
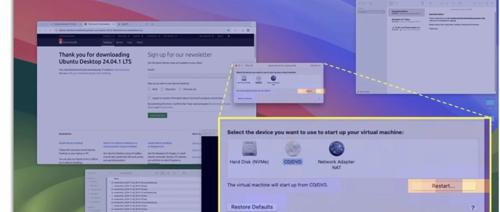
在AI驱动的图形用户界面(GUI)交互领域,视觉定位一直是核心挑战。
传统方法依赖生成具体坐标(如x=100, y=200)来定位界面元素,但这种方式在复杂场景下往往受限于分辨率变化、布局差异等问题。
最近微软在GitHub上开源了一款突破性的面向GUI Agent的无坐标视觉定位工具:GUI-Actor。
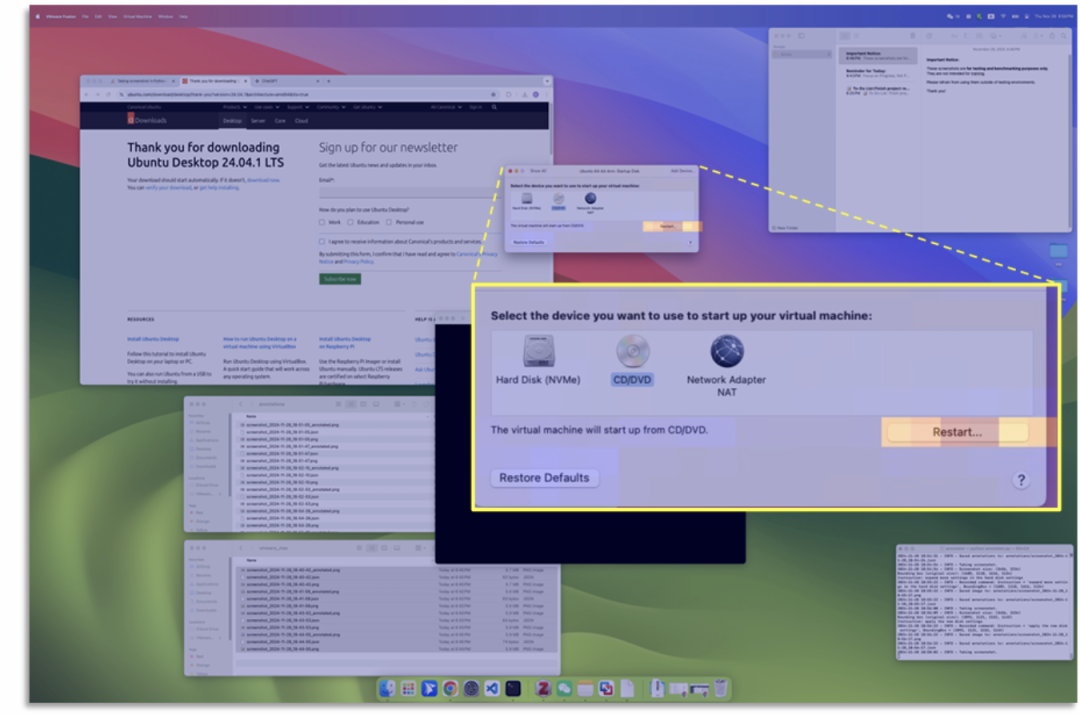
通过创新的无坐标视觉定位方法,彻底颠覆了传统GUI智能体的交互方式。基于Qwen2-VL/2.5-VL模型实现,使用注意力机制动作头,模拟人类直觉,直接定位界面元素,性能匹敌甚至超越传统方法。
它支持网页、桌面、移动端UI,输入截图+指令,输出目标区域。
主要功能
GUI-Actor通过引入注意力机制动作头和验证器,实现无坐标的视觉定位,直接对目标区域进行语义化识别,无需计算固定坐标。其核心优势包括:
-
• 无坐标定位:通过注意力机制,GUI-Actor直接锁定视觉区域,模拟人类直观交互行为。 -
• 多区域预测:支持生成多个候选交互区域,适应复杂场景。 -
• 验证器增强:内置验证器评估候选区域的准确性,提升定位可靠性。 -
• 跨分辨率泛化:对不同屏幕分辨率和UI布局表现出极强的适应性。 -
• 轻量级训练:GUI-Actor-LiteTrain模式仅微调动作头,即可达到与最先进方法相当的性能,同时保留VLM的通用能力。
安装与部署
克隆项目:
git clone https://github.com/microsoft/GUI-Actor.git
cd GUI-Actor创建一个conda环境并安装依赖项:
conda create -n gui_actor python=3.10
conda activate gui_actor
conda install pytorch torchvision torchaudio pytorch-cuda -c pytorch -c nvidia
pip install -e .模型训练:
# 热身阶段
bash scripts/warmup.sh
# 全参数训练阶段
bash scripts/train.sh示例用法:
import torch
from qwen_vl_utils import process_vision_info
from datasets import load_dataset
from transformers import AutoProcessor
from gui_actor.constants import chat_template
from gui_actor.modeling import Qwen2VLForConditionalGenerationWithPointer
from gui_actor.inference import inference
# load model
model_name_or_path = "microsoft/GUI-Actor-7B-Qwen2-VL"
data_processor = AutoProcessor.from_pretrained(model_name_or_path)
tokenizer = data_processor.tokenizer
model = Qwen2VLForConditionalGenerationWithPointer.from_pretrained(
model_name_or_path,
torch_dtype=torch.bfloat16,
device_map="cuda:0",
attn_implementation="flash_attention_2"
).eval()
# prepare example
dataset = load_dataset("rootsautomation/ScreenSpot")["test"]
example = dataset[0]
print(f"Intruction: {example['instruction']}")
print(f"ground-truth action region (x1, y1, x2, y2): {[round(i, 2) for i in example['bbox']]}")
conversation = [
{
"role": "system",
"content": [
{
"type": "text",
"text": "You are a GUI agent. You are given a task and a screenshot of the screen. You need to perform a series of pyautogui actions to complete the task.",
}
]
},
{
"role": "user",
"content": [
{
"type": "image",
"image": example["image"], # PIL.Image.Image or str to path
# "image_url": "https://xxxxx.png" or "https://xxxxx.jpg" or "file://xxxxx.png" or "data:image/png;base64,xxxxxxxx", will be split by "base64,"
},
{
"type": "text",
"text": example["instruction"]
},
],
},
]
# inference
pred = inference(conversation, model, tokenizer, data_processor, use_placeholder=True, topk=3)
px, py = pred["topk_points"][0]
print(f"Predicted click point: [{round(px, 4)}, {round(py, 4)}]")
# >> Model Response
# Intruction: close this window
# ground-truth action region (x1, y1, x2, y2): [0.9479, 0.1444, 0.9938, 0.2074]
# Predicted click point: [0.9709, 0.1548]应用场景示例
-
• GUI 智能体:“点击设置”、“关闭弹窗”等,无需坐标预测,更鲁棒。 -
• 软件测试自动化:跨分辨率、跨主题风格时 UI 定位更稳。 -
• 按键精灵助手:操作 HUD 元素、游戏菜单指令。
还可以与 MCP、LangGraph 等集成,与 Claude、GPT Agent 等配合使用,实现视觉-指令联动操作。
写在最后
GUI交互的痛点让人抓狂:坐标计算繁琐、分辨率适配难、泛化能力弱。
GUI-Actor 打破了 “用坐标操控界面” 的传统范式,让 VLM 直接理解“点哪里”,是 GUI Agent 操作新纪元的开端。
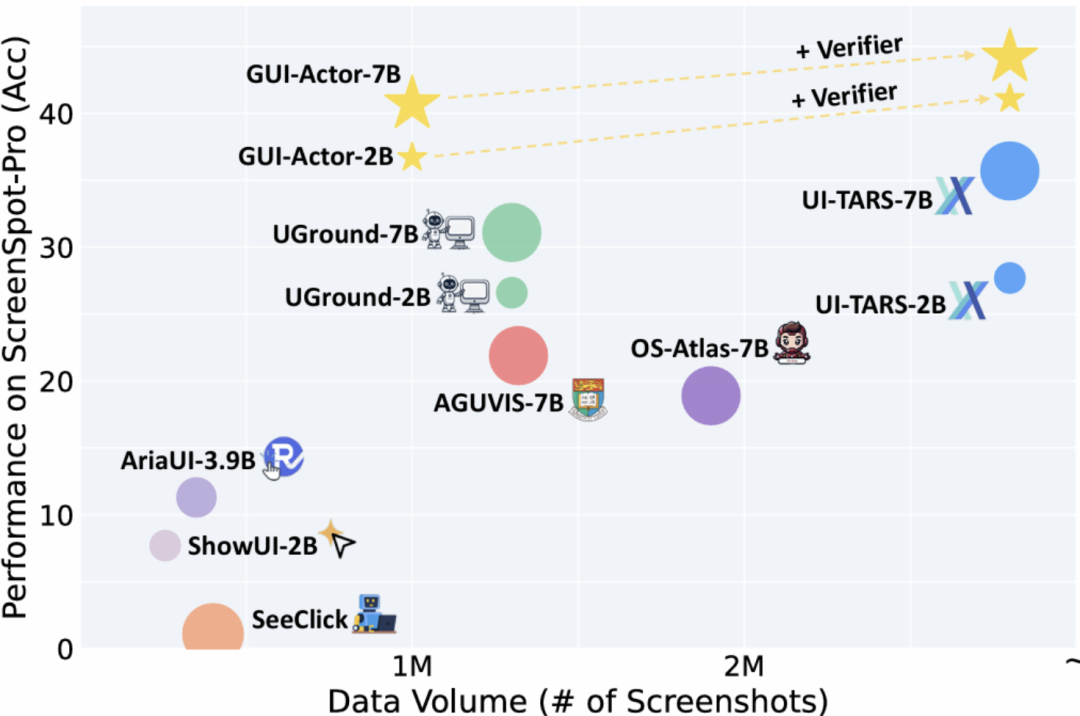
它通过注意力机制、多补丁监督和验证器,基于Qwen2-VL/2.5-VL,实现无坐标定位,性能超72B模型(ScreenSpot-Pro 44.6分),适配任意屏幕。
其轻量级训练模式和多区域预测功能进一步降低了开发门槛,适用于UI测试、RPA、无障碍技术等场景。
GitHub 项目地址:https://github.com/microsoft/GUI-Actor

● 一款改变你视频下载体验的神器:MediaGo
● 字节把 Coze 核心开源了!可视化工作流引擎 FlowGram 上线,AI 赋能可视化流程!
● 英伟达开源语音识别模型!0.6B 参数登顶 ASR 榜单,1 秒转录 60 分钟音频!
● 开发者的文档收割机来了!这个开源工具让你一小时干完一周的活!
● PDF文档解剖术!OCR神器+1,这个开源工具把复杂排版秒变结构化数据!

(文:开源星探)