

今天是2025年02月11日,星期 二,北京,天气阴。
今天我们来看看R1和知识图谱结合的一个粗暴结合,其实现方式,有种为了做RL而做RL的直蹭之嫌,从源码角度看具体实现。
另一个是回顾昨日社区技术进展早报,围绕强化学习R1用于知识图谱信息抽取、推理大模型四种习得范式,RAG-webui,RAG和deepseek部署加速。GraphRAG还是有一些推进。
专题化,体系化,会有更多深度思考。大家一起加油。
一、R1范式用在知识图谱抽取的粗暴实现
我们先看R1和知识图谱结合,open-r1-text2graph:开源复现DeepSeek R1的文本到图谱抽取训练方案。十分粗暴,且不完整。不建议去复制,。
基于GRPO强化学习,提升模型对结构化信息的提取能力;提供完整的数据生成、监督训练到强化学习的: https://github.com/Ingvarstep/open-r1-text2graph,https://huggingface.co/blog/Ihor/replicating-deepseek-r1-for-information-extraction
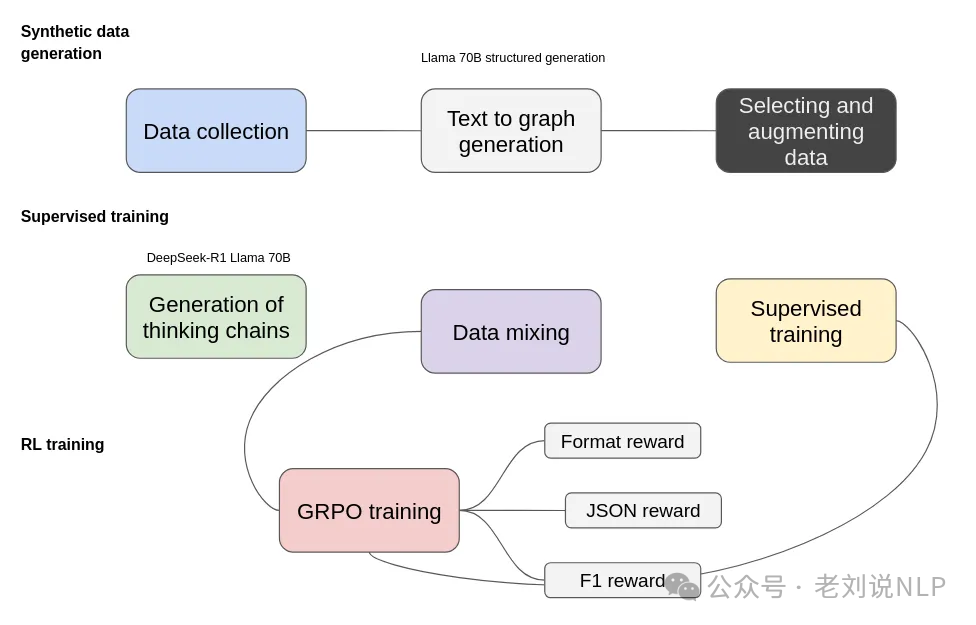
原图画的有错误,如下:
正确的应该是:
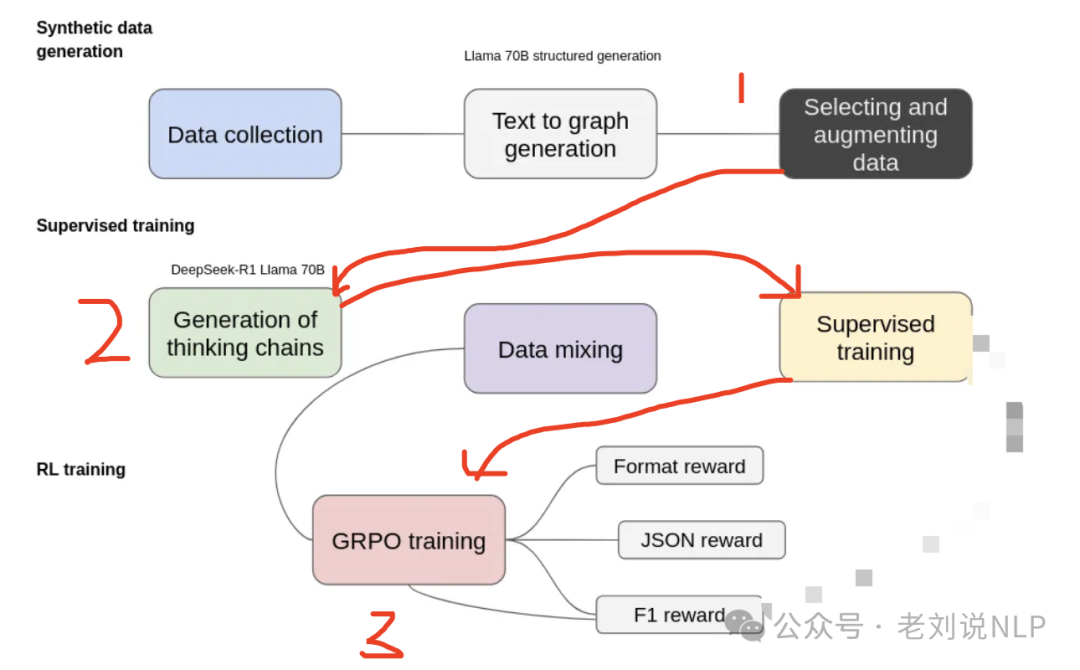
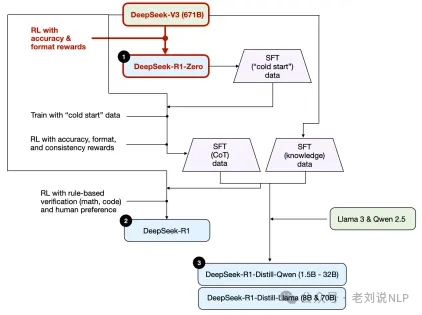
期训练过程包括三个主要阶段:合成数据生成、监督训练和强化学习(RL)训练。
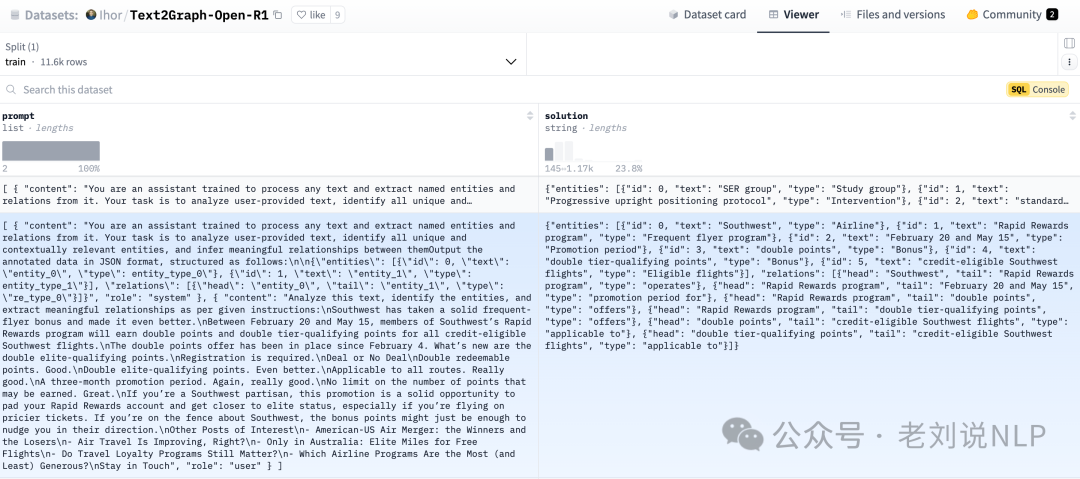
在合成数据生成阶段,从数据收集开始,收集与目标领域相关的多样化文本来源,通过Llama 70B将非结构化文本转换为基于图的表示形式,也就是进行抽取,形成如下形式:
{ "entities": [ { "id": 0, "text": "Microsoft", "type": "company" }, { "id": 1, "text": "Satya Nadella", "type": "person" }, { "id": 2, "text": "Azure AI", "type": "product", } ], "relations": [ { "head": "Satya Nadella", "tail": "Microsoft", "type": "CEO of" }, { "head": "Microsoft", "tail": "Azure AI", "type": "developed" } ] }
然后,进行思维链数据合成,将生成的结构化预测JSON数据以及文本输入到DeepSeek-R1 Llama 70B中,以生成能够解释提取过程的思维链,这里用到的数据在:https://huggingface.co/datasets/Ihor/Text2Graph-Open-R1

但是思维链数据并未开放,合成数据prompt 如下,在:https://github.com/Ingvarstep/open-r1-text2graph/blob/main/src/generate.py
在监督训练阶段,在开始强化学习之前,考虑到使用的是小型模型,需要额外的监督训练来确保模型能够以正确的格式返回数据。为此,仅使用了1000个样例进行微调。
微调的代码在:https://github.com/Ingvarstep/open-r1-text2graph/blob/main/src/train_supervised.py
在强化训练阶段。采用基于群体相对策略优化(GRPO)的强化学习,几个reward的曲线十分波动。
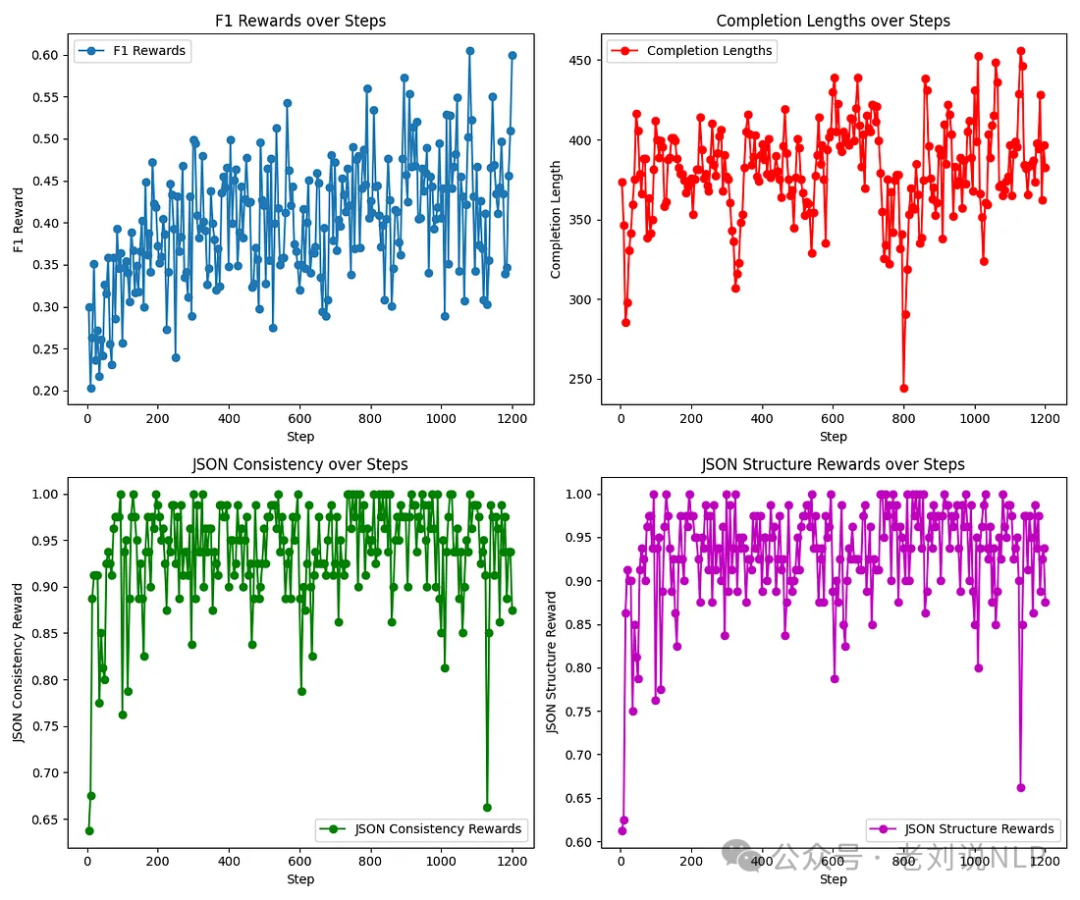
其中设计到两个奖励函数,即:格式奖励、JSON奖励、F1奖励。奖励函数赋予了不同的系数,优先考虑F1奖励。
格式奖励:确保输出遵循结构化格式,其中思维过程被封装在相应的标签中(在启用思维模式的情况下)。

JSON奖励:专门验证格式良好且机器可读的JSON表示,并确保其结构符合期望的格式。
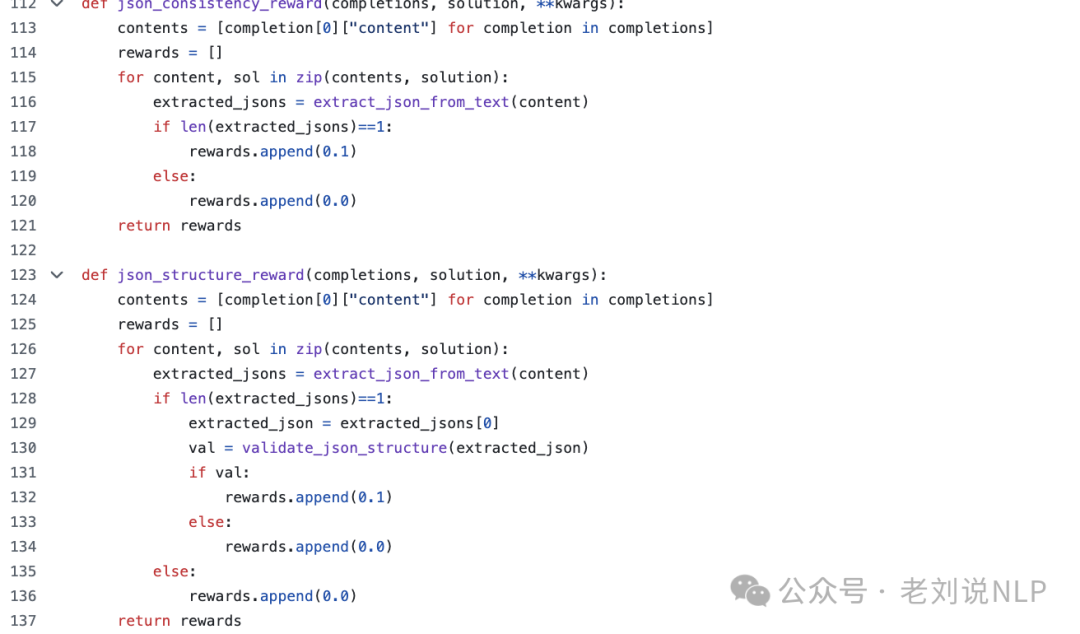
F1奖励:通过与真实图进行比较,评估提取的实体和关系的准确性。
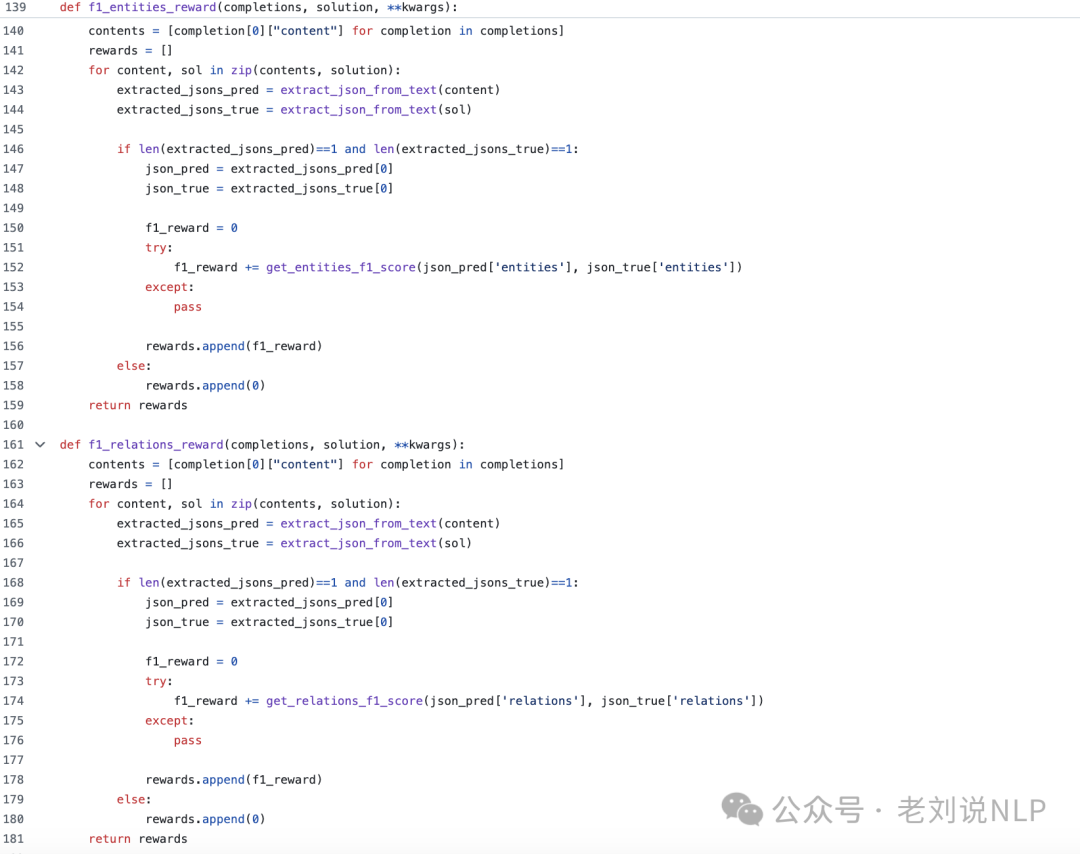
坦白讲,这个工作水的嫌疑很大,简单粗暴,对于知识图谱这种任务,其实直接sft,就已经能够解决很多问题。
模型也已经出来了的,放在https://huggingface.co/Ihor/Text2Graph-R1-Qwen2.5-0.5b,体验了下,效果不是很好。
二、技术社区昨日相关进展回顾
我们来看昨日进展早报,围绕强化学习R1用于知识图谱信息抽取、推理大模型四种习得范式,RAG webui,RAG和deepseek部署加速等话题。

1、RAG进展,Agentic Reasoning: Reasoning LLMs with Tools for the Deep Research,用知识图谱组织推理逻辑,并结合推理大模型用在深度搜索研究上的一个思路,https://arxiv.org/pdf/2502.04644,
Agentic Reasoning框架中引入了Mind Map代理,构建结构化的知识图以跟踪逻辑关系,提高演绎推理能力。

模型在推理过程中动态地与外部工具交互,检索结构化记忆,并生成逻辑推理链和最终答案。
Mind Map代理构建Mind Map以存储和结构化推理模型的实时推理上下文。Mind Map通过将原始推理链转换为结构化知识图来实现,帮助模型更好地组织和理解复杂的逻辑关系。
网络搜索代理调用网络搜索代理从互联网检索相关信息,并将其整合到推理链中,确保信息的相干性和相关性,项目地址在:https://github.com/theworldofagents/Agentic-Reasoning
2、RAG进展,一个webui,RAG Web UI:基于RAG技术的智能对话系统,快速构建基于私有知识库的智能问答服务,可使用 OpenAI、DeepSeek 等云端服务,也支持通过 Ollama 部署本地模型。支持多种文档格式(PDF、DOCX、Markdown等)和异步处理,提升效率: https://github.com/rag-web-ui/rag-web-ui

整体架构不错,可以用用看。
3、推理框架进展,KTransformers框架,在24GB显存+382G内存环境下运行DeepseekR1和V3的效果,实现最高3至28倍的加速效果(相对于llama.cpp)。运行Q4_K_M量化版本,最低仅需14GB显存和382GB内存。https://github.com/kvcache-ai/ktransformers

-
4、R1和知识图谱结合,open-r1-text2graph:开源复现DeepSeek R1的文本到图谱抽取训练方案。基于GRPO强化学习,提升模型对结构化信息的提取能力。提供完整的数据生成、监督训练到强化学习的
-
https://github.com/Ingvarstep/open-r1-text2graph
5、再看增强大模型推理能力的四种范式及蒸馏微调范式具体实现,https://mp.weixin.qq.com/s/EKbzBx6z0xUSyDOs5QPZ8g
总结
本文主要介绍了R1和知识图谱结合的一个粗暴结合,并围绕强化学习R1用于知识图谱信息抽取、推理大模型四种习得范式,RAG webui,RAG和deepseek部署加速方面进行了回顾。
目前大家都在尝试与 deepseek R1的结合,也陆续出来了一些有趣的工作,我们支持跟进。
但还是如此,我们需要做自己之前做的事儿。
参考文献
1、https://github.com/Ingvarstep/open-r1-text2graph
(文:老刘说NLP)