


团队由 IEEE 会士,纽约大学教授 Claudio Silva 和纽约大学研究助理教授钱靖共同指导。 论文由Chenyi Li和Guande Wu共同第一作者。
在无数科幻电影中,增强现实(AR)通过在人们的眼前叠加动画、文字、图形等可视化信息,让人获得适时的、超越自身感知能力的信息。无论是手术医生带着 AR 眼镜进行操作,还是智能工厂流水线前的例行检查、或是面对书本时 AR 快速查找翻阅的超能力,是这一切只为一个最终目的——通过适时的信息辅助我们。

直到今日,大部分 AR 辅助依然停留在需要人工远程接入辅助的层面,与我们期待的智能的、理解性的、可拓展的 AR 辅助相差甚远。这也导致 AR 在重要产业和生活应用中的普及受到限制。如何能让 AR 在生活中真正做到理解用户、理解环境、并适时的辅助依然面临巨大挑战。

Satori 系统自动识别用户称重 11 g 咖啡的展示
这一切随着 Satori 系统的诞生即将成为过去。来自纽约大学数据与可视化实验室(NYU VIDA)联合 Adobe 的研究人员融合多模态大语言模型(MLLM)与认知理论 BDI(Belief-desire-intention theory)让 AI 首次真正意义的去理解使用者的行为、目标以及环境状态,最终达到根据不同场景自动适配指示内容,指示步骤,与判断辅助时机。让 AR 辅助接入智慧核心,向泛化应用、智能交互迈进了里程碑的一步。

-
论文标题:Satori: Towards Proactive AR Assistant with Belief-Desire-Intention User Modeling
-
论文链接:https://arxiv.org/abs/2410.16668v2
-
Github:https://github.com/VIDA-NYU/satori-assistance
Satori 创新介绍
创新点一:结合 BDI 模型让 AI 理解用户行为和场景关系
通过 AR 眼镜让 AI 拥有跟用户共同视角的「具身感知」,成功的让 AI 通过认知模型 BDI 理解用户的动作行为及其短期目的。BDI 把人的行为分解成对周围世界的理解(Belief),对总体目标的判断(Desire),和为达目标进行的动作行为(Intention)三个部分。
本质上,BDI 强调人是主动性体(agentive being),做出的行为是基于对环境的理解和内部目标的组合,因此我们使用 AI 以多模态数据的模拟人接受信息和应对目标的方式,适合短期以行为目标为主的的 AR 辅助。
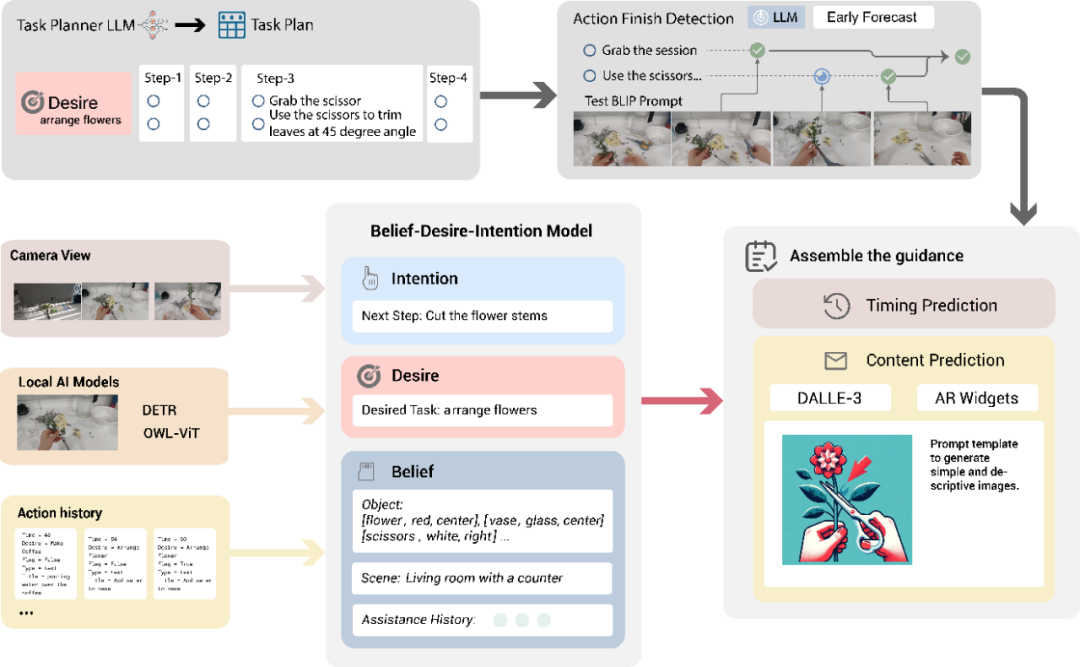
这使得 AR 眼镜可以通过 AI 加持实时判断用户行为背后的目的,不再是单纯的对于行为本身的判断。
创新点二:大语言模型结构认知
Satori 系统以模块化组织 MLLM,将图像识别、语义理解、用户交互历史上下文解耦处理,并统一纳入 BDI 认知架构中。通过将视觉感知模块(如 OWL-ViT 与 DETR)与语言推理模块(MLLM)分层协作,系统能够从用户的行为动态构建 Belief 状态、识别任务目标,推理出即时意图。
该模块化结构不仅增强了推理透明度与可解释性,还显著提升了系统的泛化性与跨任务适配能力,展示了多模态大模型在具身智能中的结构认知潜力。

自动生成带有动作和箭头方向的指示图片
创新点三:AI 自动生成多模态指示
在辅助过程中,AI 生成了适时的、应景的、易理解的图片以及文字。在图像层面,Satori 使用 DALLE-3 与场景感知(Belief)模块自动生成与当前任务阶段精准匹配的视觉提示(如剪刀与花的动作关系,与花瓶的空间位置关系),给用户直接的视觉指引、减少语义误解。
这项技术同时也用在了文字生成中,在基础文本上追加对场景物体,用户交互关系的描述(如「把花插入花瓶」变为「把花插入蓝色花瓶」)。此创新让 AI 更具备操作引导的即时性与可视化表达能力,大幅提升了 AR 辅助的清晰度与实用性。


创新点四:双系统动作完成检测方法减少用户等待时间,增加提示准确率
AR 辅助中一大挑战在于任务的复杂度影响了 AI 判断成功率和速度。步骤越复杂、动作越多,AI 一次性判断的噪音和不确定性越大。因此,Satori 团队创新地将每个步骤分成多个更明确,易判断的小目标(checkpoints),来完成对总体步骤的确认。例如:「剪花」任务中的「剪掉枯叶」步骤,会有「拿剪刀」,「对准枯叶」,和「完成剪切」三个小目标,系统判断这些是否完成后便可触发下一提示。
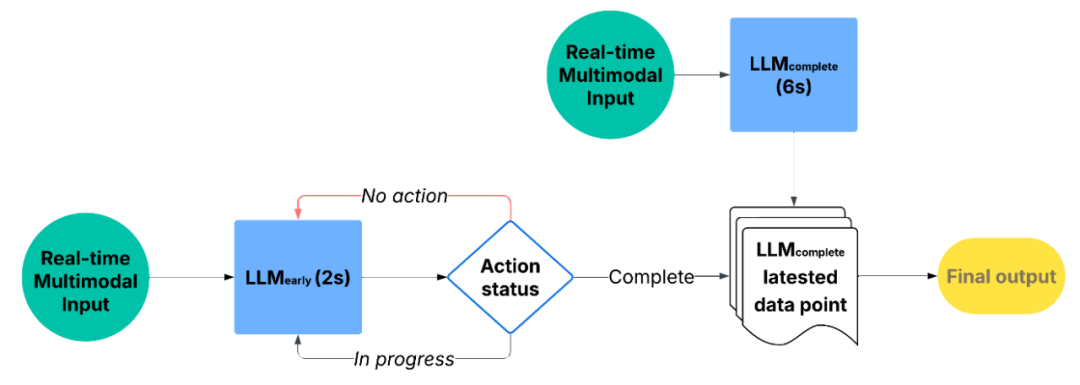
Satori 使用双系统理论(Dual Process Theory)将 AI 的反馈分为「快速反应+理性结构」。动作识别由一个轻量 LLM 完成快速行为完成判断,以高容量 LLM 补充结构性语义分析,通过交互设计机制将二者节奏对齐,确保系统既具响应性,又具智能表达力。

团队所提出的模块化多模态推理框架,不仅在技术层面上展示出对 AR 交互场景的高度适配性,更为未来跨平台、多领域的智能辅助系统奠定了方法论基础。系统核心可灵活部署于 HoloLens、Vision Pro、或者轻量级智能眼镜如 Rokid、INMO、雷鸟、和 Nreal 等不同硬件平台。

在 AI 与大语言模型快速发展的今天,无疑是 AR 技术迈向实用性的一次新的机遇。无论你是 AI、AR 的爱好者,或者是在学界,工业界的专业人士,都欢迎关注 AR 辅助这个正在觉醒的未来。
©
(文:机器之心)