


新智元报道
新智元报道
【新智元导读】Ilya「预训练结束了」言论一出,圈内哗然。谷歌大佬Logan Klipatrick和LeCun站出来反对说:预训练还没结束!Scaling Law真的崩了吗?Epoch AI发布报告称,我们已经进入「小模型」周期,但下一代依然会更大。

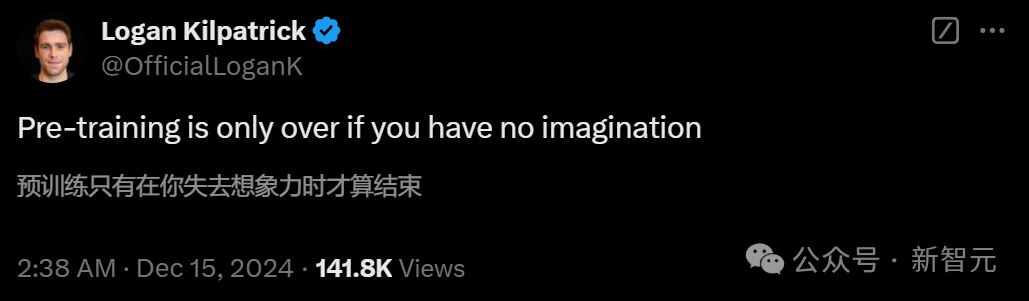
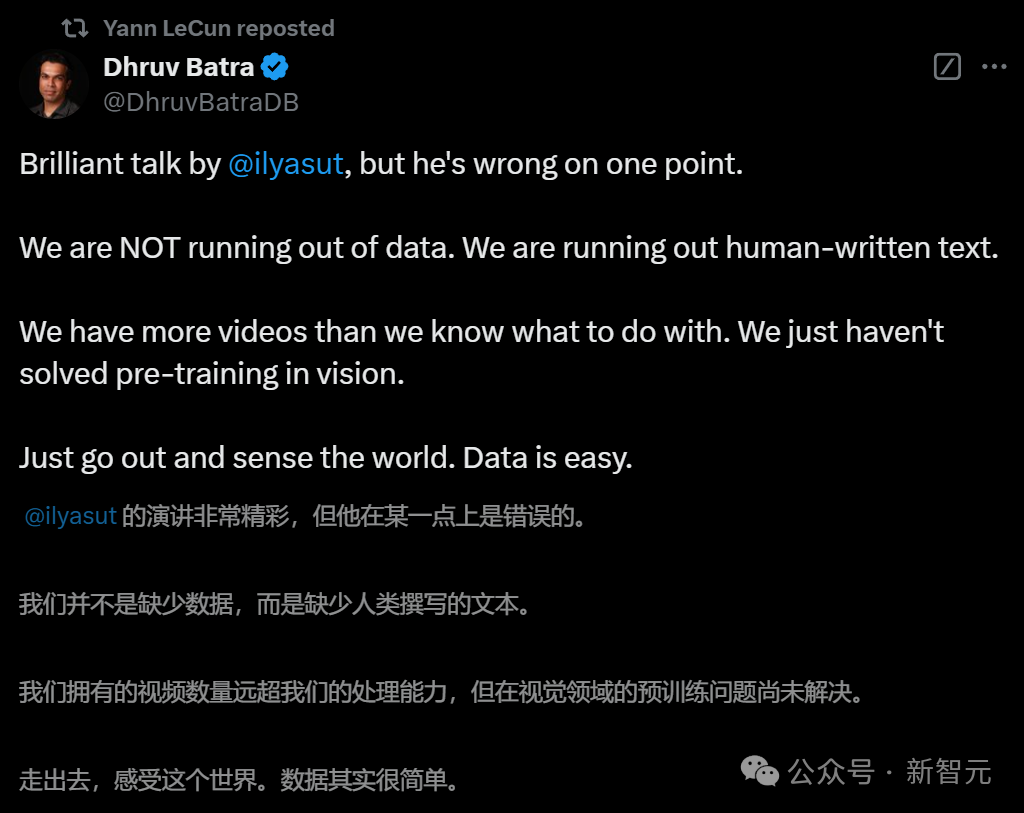
Scaling Law和预训练到底有没有撞墙?



-
从GPT-1到GPT-3,用了2年时间,模型参数量从1.17亿增加到1750亿,增加了1000倍
-
从GPT-3到GPT-4,用了2年9个月,模型参数量从1750亿增加到1.8万亿,增加了10倍
-
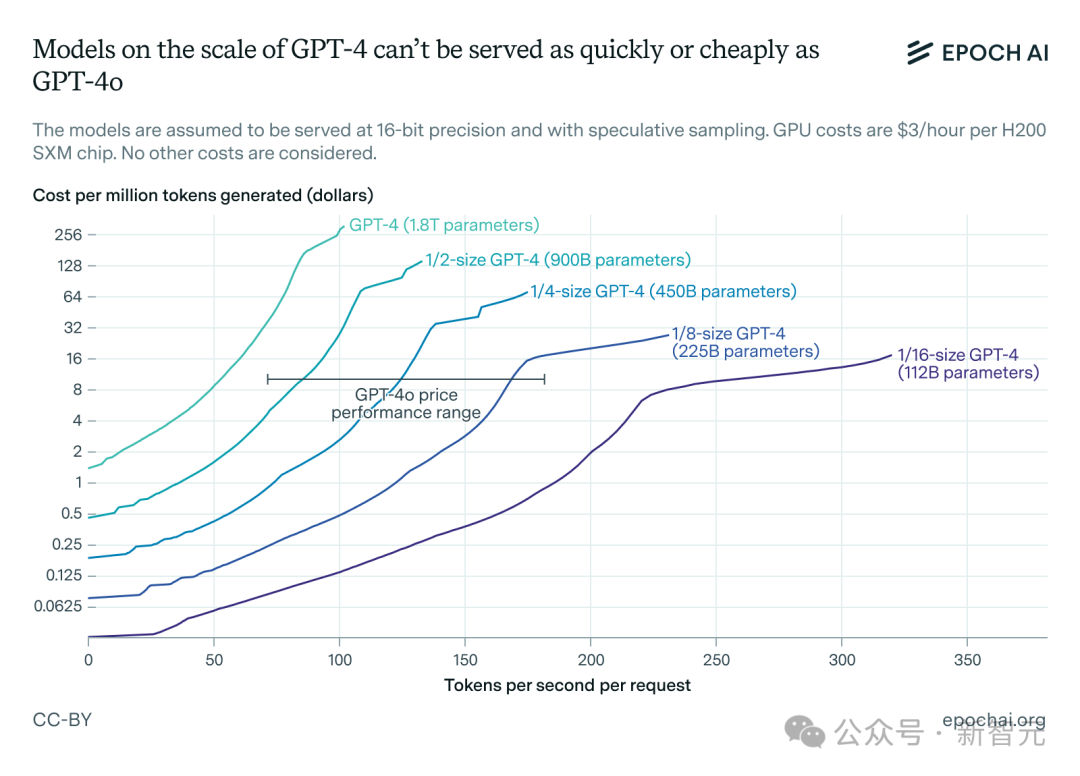
GPT-4o大约为2000亿参数 -
Claude 3.5 Sonnet约为4000亿参数

当今SOTA模型最大只有约4000亿参数
为什么会这样?
1. AI需求爆发,模型不得不瘦身
2. 蒸馏,让小模型更能打
3. Scaling Law的转变
4. 推理更快,模型更小
5. 用AI喂AI,成本更低
奥特曼:参数规模竞赛即将终结?

(文:新智元)