

# 角色你是一个xx专家# 描述# 技能## 技能1: xxx## 技能2: xxx# 限制条件# 输出格式# 工作流程# 示例(few-shot)
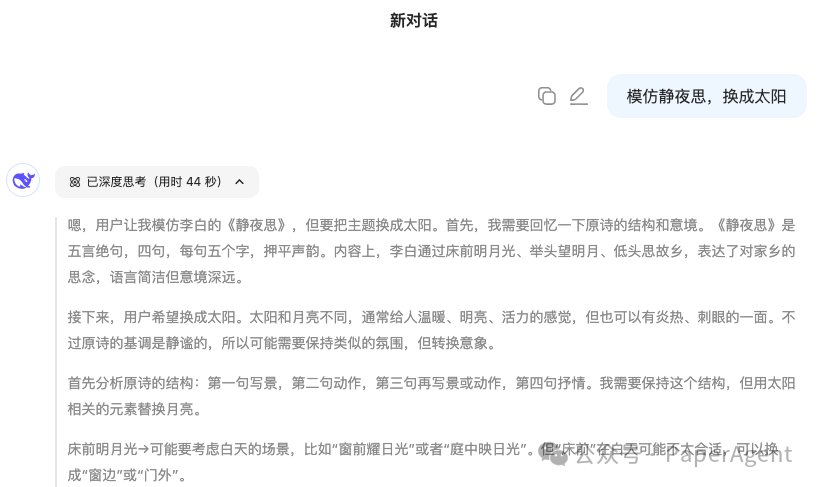

-
提示工程:
-
使用清晰、简洁且无歧义的提示。
-
避免对DeepSeek-R1使用few-shot提示,因为这已被证明会在复杂任务中降低性能。相反,使用zero-shot或结构化提示。
-
输出格式化:
-
指定输出要求,例如结构化格式(JSON、表格或markdown),以便于阅读和集成到下游系统中。
-
对于需要推理的任务,包括逐步解释的指令,以确保透明度和可解释性。
-
语言一致性:明确指定输入和输出所需的语言,以防止语言混合,这是DeepSeek-R1的一个已知问题
同时,也给出了DeepSeek-R1全面的部署建议,尽量减少潜在有害输出的风险:
监控与安全机制
-
设置护栏和内容过滤:实施护栏和后处理过滤器,从模型的响应中移除潜在有害内容,
-
人工监督:在工作流程中加入人工监督,以监控和审查模型的输出,特别是在安全关键的应用中。
-
定期审计输出:定期审查模型的输出,以确保其符合组织的安全标准和道德准则。
部署中的风险缓解
-
避免高风险场景:
-
不要在输出错误可能导致重大伤害的应用中部署DeepSeek-R1(例如,在医疗或金融系统中的自主决策),
-
此外,由于观察到的语言不一致、有害行为和多轮性能退化问题,DeepSeek-R1不适合用于Agentic AI部署,这可能会在高风险环境中加剧风险。
-
针对敏感应用进行定制:在敏感领域(例如法律、医学)中,在微调和评估阶段纳入领域专家,以确保负责任地使用。
最后,如果确实要给DeepSeek-R1如何使用加一个规范,可参考文章
-
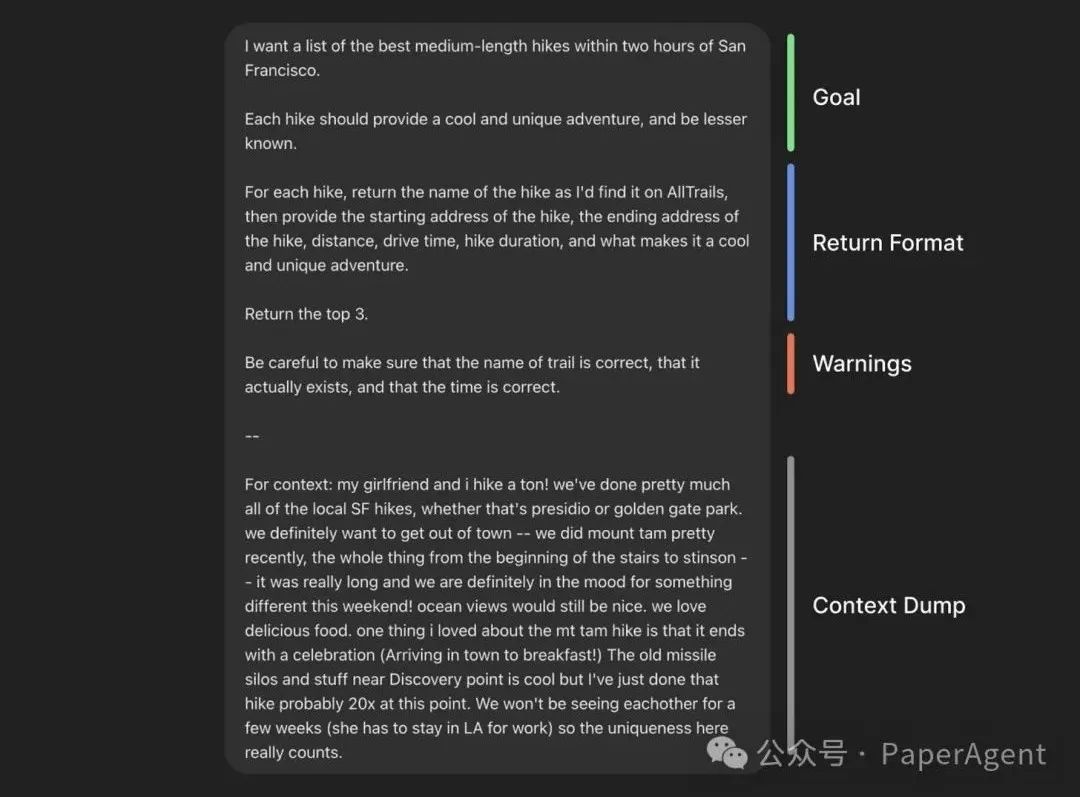
明确目标(Goal)
-
指定返回格式(Return Format) -
附加注意事项(Warnings) -
大量背景信息(Context Dump)
https://arxiv.org/pdf/2501.17030Challenges in Ensuring AI Safety in DeepSeek-R1 Models: The Shortcomings of Reinforcement Learning Strategies
(文:PaperAgent)