



论文链接:
https://openreview.net/forum?id=kuhIqeVg0e
代码链接:
https://github.com/gersteinlab/chemagent

研究背景:化学推理的挑战与痛点
在 LLM 不断强大的今天,化学推理任务仍然是一个极具挑战性的研究方向。化学推理通常涉及复杂的多步骤过程,要求精确的计算和严谨的推理,即使是微小的错误也可能导致连锁失败。
虽然先进 LLM 能够处理一些简单的科学任务,但当涉及需要复杂推理的化学场景时,其表现显著下降。我们可以将这些挑战概括为三个关键问题:
首先,大型语言模型在有效利用领域特定公式方面存在困难。化学公式不仅包含特殊符号,还需要模型理解公式背后的应用场景和限制条件。即使是当前最先进的语言模型,也常常难以准确应用这些专业公式。
其次,模型在执行推理步骤时容易出错。如 Liao 等人(2024)[1] 的研究所示,即使在相对简短的推理链中,单个错误也会产生级联效应,降低答案质量并增加额外错误的概率。这一现象在化学计算中尤为明显,因为后续步骤往往依赖于前一步骤的精确结果。
第三,当尝试将文本推理与 Python 代码计算相结合时,语言模型常常产生语法错误,导致代码无法编译执行。Zhong 等人(2024b)[2] 指出,这种代码整合问题严重限制了语言模型在需要精确计算的化学任务中的应用。
现有的方法在应对这些挑战时存在明显局限。Ouyang 等人(2024)[4] 提出的 StructChem 虽然尝试通过分解推理过程,将化学推理格式化为公式生成、详细的逐步推理和基于置信度的审查等阶段,但仍然缺乏灵活性。
与人类学习者能够从经验中持续学习不同,这些方法严重依赖人工策划的知识或固定的工作流程,无法自我进化和适应新情境。人类解题者通常会从先前任务中抽象并存储定理或解决策略,并在未来解题过程中利用这些记忆,而现有 AI 方法缺乏这种能力。

图 1 生动地展示了这些挑战。在解决氢原子能量跃迁问题时,我们可以观察到三种不同的方法及其结果:
(a)标准的 Chain-of-Thought 方法在步骤 3 和 4 中出现计算错误,导致最终结果偏离正确答案。这反映了 Wang 等人(2024a)[3] 提出的问题——即使是先进的语言模型,在多步计算过程中也容易累积错误。
(b)StructChem 方法(Ouyang 等人,2024)[4] 虽然引入了公式生成和结构化的逐步推理,但由于在步骤 1 和 4 中使用了不正确的常数和单位转换,最终导致结果错误。这说明仅仅改进推理结构是不够的,模型还需要对化学专业知识有深刻理解。
(c)本文提出的 ChemAgent 方法通过任务分解、从记忆库检索相关记忆和结构化推理,成功得出了准确答案。这展示了记忆增强框架在提高化学推理准确性方面的潜力。

ChemAgent:基于自更新记忆库的创新框架
基于上述洞察,耶鲁大学、斯坦福大学、上海交大、UIUC 等研究团队提出了 ChemAgent 框架,引入了动态“记忆库”(LIBRARY)系统,以促进迭代问题解决,并基于任务分解持续更新和精炼其内容。这一系统从人类认知机制获取灵感,旨在模拟人类如何通过结构化记忆组织和检索过往经验来解决复杂问题。

如图 2 所示,ChemAgent 的整体框架包含两个核心部分:(a)基于记忆库的推理和(b)记忆库构建。图的左侧展示了 ChemAgent 如何利用记忆库解决新问题,而右侧则说明了如何通过任务分解和验证构建记忆库。这种双重机制确保了系统能够不断自我完善,提高解决问题的能力。
2.1 记忆库的三重结构设计
ChemAgent 中的记忆库并非简单的知识存储,而是一个精心设计的结构化系统,包含三种互补的记忆组件。

如图 3 所示,给定一个计算电子动量的任务 P,ChemAgent 会从记忆库中提取相关记忆实例。这三种记忆类型分别为:
规划记忆(Planning Memory, Mp)存储高层次策略和解决复杂问题的方法论。这类似于人类在解决问题时所依赖的抽象策略和方法。
在图 3 的右上角,我们可以看到规划记忆包含相关任务(计算电子的德布罗意波长)和解决策略(描述波粒二象性、动量计算方法等)。规划记忆使模型能够理解“如何”解决特定类型的问题,而不仅仅是“做什么”。
执行记忆(Execution Memory, Me)包含特定问题上下文及其详细解决方案,作为具体的执行计划。这类似于人类对具体问题解决步骤的记忆。图 3 左侧展示了执行记忆的结构,包含目标、检索到的公式、详细的推理过程和最终答案。执行记忆为模型提供了解决特定子任务的详细蓝图。
知识记忆(Knowledge Memory, Mk)存储基础化学原理、常数和公式,作为随时可用的参考。图 3 右侧的知识记忆包含思考过程、相关公式解释等信息,确保模型在计算过程中使用正确的化学常数和理论基础。
这三种记忆组件被存储在结构化的树状格式中,允许系统在解决问题过程中高效检索。与之前关于 LLM 外部记忆系统的研究不同,ChemAgent 将这些组件精心整合到一个完整的智能体框架中,并允许它们动态更新。
2.2 基于记忆的推理流程
ChemAgent 的推理过程是一个动态且自适应的流程。在测试阶段,系统首先将问题分解为几个子任务。对于每个子任务,系统检索与当前子任务相似度超过预定义阈值 θ 的记忆单元 Ur 来协助解决。相似度通过 Llama3 的嵌入计算:
相似度 (Ta, Tb) = Embed(Ta)·Embed(Tb) / (||Embed(Ta)|| × ||Embed(Tb)||)
当执行记忆中不存在相似子任务时,ChemAgent 会启动自我改进机制,通过利用 LLMs 的内部参数知识来丰富记忆。系统指导 LLM 识别给定子任务的主题(如量子化学或热力学),并生成与该主题相关的自创化学问题,从而形成一种“合成”执行记忆。
更重要的是,记忆库在运行时会不断更新,加入新解决的子任务及其解决方案:
Me = Me ∪ {(Cj, Tj, Oj)}
Mp = Mp ∪ {(Tj, Kj)}
其中,Kj 代表用于解决子任务的整体策略知识(如公式、概念、解决顺序)。这种动态更新确保记忆库不断进化,持续提高问题解决能力。

实验设计与性能评估
为了评估 ChemAgent 的有效性,作者在 SciBench 的四个化学推理数据集上进行了严格评估。这些数据集覆盖了不同化学领域:QUAN(量子化学)、CHEMMC(量子力学)、ATKINS(物理化学)和 MATTER(化学动力学)。

表 1 展示了在四个数据集上的实验结果。ChemAgent 在所有数据集上均优于基线方法:
在 CHEMMC 数据集上,ChemAgent 达到了 74.36% 的准确率,比直接推理方法提高了 46%,比 StructChem 提高了 15.39%。这一显著提升说明 ChemAgent 在处理量子力学问题时尤为有效。
在 MATTER 数据集上,ChemAgent 的准确率为 48.98%,比最佳基线方法 StructChem 高出 18.31%。这表明 ChemAgent 在化学动力学领域也有明显优势。
在 ATKINS 数据集上,ChemAgent 的准确率为 61.18%,虽然相对于 StructChem 的提升较小(1.37%),但仍然是所有方法中表现最好的。
在 QUAN 数据集上,ChemAgent 与少样本 + Python 方法达到相同的准确率(44.12%),比 StructChem 高出 2.94%。
平均而言,ChemAgent 的准确率为 57.16%,比当前 SOTA 方法 StructChem 提高了约 10%,比直接推理方法提高了 37%。这些结果清晰地表明,ChemAgent 的记忆库和自我改进机制能显著提升化学推理任务的性能。
此外,研究还将 ChemAgent 应用于开源模型,如 Llama3-7b、Llama3-70b 和 Qwen2.5-72b。结果显示,随着基础模型能力的增强,ChemAgent 带来的性能提升更为显著。例如,在 Llama3-70b 上,ChemAgent 将平均准确率从 29.48% 提高到 42.52%,提升了 13.04%。

深入分析:ChemAgent 成功的秘诀
为什么 ChemAgent 能在化学推理任务上取得如此显著的成功?研究团队通过多角度分析揭示了几个关键因素。
4.1 计算和单位转换的精确性提升
ChemAgent 在计算和单位转换方面实现了显著更高的准确率,这得益于两个关键设计:
首先,在记忆库中,每个子任务的示例都包含相应的 Python 代码,这使模型能够参考正确的代码结构和实现。当面对新问题时,模型可以借鉴这些示例,减少语法错误和实现错误。
其次,ChemAgent 在长期规划记忆中保存了单位转换步骤,创建了一个可靠的单位转换知识库。这解决了化学推理中常见的单位转换错误问题,确保计算过程中使用一致的单位系统。
这两个因素共同作用,大大降低了化学计算中的错误率,提高了最终结果的准确性。
4.2 记忆相似度与解决方案质量的关系
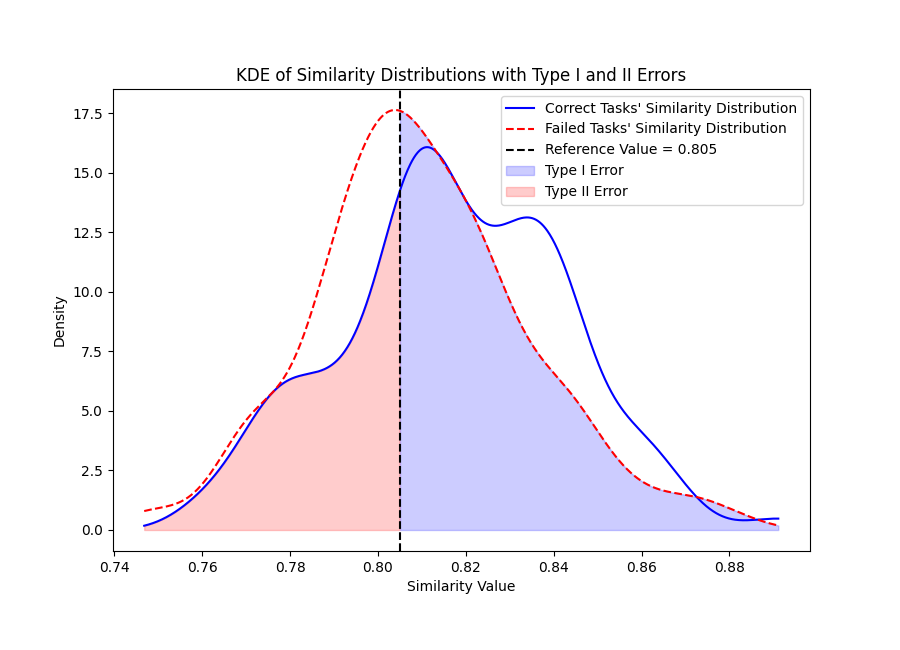
研究团队对记忆相似度与问题解决成功率的关系进行了深入分析。如图 8 所示,当解决给定问题 P 时,系统会调用一系列记忆 [U1, …, Un],它们与问题的相似度记为 [S1, …, Sn],平均相似度为 Smean,P。
成功解决的任务(蓝色区域)和失败任务(红色区域)的相似度分布有明显差异。成功解决的任务平均相似度通常高于 0.82,而失败任务的相似度集中在 0.80 左右。图中虚线表示参考值 0.805,可用作判断是否有可靠记忆的阈值。
研究还进行了 Chi-Square 独立性检验,评估相似度阈值(> 0.805)与解决方案正确性之间的关系。检验统计量为 8.77,p 值为 0.003,表明这种关系具有统计显著性。这一发现说明,提高调用记忆与问题的相似度是提升问题解决性能的重要途径。
4.3 记忆调用数量的影响

研究还分析了调用记忆数量对性能的影响。如图 9 所示,随着调用记忆数量(shots)的增加,平均准确率总体呈上升趋势,但变异性也随之增大。
这表明,更多的记忆实例能提供更丰富的知识,帮助模型更准确地解决问题。然而,过多的记忆实例也可能引入噪声和不相关信息,增加混淆的风险。最终,研究选择了 4-shot 配置,在性能和稳定性之间取得了良好平衡。
有趣的是,研究发现 Execution Memory(Me)中一些看似不相关的信息有时可以增强 LLM 在解决特定子任务时的创造力,使 4-shot 设置在最大准确率方面表现优异。这表明,适度的“噪声”信息可能有助于模型探索更多解决方案路径,特别是在处理困难和未知任务时。
4.4 错误分析与局限性
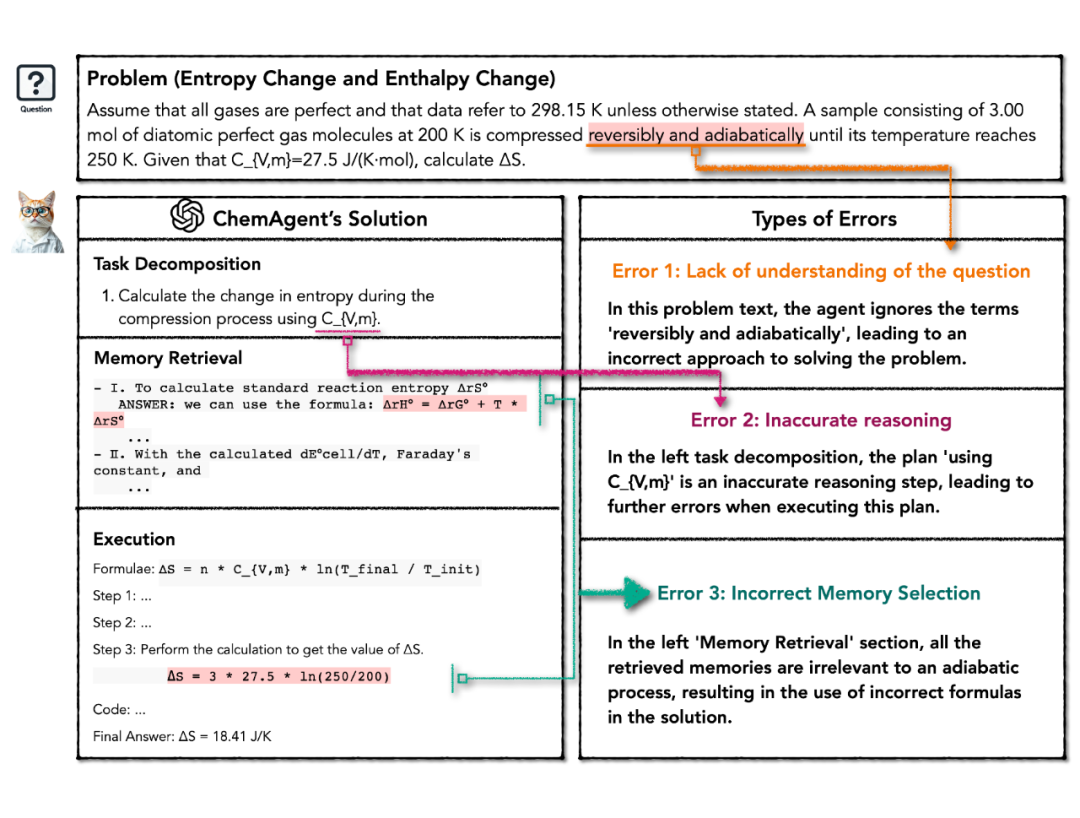
为了更全面地理解 ChemAgent 的局限性,研究团队对失败案例的轨迹进行了分析,发现了三类主要错误:
第一类是问题理解不足。如图所示(Error1),当问题文本包含关键隐藏信息(如“可逆”和“绝热”)或过多冗余细节时,模型可能无法正确把握问题要点。这种挑战是可以理解的,因为即使人类解题者也可能被这些信息误导。这类错误通常独立于所采用的方法,可能是 LLM 固有的限制。
第二类是推理不准确。如图所示(Error 2),LLM 的规划能力在处理复杂问题时仍然不足。错误的规划会导致推理链出现问题,因为后续决策和操作都基于初始问题分解。这个问题会持续存在,直到评估与精炼模块检测到错误,但有时纠正可能为时已晚。
第三类是记忆选择不当。如图所示(Error 3),虽然带有记忆的 ChemAgent 表现优于没有记忆的设置,但有时它会调用误导性信息,即使调用记忆与问题的相似度很高。这表明需要更复杂的记忆检索和利用策略。
图 7 中的例子展示了一个熵变和焓变问题。虽然调用的记忆和子任务 1.1 有相当的相似度——都涉及压缩过程中的熵变,但细微的差别在于当前问题涉及绝热过程,而记忆中的例子不是。
这种看似微小的差异可能导致解题策略的重大改变。区分误导性和有益的记忆仍然是一个挑战,因为调用的记忆和问题文本在语义上可能相似,但在关键方面存在差异。

化学领域的广泛覆盖
ChemAgent 的一个重要优势是其对化学领域的广泛覆盖能力。如图 10 所示,四个数据集涵盖了 15 个化学子领域,从量子力学到气体定律等。
QUAN 数据集主要涉及量子化学、光子学和光谱学等领域,侧重于原子和分子结构的量子力学描述。
CHEMMC 数据集专注于量子力学及其在化学键合中的应用,包括波粒二象性、光电效应等主题。
MATTER 数据集研究化学动力学和反应机制,探讨反应速率、反应机理和热力学过程。
ATKINS 数据集覆盖物理化学的广泛领域,包括热力学、化学平衡、反应动力学等。
ChemAgent 在这些多样化领域均取得了显著的性能提升,证明了其记忆库和自我进化机制的泛化能力。这种广泛的领域覆盖使 ChemAgent 成为一个真正通用的化学推理框架,能够应对从基础理论到应用化学的各类问题。

研究意义与未来展望
ChemAgent 的创新不仅在于其显著的性能提升,更在于它为 AI 系统在专业领域的自我进化能力开辟了新途径。通过将化学推理问题分解为可管理的子任务,并构建动态自更新的记忆库,ChemAgent 模拟了人类学习者如何从经验中学习并应用知识的过程。
尽管 ChemAgent 展现了令人瞩目的性能,记忆机制在处理前所未见的特殊案例时仍有待改进。未来研究方向包括:探索更高效的记忆检索机制、开发更精细的子任务分解策略、扩展到其他科学推理领域以及与工具增强方法的结合。
ChemAgent 的创新意义还在于它展示了自更新记忆库可以作为一种通用机制,帮助语言模型在各种专业领域实现持续自我提升。这一方法有潜力应用于药物发现、材料科学等更广泛的化学应用,以及其他需要精确推理和专业知识的领域。

(文:PaperWeekly)