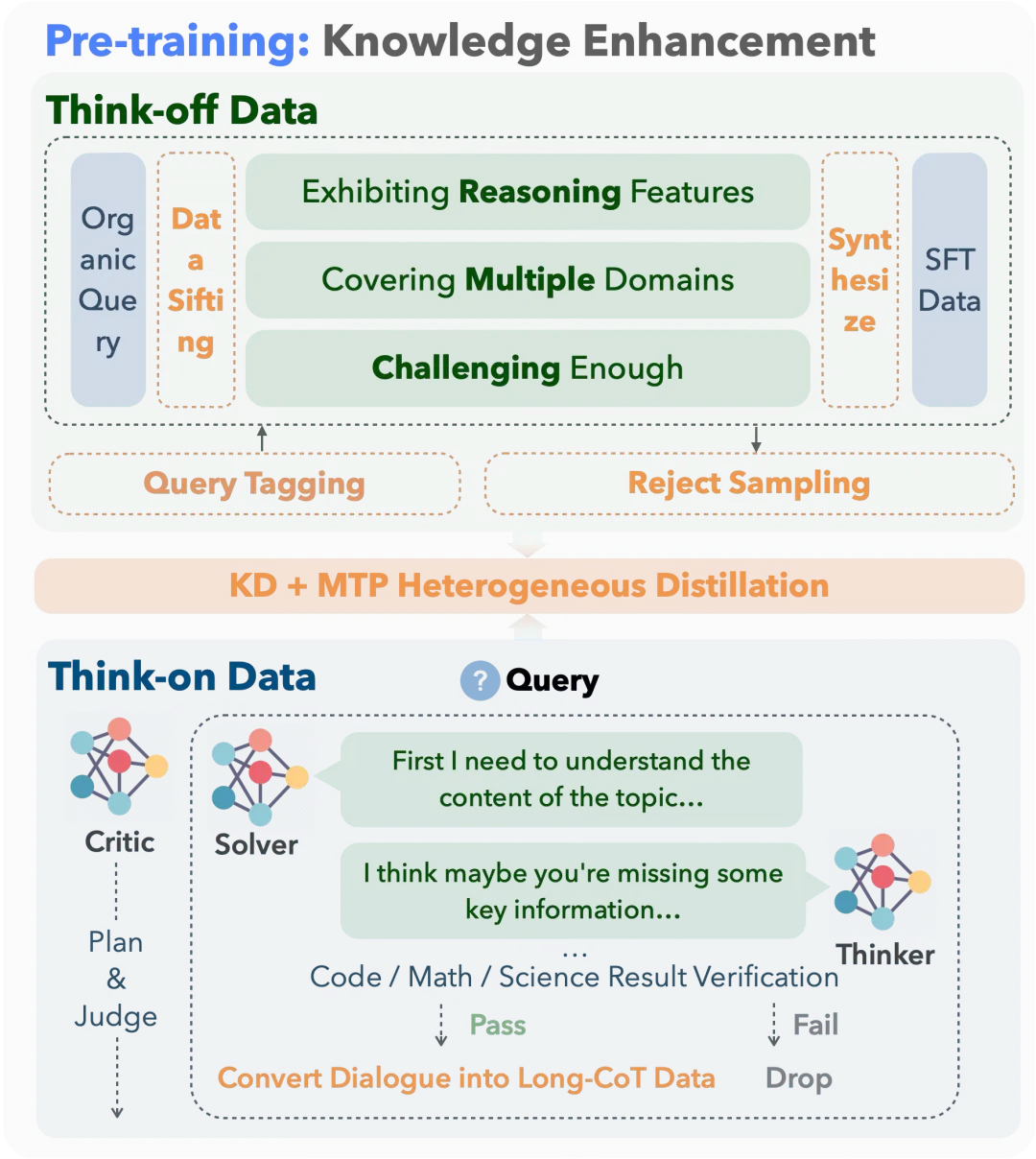
其中,非思考数据使用DeepSeek-V3生成,同时运用强模型进行拒绝采样,确保仅筛选出最准确、最相关的完成结果,从而保证输出质量。
思考数据则使用一个Agentic框架来合成,该框架由解答者(solver)、思考者(thinker)和评论者(critic)组成。解答者(DeepSeek-R1)先提供初步答案,思考者对解决方案进行反思和迭代改进,评论者对整个流程进行监督,以保证逻辑一致性和输出质量。
最终训练数据中使用的格式化模板如下,所有数据都使用统一模板,包含对是否需要推理的判断、(如需推理时的)推理过程及最终回答,使模型既能判断是否推理,又能清晰区分分析与作答。

可以看到,这个比qwen的数据,多了一个judge的过程,如何判断用户意图以及问题难度,并决定如何思考后再进行回答。
而为提升模型对思考模式的理解,每条样本还由DeepSeek-V3生成解释说明合理性,作为额外训练信号,并将约1%的数据随机分配模式防止过拟合
2、切换能力训练
仅通过精细化数据SFT所获得的判断能力受到数据制约,这个其实也就是上面说的这个qwen 的问题,泛化性且左右摇摆,虽然加了一个judge的过程。
所以,很自然的方式就是强化学习,但是强化的核心还是强化的信号,奖励函数的问题,因此搞了个一种分布式奖励的强化学习算法:Step-SRPO。
其思想在于,模型先进行“推理必要性评估”,判断每个问题是否需要深入思考,也就是judge 的过程,然后通过双重奖励机制引导学习。
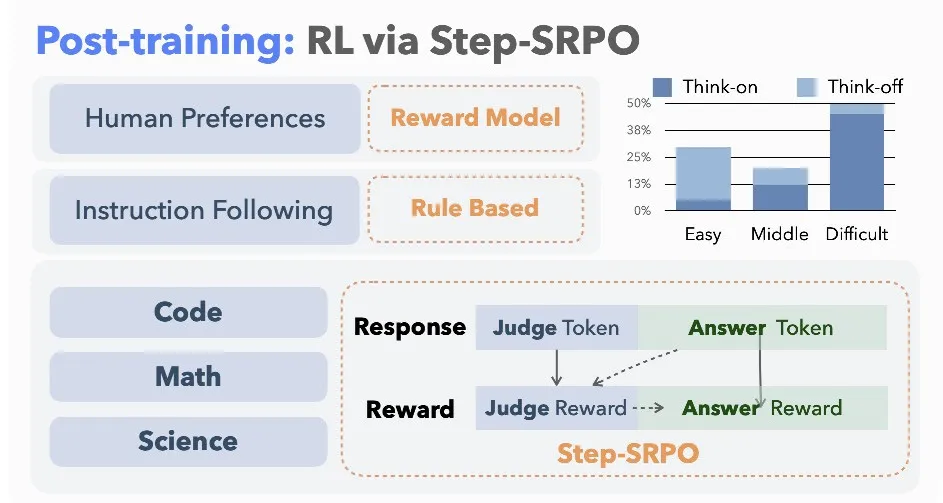
其中,包括几个奖励函数:
判断奖励(Judge Reward)根据模型是否正确选择推理模式打分,鼓励准确判断推理需求;
答案奖励(Answer Reward)依据最终回答的正确性和质量进行评分,并结合判断奖励进行调整,确保回答质量和推理选择相一致。
下面这张图就很有意思,Step-SRPO下推理模式选择的训练动态监控:
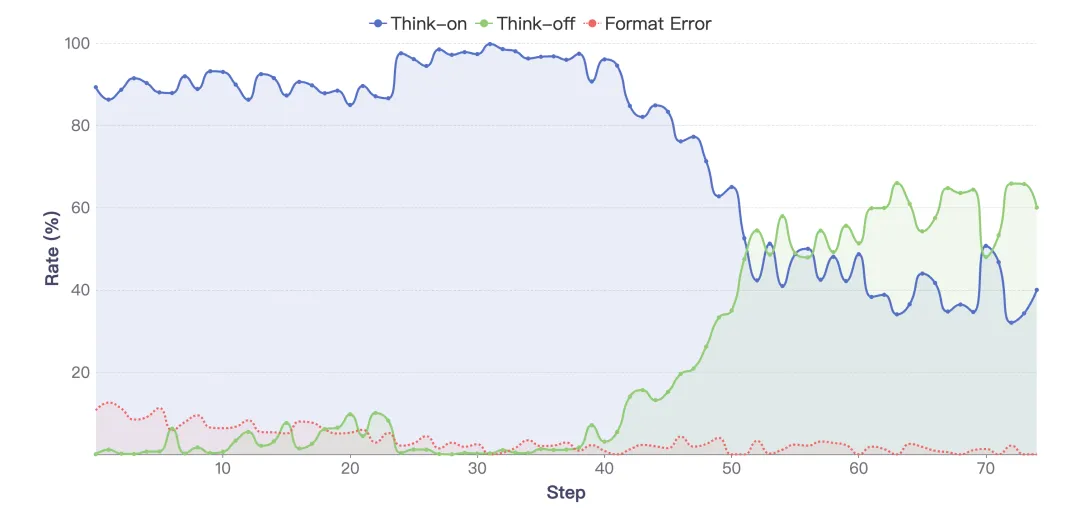
可以看到,模型在训练阶段,由于强化学习的奖励策略,模型开启think-on的比例不断降低,很有趣。
所以,还是那样,是否可行,其实得看实现路线。
参考文献
1、https://mp.weixin.qq.com/s/EcH4GMRtVkvGByonRU5H-Q
2、https://mp.weixin.qq.com/s/VQo5uRAJGGqhwlf7it1GlA
(文:老刘说NLP)