

想从零开始训练一个能看图聊天的多模态视觉模型(VLM),却担心复杂流程、高成本、高门槛?
最近在 GItHub 上发现一款可以从零开始训练一个多模态视觉模型的开源模型:MiniMind-V。

它提供详细的训练流程,只需 1 小时和 1.3 元(约 NVIDIA 3090 单卡租用成本),即可训练一个 26M 参数的轻量 VLM,支持识图与对话。
视觉语言模型(如 LLaVA、Qwen-VL)因其识图对话能力备受瞩目,但动辄上亿参数和复杂训练流程让个人开发者望而却步。
MiniMind-V 这个开源模型开了一个好头,以 26M 参数的超轻量设计,提供从数据处理到指令微调的全流程代码。
它不仅是一个开源模型,还是一份面向 LLM 和 VLM 初学者的优质教程,社区反响热烈(GitHub 已揽获 2.4k+ 星)。
几乎不依赖第三方封装框架,兼容 Hugging Face 和 OpenAI API。
主要亮点
-
• 超轻量模型:仅 26M 参数(0.026B),约为 GPT-3 的 1/7000,单卡 3090 即可训练。 -
• 多模态能力:支持单图和多图输入,结合文本进行对话。 -
• 全流程开源:包含数据处理、预训练、SFT 和推理完整代码,支持数据集清洗和自定义配置。 -
• 跨模态对齐:采用简单线性变换,将 CLIP 的 768 维视觉 token 对齐到 LLM 空间。 -
• 易用接口:提供 OpenAI 兼容 API,可接入 FastGPT、OpenWebUI 等。
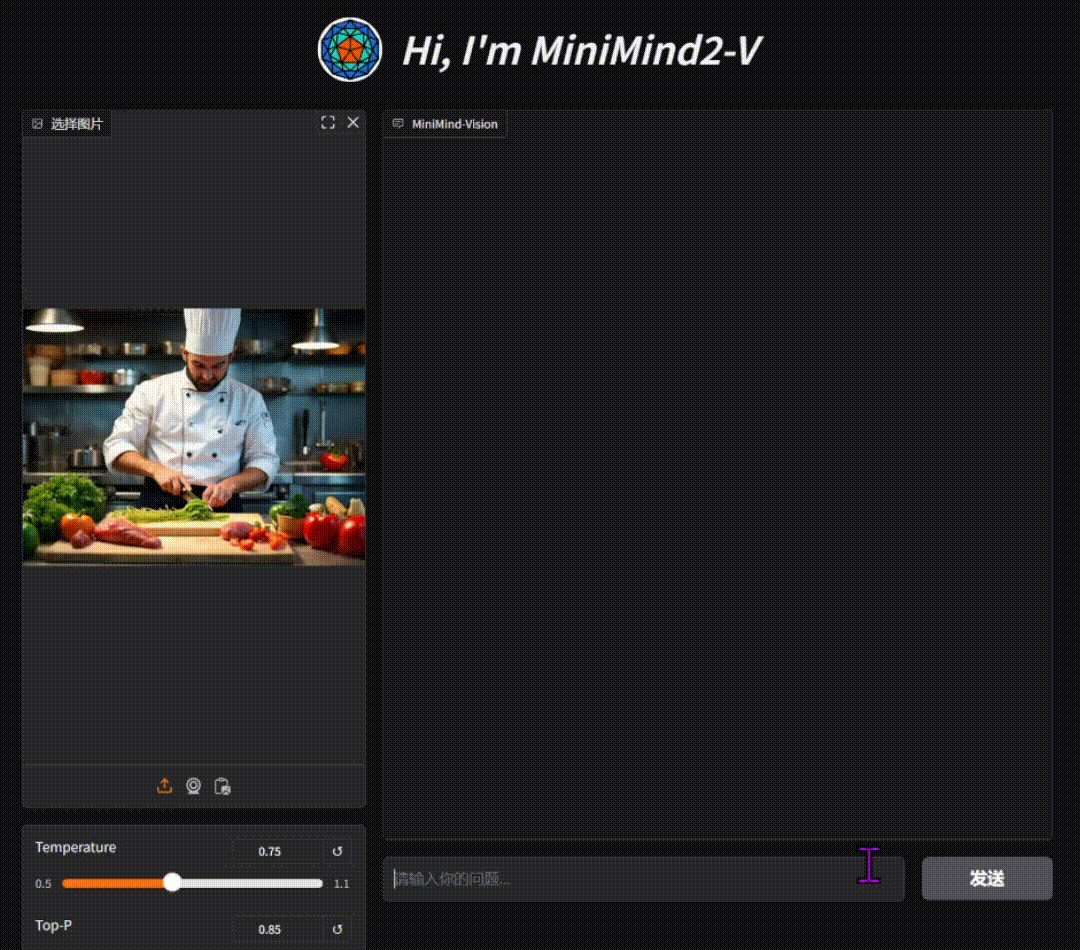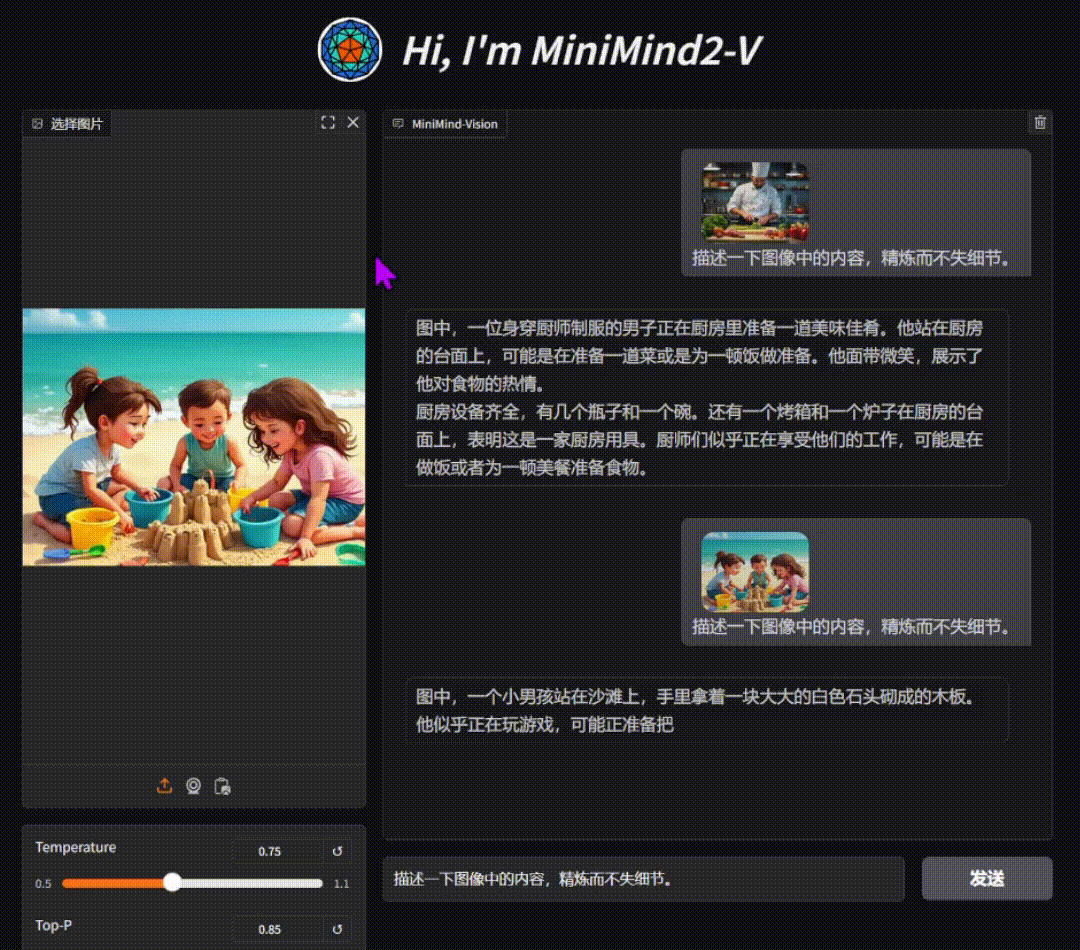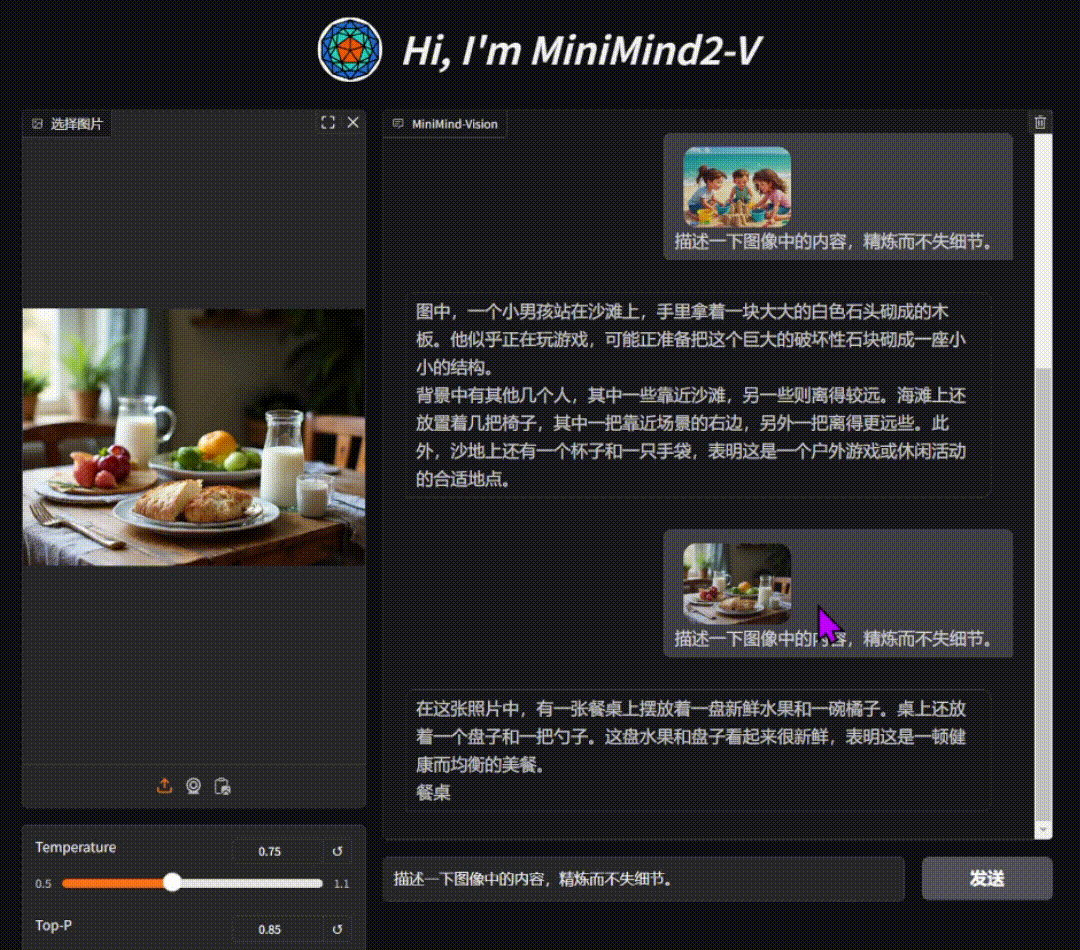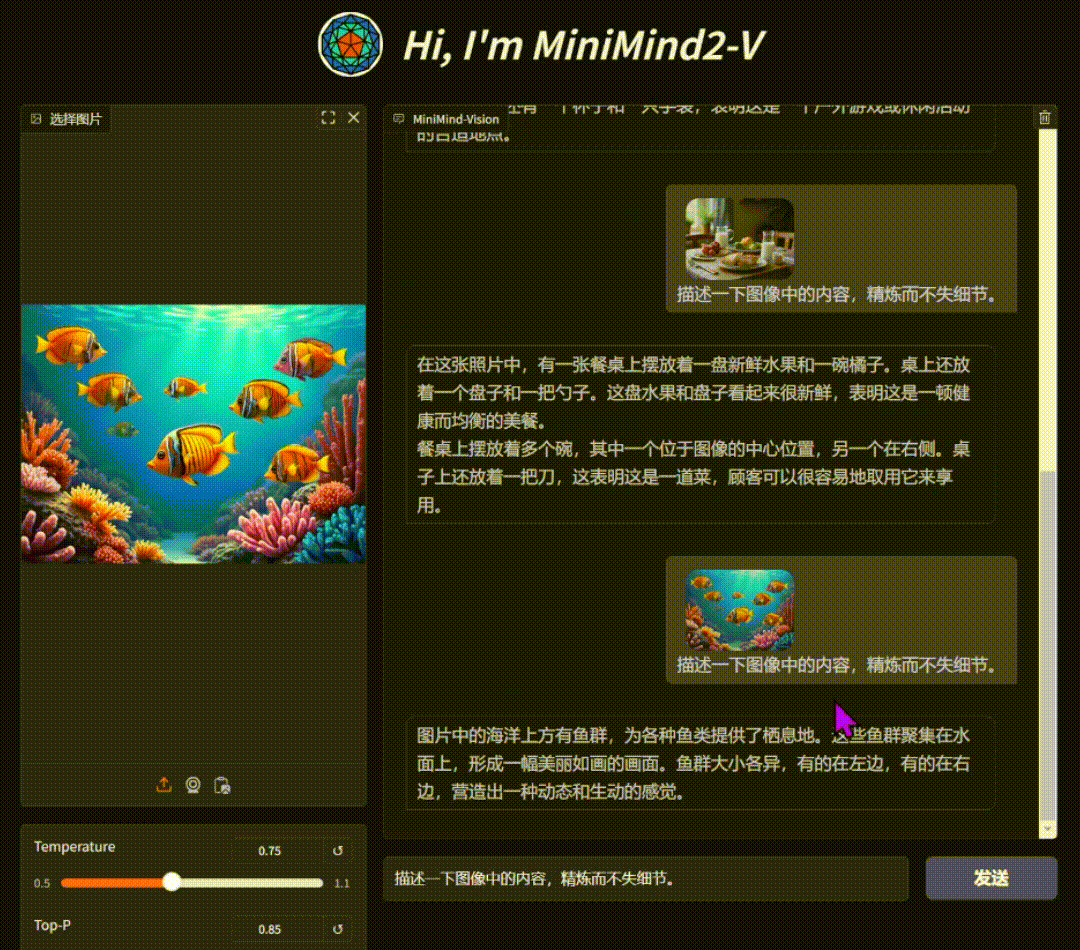
单图对话测试效果

快速上手
MiniMind-V 的训练和推理过程简单,以下是详细步骤,助你一小时复现模型:
① 克隆项目代码并安装依赖
git clone https://github.com/jingyaogong/minimind-v
cd minimide
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple② 下载clip模型
# 下载clip模型到 ./model/vision_model 目录下
git clone https://huggingface.co/openai/clip-vit-base-patch16
# or
git clone https://www.modelscope.cn/models/openai-mirror/clip-vit-base-patch16③ 下载纯语言模型权重
# 下载纯语言模型权重到 ./out 目录下(作为训练VLM的基座语言模型)
https://huggingface.co/jingyaogong/MiniMind2-V-PyTorch/blob/main/lm_512.pth
# or
https://huggingface.co/jingyaogong/MiniMind2-V-PyTorch/blob/main/lm_768.pth④ 下载MiniMind2-V模型
git clone https://huggingface.co/jingyaogong/MiniMind2-V⑤ 启动方式(命令行、Web)
# 命令行
# load=0: load from pytorch model, load=1: load from transformers-hf model
python eval_vlm.py --load 1
# web界面
python web_demo_vlm.py然后接下来就可以开始训练自己的模型了。
开始训练之前,需要确认环境及数据集。
预训练指令:
python train_pretrain_vlm.py --epochs 4监督微调:
python train_sft_vlm.py --epochs 4测试模型效果:
python eval_vlm.py --model_mode 1 # 默认为0:测试pretrain模型效果,设置为1:测试sft模型效果更多详细配置及入手教程可以查看 GitHub 文档,初学者也能上手。
模型结构一览
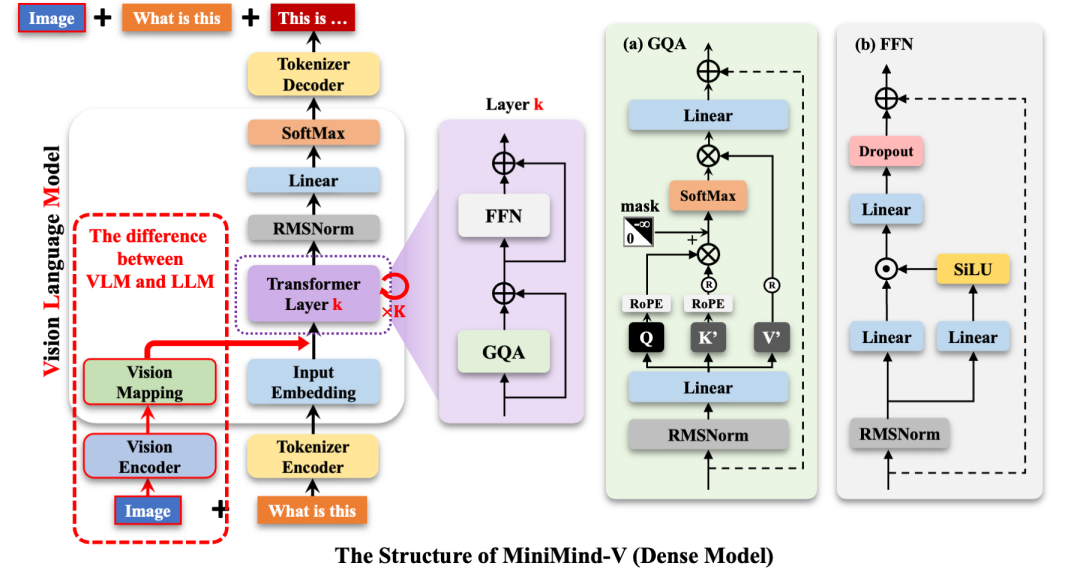
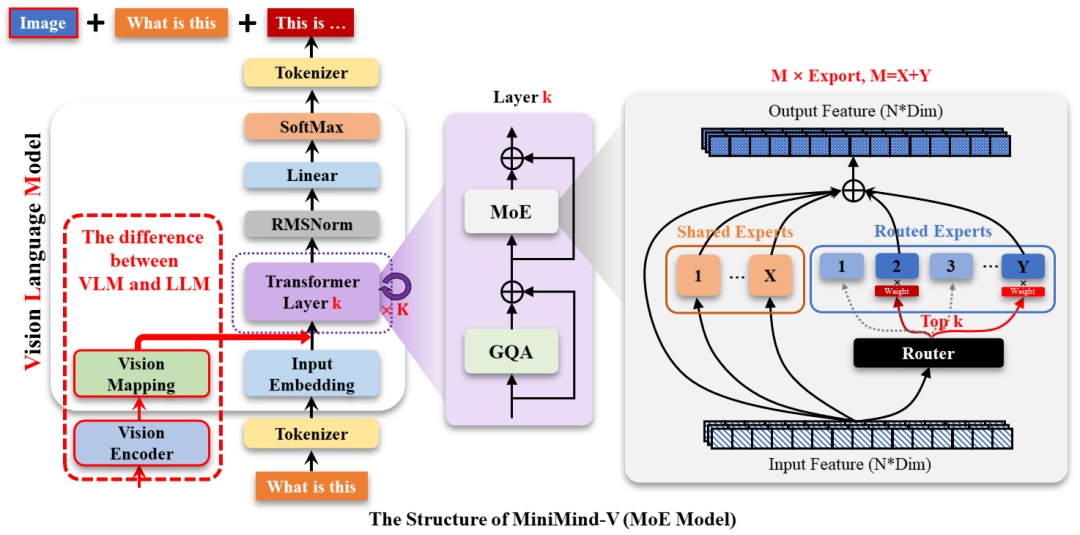
MiniMind-V 的核心是小模型 + 强适配的设计思路:
-
• Visual Encoder:使用轻量级图像编码器(如 CLIP、MobileSAM 等) -
• MLP Adapter:用简单 MLP 模块适配语言与图像特征 -
• LLM Backbone:集成 MiniGPT(如 tiny-llama 或 phi),保证对话能力 -
• 可微 Prompt Token 机制:提升图文交互效果
为什么它值得关注?
-
• 超轻量:参数仅 26M,训练仅需 1 小时 -
• 成本低:训练成本不到 1.3 元(基于 Colab / 云主机) -
• 教程清晰:提供完整脚本和注释,初学者也能一看就懂 -
• 易扩展:支持替换视觉 backbone、语言模型 backbone -
• 好集成:可嵌入到自研 AI 助理、机器人等系统中
写在最后
MiniMind-V 是多模态模型领域的开源瑰宝,其低门槛和高透明度让人惊叹。
也许它可能就是你的第一款“可训练、可部署、可理解”的多模态 AI 小模型!
有想法的小伙伴,可以用它训练一个能看图、能对话的多模态小模型,也可以助你快速了解多模态视觉语言模型的训练逻辑和部署方式。
GitHub 项目地址:https://github.com/jingyaogong/minimind-v

● 一款改变你视频下载体验的神器:MediaGo
● 新一代开源语音库CoQui TTS冲到了GitHub 20.5k Star
● 最新最全 VSCODE 插件推荐(2023版)
● Star 50.3k!超棒的国产远程桌面开源应用火了!
● 超牛的AI物理引擎项目,刚开源不到一天,就飙升到超9K Star!突破物理仿真极限!

(文:开源星探)