

在面临 PDF 文档解析功能实现时,开发者会去找文本、表格、图片提取等等不同的SDK(API)库,导致写的代码像“拼积木”,效率低还容易出错。
想提取文字,要用 PyMuPDF;想识别表格,还得上 pdfplumber 或 Docling;结果提出来的数据格式还不统一,处理麻烦……
现在有了更优雅的选择:ParseStudio。专为PDF解析量身打造,它集成了Docling、PyMuPDF、LlamaParse三种解析引擎,API设计简洁,模块化架构让你随心切换解析器,轻松搞定多模态解析任务。

只需几行代码就能提取文字、表格、图片,还能转Markdown格式!适合 Python 开发者,尤其是需要批量处理 PDF 的场景。
主要功能
-
• 模块化设计:支持Docling、PyMuPDF、LlamaParse,一键切换解析器,适配不同场景。 -
• 多模态解析:同时提取文本、表格、图片,全面覆盖PDF内容,无需多个库组合。 -
• 极简 API:统一封装,几行代码即可搞定复杂解析任务。 -
• 表格转Md:自动将表格转为Markdown格式,便于后续处理。 -
• 图片元数据:提取图片时附带页码、坐标等信息,方便定位和分析。 -
• 批量处理:支持一次性处理多个PDF文件。
快速入手
ParseStudio的安装和使用及其简单,清晰易懂,由于它本质上是一个 Python 三方库,所以只需要 pip 命令即可一键安装。
必备环境:Python 3.8+
Llama解析器需要配置API-Key
安装ParseStudio库
pip install parsestudio或者克隆源代码进行安装
git clone https://github.com/chatclimate-ai/ParseStudio.git
cd ParseStudio
pip install .安装完成后,就可以在Python代码中调用了。
实例化ParseStudio解析器
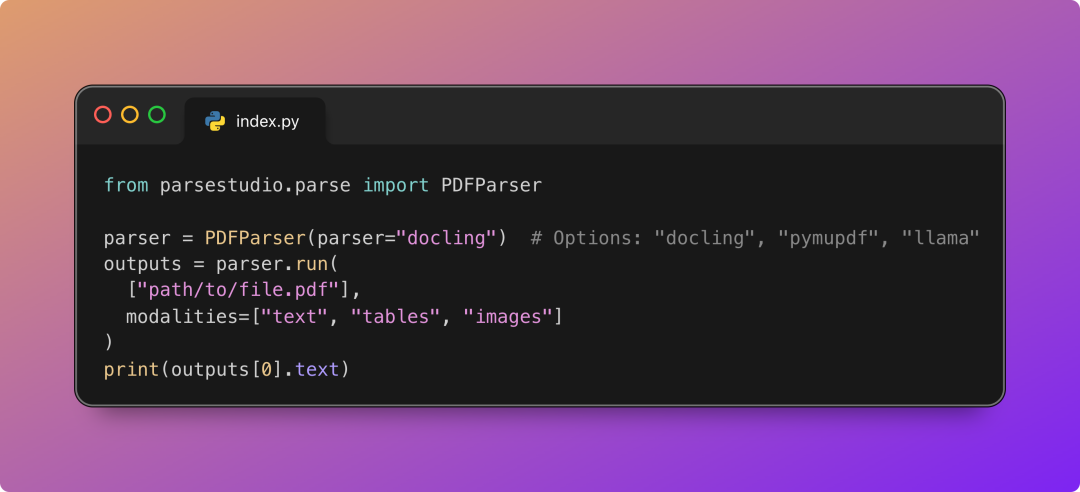
from parsestudio.parse import PDFParser
# Initialize with the desired parser backend
parser = PDFParser(parser="docling") # Options: "docling", "pymupdf", "llama"解析PDF文件示例:
outputs = parser.run(["path/to/file.pdf"], modalities=["text", "tables", "images"])
# Access text content
print(outputs[0].text)
# Output: text="This is the extracted text content from the PDF file."
# Access tables
for table in outputs[0].tables:
print(table.markdown)
# Output: | Header 1 | Header 2 |
# |----------|----------|
# | Value 1 | Value 2 |
# Access images
for image in outputs[0].images:
image.image.show()
metadata = image.metadata
print(metadata)
# Output: Metadata(page_number=1, bbox=[0, 0, 100, 100])实用场景
-
• 数据分析:批量提取PDF中的表格和文本,转为Markdown或CSV,助力市场研究或财务分析。 -
• 科研信息提取:从学术论文中提取标题、摘要、表格、图片,加速文献整理。 -
• 文档数字化:将合同、报告等PDF转为结构化数据,方便存档或RAG系统集成。 -
• 内容创作:提取图片和文本,快速生成演示文稿或报告素材。 -
• 自动化工作流:批量处理上千PDF,生成统一格式输出,适合企业文档管理。
写在最后
借助 ParseStudio 几行代码就能搞定文本、表格、图片提取,统一封装了 Docling、PyMuPDF、LlamaParse,灵活又高效。
还支持批量处理和Markdown输出。普通开发者也能轻松上手,效率直接起飞。
GitHub 项目地址:https://github.com/chatclimate-ai/ParseStudio
(文:开源星探)