

今天是2025年7月4日,星期五,北京,晴
我们继续来看数据合成的话题,之前在《大模型微调数据生成工具Easy Dataset及KBLaM知识注入框架评析》(https://mp.weixin.qq.com/s/0PUMbuiyXPUIXunMuH-otw)中有介绍过,Easy Dataset(https://github.com/ConardLi/easy-dataset)
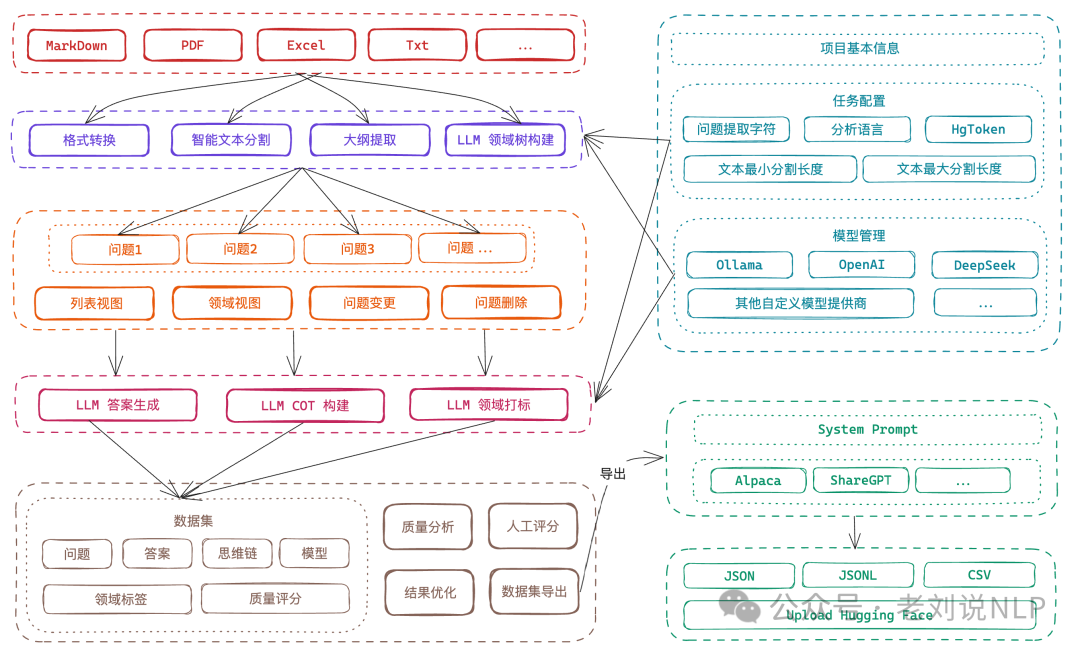
为大模型微调数据集而设计的项目,提供了直观的界面,用于上传特定领域的文件,智能分割内容,生成问题,并为模型微调生成高质量的训练数据。社区成员有测试过,还不错,具体说明说明文档在:https://rncg5jvpme.feishu.cn/docx/IRuad1eUIo8qLoxxwAGcZvqJnDb?302from=wiki。
陆陆续续的数据合成工具也越来越多,也更为体系化,支持的任务也越来越多,看一个更为系统化的项目,DataFlow(https://github.com/OpenDCAI/DataFlow),做个记录。
另外,继续看文档解析这个场景上,看看自然场景的文档解析评估,有一个评估数据集,也有一个评估结论。
一、大模型训练多任务数据合成项目DataFlow
大模型数据工程进展,DataFlow,支持多种数据源(PDF、文本、低质量问答)的解析与处理,DataFlow: A Data-centric AI system for data preparation and training,https://github.com/OpenDCAI/DataFlow,感兴趣的可以关注,这是数据合成方面的工具,说明文档在https://opendcai.github.io/DataFlow-Doc/zh/guide/。
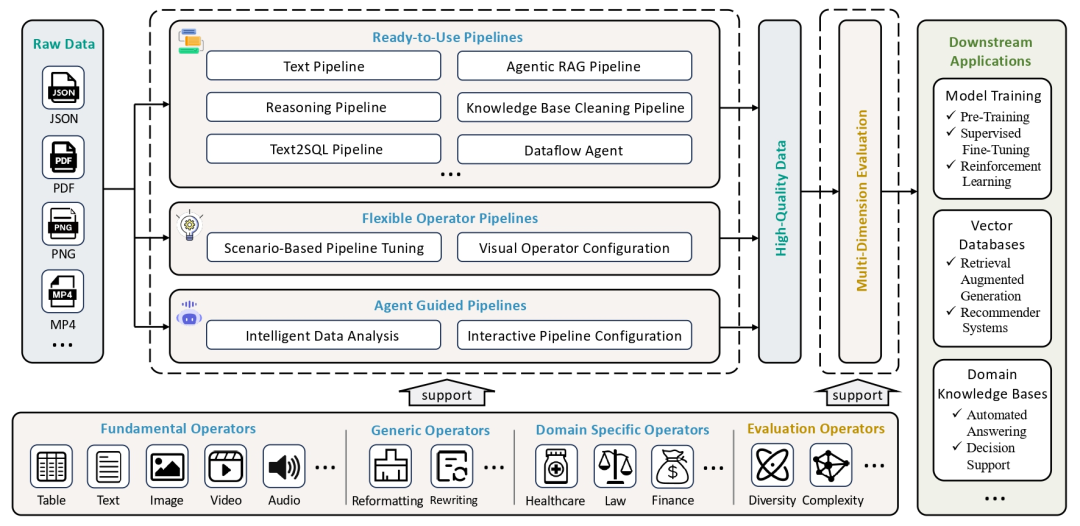
1、有哪些功能?
支持的任务包括纯文本训练合成、强推理数据合成、Text-to-SQL数据合成、Agentic RAG数据合成流程等。
其中:
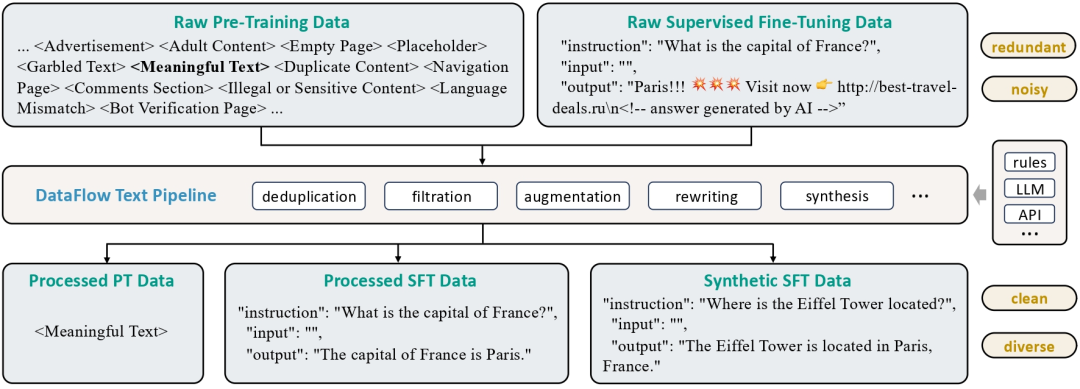
1)纯文本数据处理不同格式的文本信息,包括预训练文本和指令微调格式文本。从大规模纯文本(多为网络爬取)中挖掘问答对,用于监督微调和强化学习训练。
2)强推理数据合成的核心目标是通过数学问答数据的合成与处理,扩展现有数据集的规模和多样性,增强已有问答对,添加 长链式推理(Chain-of-Thought)、 类别标注、难度估计。
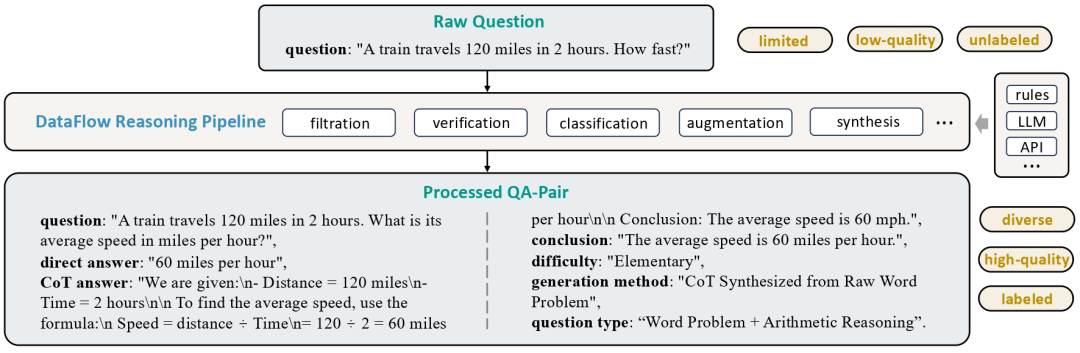
具体的:问题处理:过滤非数学问题、合成新问题、验证问题正确性、进行难度评分和类别分类;答案生成与处理:根据问题的标准答案或模型生成的答案进行处理,包括格式过滤、长度过滤和正确性验证等;数据去重:对生成的问答数据进行去重,确保数据集的质量。
3)Text-to-SQL数据合成,通过清洗和扩充现有的Text-to-SQL数据,为每个样本生成包含训练提示词(prompt)和长链推理过程(chain-of-thought)的高质量问答数据,将自然语言问题转化为 SQL 查询,辅以解释、思维链推理和数据库结构上下文信息。
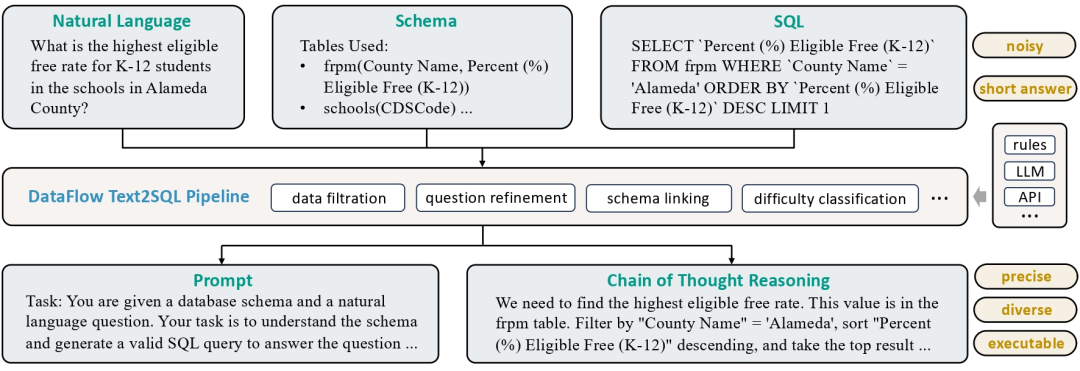
4)Agentic RAG ,端到端的框架,基于强化学习的 Agentic RAG 训练。从提供的文本内容中生成高质量的问题和答案对。
2、如何评估有效性
其实,更为重要的还是如何验证这类工具的有效性问题,最好的方式就是消融实验,例如:
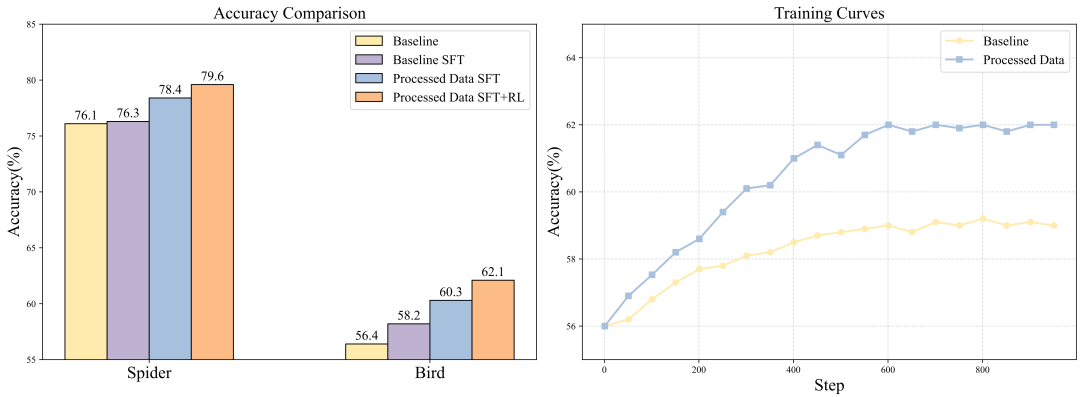
Bird数据集上使用DataFlow-Text2SQL流程构建数据,并分别通过监督微调(SFT)与强化学习(RL)对Qwen2.5-Coder-14B模型进进行训练,然后看效果:
二、自然场景的文档解析评估问题
现在多模态大模型做文档解析的工作越来越多,我们已经做个多个介绍,但其更多的还是针对标准印刷体文档。对于拍照版本的,其实从layout以及解析等任务看,都会存在一些问题,例如下面这个图。

在未矫正前,直接进行布局检测,会发生错乱。
所以,这自然会出来一个问题,就是评估自然环境下文档理解能力,现有的DocVQA和ChartQA 等主流基准测试主要涵盖扫描文档或者印刷文档,无法充分反映现实世界中各种场景(例如光照变化和物理变形)所带来的复杂挑战。

那么,怎么评估?关键还是这个评估数据怎么做?
可看最近的一个工作《WildDoc: How Far Are We from Achieving Comprehensive and Robust Document Understanding in the Wild?》,https://arxiv.org/pdf/2505.11015,对应的地址在:https://bytedance.github.io/WildDoc/,https://huggingface.co/datasets/ByteDance/WildDoc,https://github.com/bytedance/WildDoc,https://bytedance.github.io/WildDoc/#leaderboard,https://bytedance.github.io/WildDoc/#examples
论文理论本身价值不大,重点还是这份数据。
1、具体如何实现?
在具体实现上,靠虑到日常生活中遇到的各种场景,选择了五个关键因素:环境、照明、视图、失真、效果。

2、实际效果如何?
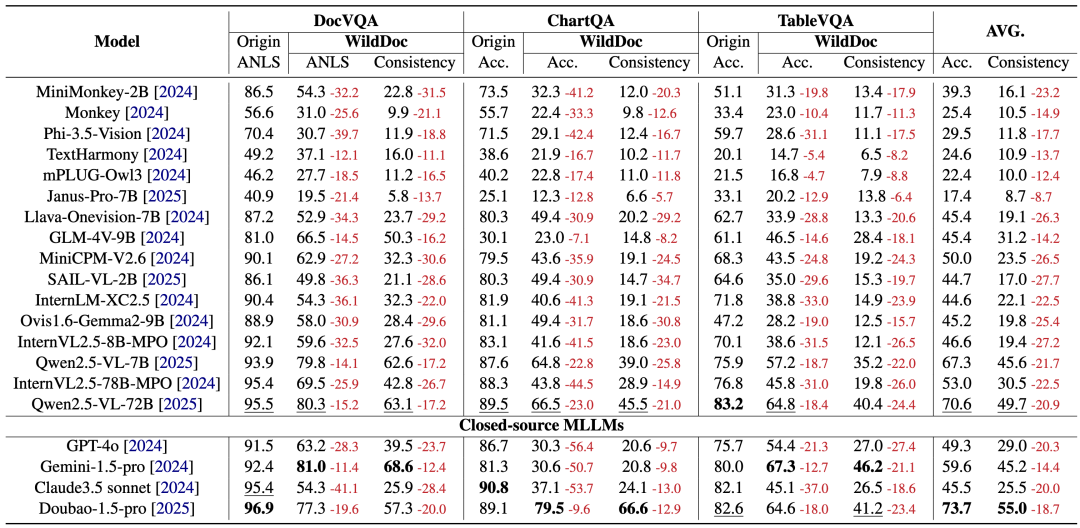
结果表明,当面对常见的现实世界扭曲(例如皱纹、弯曲和折痕)影响的文档时,MLLM 的性能会显著下降,具体的指标变化,如下图所示:
其实这是个很有趣的话题,是先矫正,图像增强,然后变成标准文档解析,还是直接让 vllm 做处理,都是值得探索的方向。
参考文献
1、https://github.com/OpenDCAI/DataFlow
2、https://arxiv.org/pdf/2505.11015
(文:老刘说NLP)