


人工智能正在从“对话者”进化为“执行者”。OpenAI最新发布的ChatGPT Agent,通过将精于网页交互的Operator和善于信息整合的Deep Research合二为一,重新定义了智能体的概念。其核心是在一个专属的虚拟计算机环境中,利用强大的工具箱为你执行复杂任务。虽然官方性能数据亮眼,但其“98%正确率”引发了关于验证成本的深度思考。这标志着一个需要用户以全新方式进行监督与协作的“人机在环”新时代的开启。
AI新范式:从“对话”到“行动”的统一
正如OpenAI CEO Sam Altman在发布会上所言,用户真正期待的,是AI能够超越简单的对话,成为一个能够“使用自己的计算机,为他们完成真实、复杂任务的统一智能体”。这种智能体需要无缝地在思考、行动和使用多种工具之间切换,无论是点击网页,还是生成电子表格和幻灯片。
ChatGPT Agent不再是单一功能的叠加,而是将两大前沿探索方向的战略融合:
-
• Operator (行动者):一个能够模拟人类在网页上点击、滚动和输入的“智能操作手”。 -
• Deep Research (研究者):一个能够深度整合信息、撰写详尽报告的“研究分析师”。
通过将两者统一,OpenAI创造出了一个既能独立思考,又能与数字世界深度交互的全新物种。
技术拆解:Agent如何拥有“三头六臂”?
要理解ChatGPT Agent的能力,关键在于其独特的工作机制。它不再局限于生成文本,而是拥有了一个可以施展拳脚的、功能完备的“工作台”。
核心基石:专属的“虚拟计算机”
ChatGPT Agent的所有任务都在一个独立的虚拟计算机环境中执行。这就像为AI提供了一个专属的云端办公室,它可以在这个安全的沙盒里自由地浏览网页、运行代码、下载和处理文件。这个设计确保了任务执行过程中的上下文连贯性,即使在多个工具之间频繁切换,也能记住任务的总体目标和进度。
能力核心:智能驱动的“瑞士军刀”工具箱
在这个虚拟环境中,Agent配备了一套强大的工具箱。通过强化学习训练,模型学会了根据任务需求,智能地选择和组合使用这些工具:
-
• 文本浏览器 (Text Browser):专为高效信息获取而设计。当任务需要快速阅读和理解大量网页文本时,Agent会调用此工具,如同一个不知疲倦的研究员,迅速消化海量信息。 -
• 可视化浏览器 (Visual Browser):这是Agent与现代互联网交互的关键。面对复杂的网页UI,它能像人类一样定位并点击按钮、填写表单、拖拽滑块,从而完成在线预订、登录账户等需要图形界面交互的操作。 -
• 代码终端 (Terminal):这是Agent的“超能力”所在。它不仅能运行代码来处理数据、进行复杂计算,还能直接生成和编辑结构化文件,比如创建包含图表的 .pptx演示文稿或.xlsx电子表格。更重要的是,它能通过终端调用API,连接到你的Google Drive、GitHub等私人数据源,实现深度个性化任务。
应用场景:从想法到现实的全过程
官方演示生动地展示了这套技术组合的威力,将抽象的能力具象化为具体的应用场景:
-
• 场景:策划一场复杂的个人活动
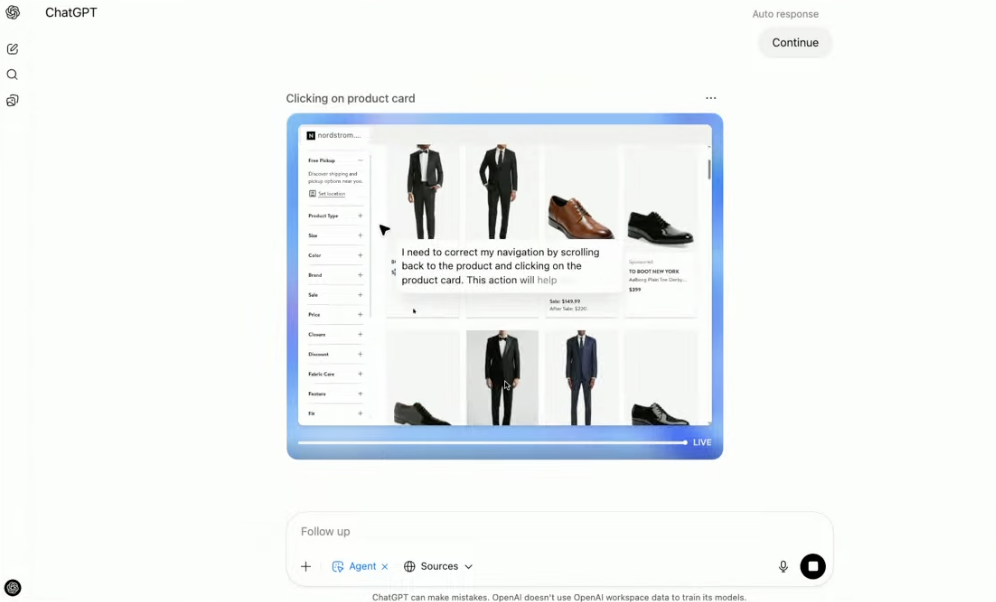
用户可以提出一个综合性需求,例如:“为我朋友在下个月的婚礼做准备”。Agent会启动一个多步骤流程:首先通过文本浏览器访问婚礼信息网站,获取日期、地点和着装要求;接着,利用可视化浏览器在电商网站上筛选符合要求的礼服,并查看商品图片和评价;然后,它会查询酒店预订平台,寻找合适的住宿选项;最后,整合所有信息,形成一份包含服装、酒店和礼物建议的综合报告。 -
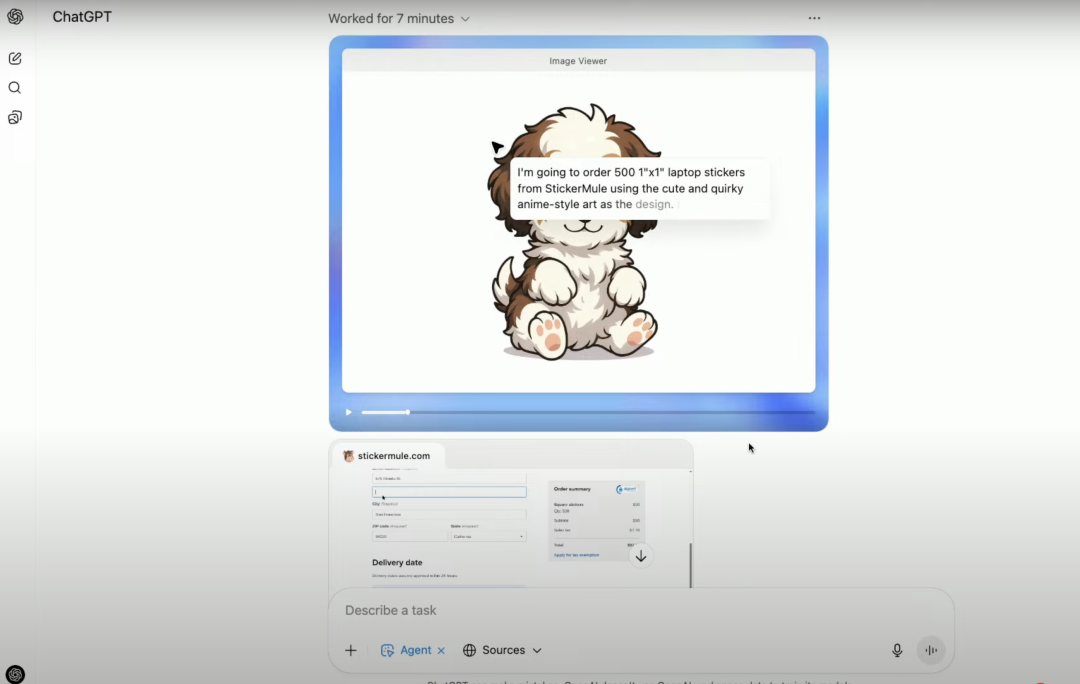
• 场景:实现从创意到实物的快速转化
演示中,用户上传了一张团队吉祥物的图片,要求Agent设计成贴纸并下单。Agent首先调用内置的图像生成模型,将吉祥物图转化为专业贴纸设计稿;随后,它自动访问一个在线定制网站,上传设计、选择规格、填写订购数量,并将最终的购物车页面呈现给用户,等待用户接管并完成支付。这个场景完美诠释了Agent打通数字创意与物理世界的能力。
性能评估:数据揭示的硬实力
为了证明这并非只是一个花哨的演示,OpenAI公布了一系列令人印象深刻的基准测试数据,量化了ChatGPT Agent的能力边界。
-
• 跨领域专家级难题 (HLE):在此测试中,Agent获得了41.6%的pass@1得分,创下新纪录,展现了其强大的综合解题能力。 -
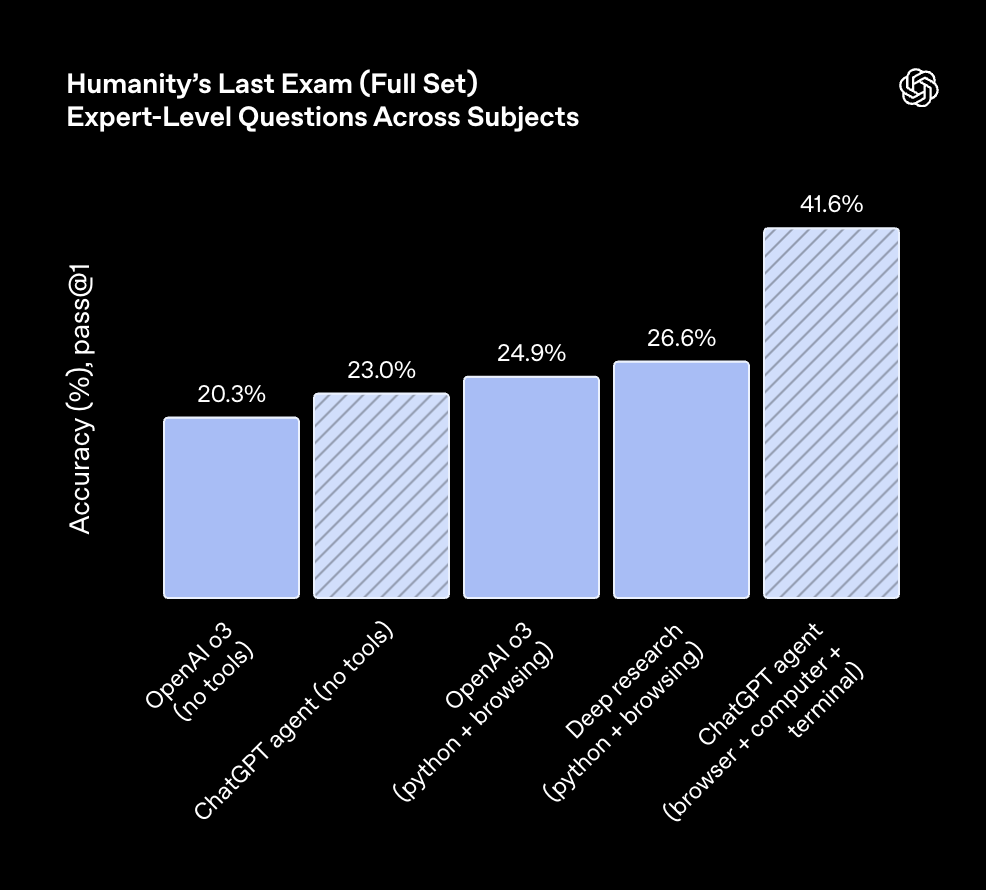
图注:HLE测试显示,配备完整工具的Agent性能远超前代模型。 -
• 数据科学任务 (DSBench):在数据分析和建模任务上,Agent的表现(89.9%和85.5%)显著超越了受过训练的人类专家。 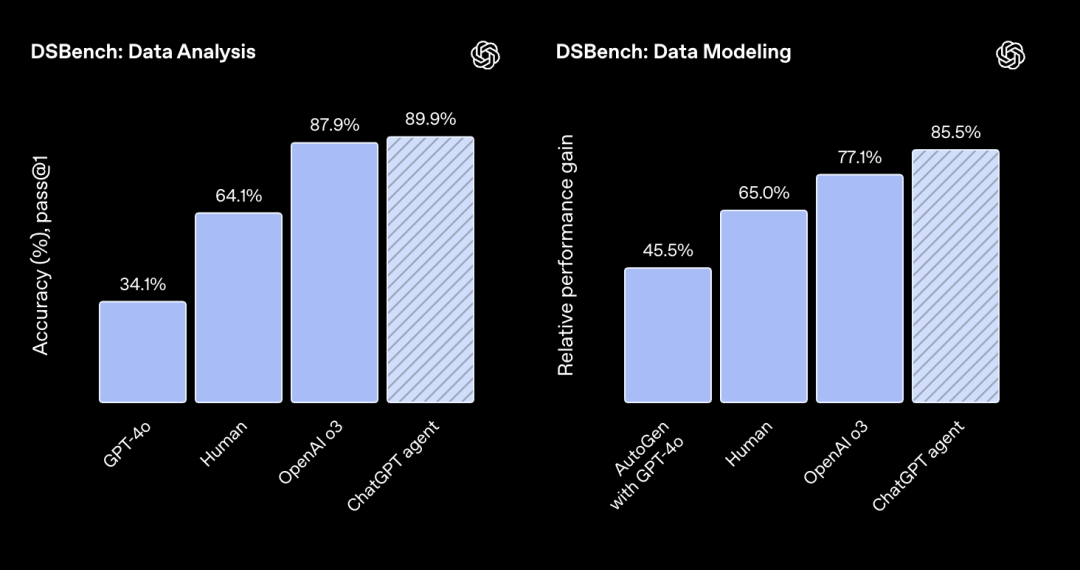
-
图注:DSBench测试显示Agent在数据科学任务上超越人类。 -
• 电子表格处理 (SpreadsheetBench):Agent直接编辑电子表格的能力得分高达45.5%,是同类主流办公软件中AI助手的两倍以上。 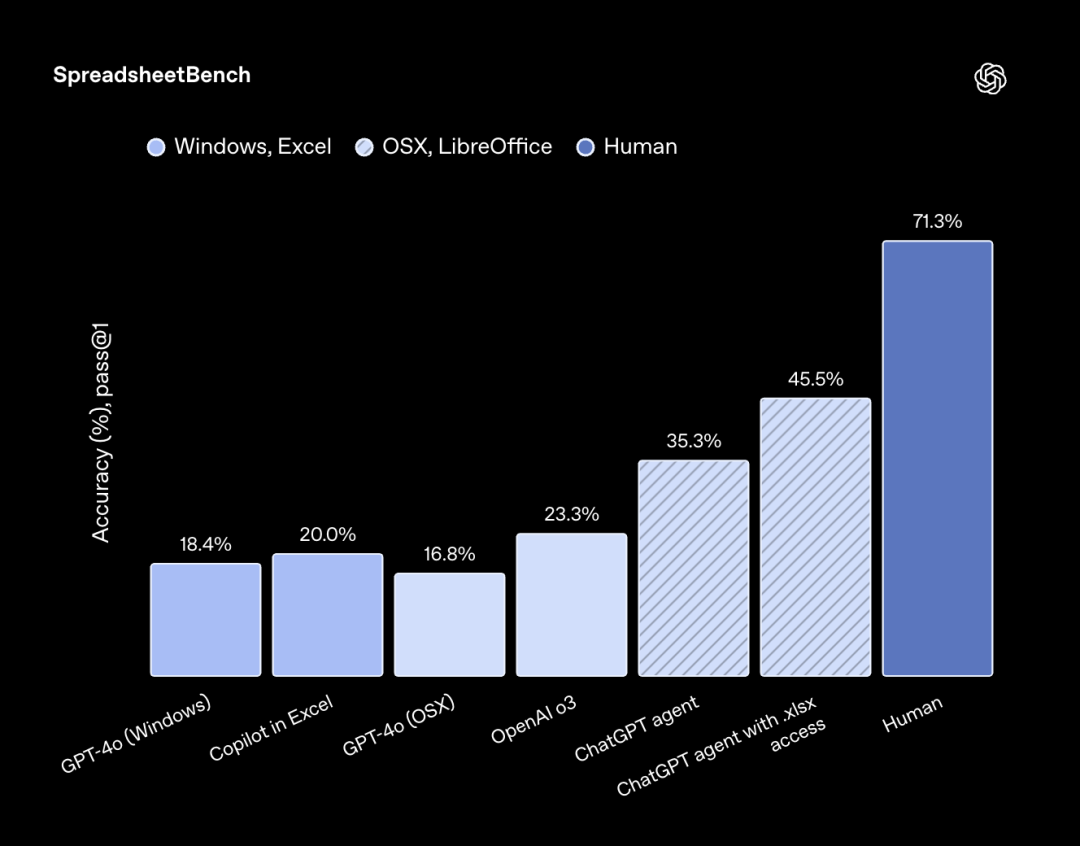
图注:Agent在电子表格处理能力上大幅领先同类产品。
这些数据共同指向一个结论:ChatGPT Agent在推理、工具使用和执行现实世界任务方面,已经达到了一个前所未有的高度。
前路漫漫:机遇背后的现实挑战
尽管Agent的能力令人振奋,但通往广泛应用的道路上,依然布满了现实的挑战。这些挑战不仅关乎技术本身,更关乎它如何与复杂的世界相处。
“98%正确率”的悖论与验证困境
技术社区最核心的关切,在于“98%正确率”的悖论。一个“几乎正确”的复杂产出,例如一份财报或一段核心代码,其隐藏的2%错误可能带来灾难性后果。而找出这些细微错误所需的验证成本,有时甚至会超过从零开始的成本。这引出了一个广为接受的比喻:ChatGPT Agent如同一个“需要严格监督的超级实习生”。它能极大地提升效率,但其产出必须经过专业人士的最终审核,因为它缺乏真正的理解和常识。
真实世界的摩擦力:从商业壁垒到人性复杂
Agent面临的另一重挑战是“真实世界的摩擦力”。
-
• 商业壁垒:许多主流网站正在积极封锁来自云端数据中心的自动化访问流量,以保护自身商业利益。这意味着Agent在购物、招聘等关键场景的应用将受到极大限制。 -
• “最后一公里”难题:与自动驾驶技术类似,Agent在处理需要100%精确或涉及复杂人类情感的任务时,也面临着“最后一公里”的难题。生活中许多困难的任务,其核心并非操作,而是深刻的个人价值观和复杂的人际关系,这些是AI目前难以企及的。
未来协作模式:“人机在环”的指挥与审查
这些挑战共同指向一个清晰的未来图景:我们并非走向完全自主的AI,而是一个“人机在-环” (Human-in-the-loop) 的深度协作时代。在这个模式中,人类的角色将从执行者转变为“指挥官”与“审查官”。我们负责设定目标、提供关键知识,并对Agent的产出进行最终的审核与确认,而AI则作为我们强大的执行臂膀。
结语:一场谨慎而宏大的开端
ChatGPT Agent的发布,无疑是AI发展史上的一个重要里程碑。它清晰地展示了AI从“思考”迈向“行动”的巨大潜力。
正如Sam Altman在发布会结尾所强调的:“这是一个全新水平的AI能力,一种全新的AI使用方式。但随之而来的,也会有全新的风险。社会和技术都需要不断进化和学习如何去缓解那些我们甚至还无法想象的问题。”
因此,OpenAI选择了谨慎的发布策略,并希望用户能像对待一项全新的技术那样,保持必要的审慎。对于我们每个人和每个组织而言,面对这场“不完美”的革命,最重要的是开始学习一套全新的工作方法。未来的核心竞争力,将不仅仅是创造,更在于如何高效、安全地驾驭、验证、并与这些强大但存在缺陷的AI工具协同工作。
革命已经开始,但路途依然漫长。
(文:子非AI)