

今天是2025年4月6日,星期日,北京,天气晴,清明假期最后一天了。
今天早上被llama4刷屏,已经有了很多标题党开始说RAG原地失业以及引领多模态的论调了,这并不好,需要公正的看待这个模型本身,从其官方模型卡看其不足跟技术点,所以先来看看关于Llama4的四点核心总结。
但看完这些工作后发现,核心还是回到了数据上,所以,我们依旧来看看数据本身。之前我们在《大模型微调数据生成工具Easy Dataset及KBLaM知识注入框架评析》(https://mp.weixin.qq.com/s/0PUMbuiyXPUIXunMuH-otw)中介绍过一个微调数据生成框架Easy Dataset,飞书wiki: https://github.com/ConardLi/easy-dataset,https://rncg5jvpme.feishu.cn/docx/IRuad1eUIo8qLoxxwAGcZvqJnDb?302from=wiki。
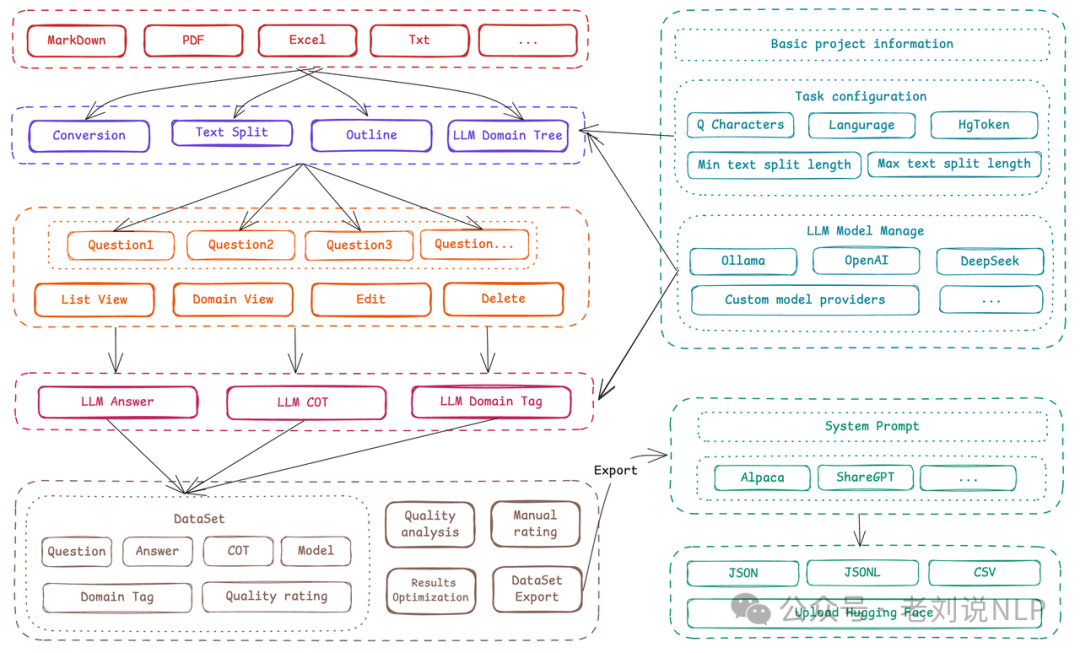
虽然还有些问题,如具体问题看:https://github.com/ConardLi/easy-dataset/issues/,还很初步,纯Js写的,不好二次开发,视频教程在:https://www.bilibili.com/video/BV1y8QpYGE57/,一个知识库只能导入一个文件。不然,需要删除该文件,再导入,弄QA对。整体大面的功能不错,后面支持多文件,并发,就比较适合使用。
除了微调这块,可以看看一个面向推理强化的数据合成框架,Project Loong 项目https://github.com/camel-ai/loong/,核心思想是通过验证器(verifiers) 扩大规模化合成数据生成,以提升大型语言模型(LLMs)在多个领域的推理能力,怎么做的,我们可以看下。
抓住根本问题,做根因,专题化,体系化,会有更多深度思考。大家一起加油。
一、Llama4的四点核心总结及思考
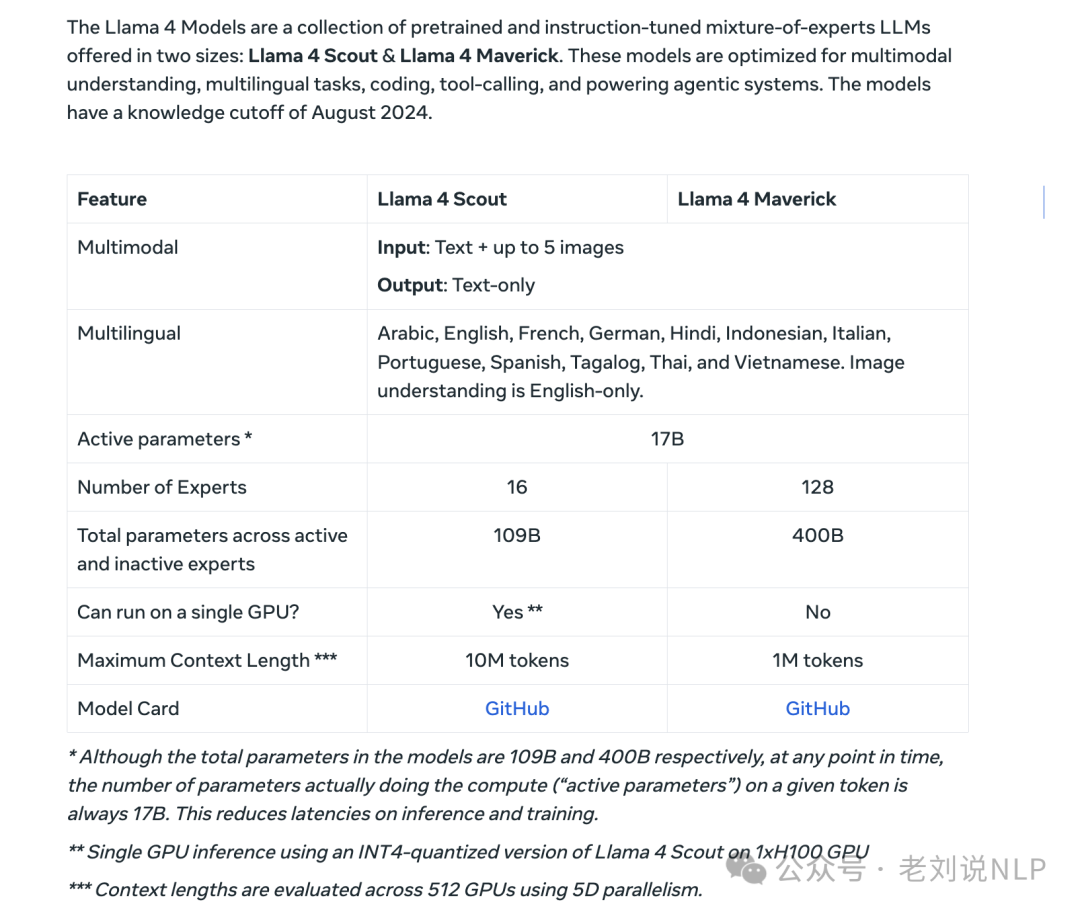
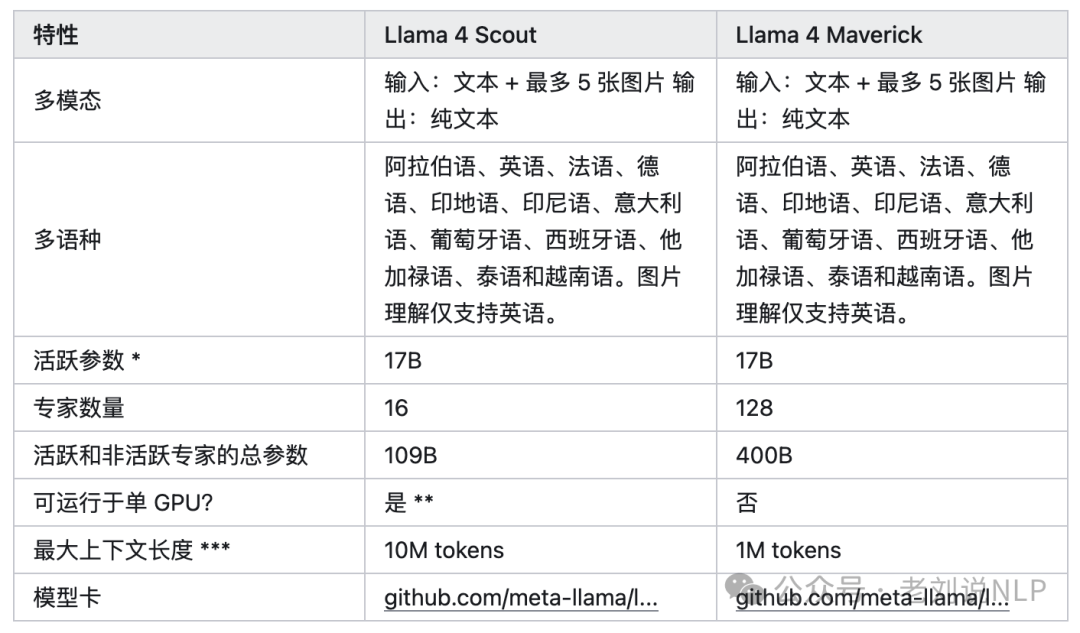
开源进展。llama-4发布,总计三个模型: Llama-4-Scout-17B-16E,其实是109B)MoE模型,多模态输入,16个专家,激活参数量17B,上下文长度10M,知识截至时间2024年8;Llama-4-Maverick-17B-128E,(其实是402B) MoE模型,多模态输入,128个专家,激活参数量17B,上下文长度1M,知识截至时间2024年8月;Llama-4-Behemoth-288B-16E,(其实是2T),还在训练中。
官方公告:https://ai.meta.com/blog/llama-4-multimodal-intelligence/
模型文档:https://www.llama.com/docs/model-cards-and-prompt-formats/llama4_omni/
模型卡:https://github.com/meta-llama/llama-models/blob/main/models/llama4/MODEL_CARD.md
我们来看下总结下,进行Llama4四大亮点最终总结,注意的是,中文不支持,不优化国内使用,也不是推理模型,仅是MOE模型、不友好部署,所以不要太冲动。虽然是亮点,但是感觉亮点很小,推理跟参数比不过R1,那就打一个全模态,然后支持function call,虽然模型上下文长度可以到1000w,先不说kv-cache部署成本,看效果,目前超过几万以上就不太可用,所以也不会带来太大的影响。
1、原生多模态
所有模型都采用早期融合(earlyfusion)策略,将文本、图像、视频Token无缝整合到统一的模型骨干中;能同时理解文字+图片+视频,但输出只有文字(不会生成图片)。
2、训练流程优化
采用轻量级监督微调(SFT)>在线强化学习(RL)>轻量级直接偏好优化(DPO)的全新pipeline(看起来参考了DeepSeek),以应对多模态输入、推理能力和对话能力的平衡挑战。
设计了一种精心策划的课程策略(curriculumstrategy),确保多模态性能不逊于单一模态专家模型。由于模型能力太强,普通的SFT数据对它来说太“简单”了,因此需要裁剪掉高达95%的SFT数据,而小模型只需要裁剪约50%。通过使用Llama模型作为评判工具,剔除了超过50%被标记为“简单”的数据,仅对剩余的较难数据集进行轻量级SFT。训练过程中模型较早的检查点(checkpoint)可以作为“批评家”来评估后续模型,帮助过滤掉过于简单的训练样本/提示,让模型在不断筛选和学习中变得更强。
过多的SFT/DPO会过度约束模型,限制其在RL阶段的探索能力,所以,在多模态在线RL阶段,通过精心挑选更具挑战性的提示(prompts),模型性能实现了显著提升;
实施持续在线RL策略,交替进行模型训练和数据过滤,保留中等到高难度的提示,在计算成本和精度之间取得了优异平衡。
最后,通过轻量级DPO处理模型响应质量的边缘情况。两个变体均在后训练中融入了广泛的图像和视频帧数据,以提升视觉理解能力,包括对时间活动和相关图像的感知。
3、超长上下文(10M+)
模型在预训练和后训练阶段均以256K的上下文长度为基础,通过创新的iRoPE架构(交错注意力层结合旋转位置嵌入)增强了长度泛化能力。iRoPE架构(”i”代表interleavedlayers,infinite),通过追求无限上下文的目标来指导架构设计,特别是利用长度外推能力,在短序列上训练,泛化到极长序列。
架构去除了传统的位置嵌入,并在推理时引入注意力温度缩放(temperaturescaling),支持高达1000万token的上下文长度,这种在某些注意力层(特别是全局层)不使用位置编码的做法,借鉴了NoPE(NoPositionalEmbedding)论文的思想。
4、多版本小MOE模型
Llama4Scout,性能最强的小尺寸模型,17B激活参数,16个专家,总参数量109B。原生支持多模态,拥有1000万+Token多模态上下文窗口(相当于处理20多个小时的视频),并且能在单张H100GPU上运行(Int4量化后),测试时最多支持8张图片输入;
Llama4Maverick,同级别中最佳的多模态模型,在多个主流基准测试中击败了GPT-4o和Gemini2.0Flash,推理和编码能力与新发布的DeepSeekv3相当,但激活参数量不到后者一半参数,17B激活参数,128个专家,总参数量400B,上下文窗口100万+,提供了同类最佳的性能成本比,预训练数据量约为22万亿token。其实验性聊天版本在LMArena上ELO评分达到1417,排名第二,可以在单个主机上运行;
Llama4Behemoth(预览,训练中) ,Meta迄今最强模型,全球顶级LLM之一,在多个STEM基准上优于GPT-4.5、ClaudeSonnet3.7和Gemini2.0Pro,288B激活参数,16个专家,总参数量高达2万亿(2T),使用FP8精度,在32000块GPU上训练了30万亿多模态Token,作为Maverick模型进行代码蒸馏时的教师模型。
此外,还提供了量化版本(如BF16和FP8),以适配不同硬件需求,Llama4Maverick(128位专家,总参数400B)的FP8量化权重可在一台H100DGX上运行,兼顾性能与部署灵活性。而Llama4Scout甚至能在单个H100GPU上云运行(使用Int4量化)。
但是,我们从中可以看到一些技术上的建议,例如:
最后的建议:
1)轻量级SFT后进行大规模强化学习(RL)在模型的推理和编码能力上产生了更显著的改进。Llama 的RL配方专注于通过策略模型进行pass@k分析采样难提示,并制定难度递增的训练课程。
2)在训练期间动态过滤掉零优势的提示(prompts with zero advantage)并构建包含多种能力的混合提示批次对数学、推理和编码性能提升至关重要。
3)从各种系统指令中采样对于确保模型保留推理和编码的指令遵循能力并在多种任务中表现良好至关重要。 **
二、大模型推理能力合成数据工具Project Loong
我们来看合成数据工具进展,Project Loong 项目https://github.com/camel-ai/loong/,核心思想是通过验证器(verifiers) 扩大规模化合成数据生成,以提升大型语言模型(LLMs)在多个领域的推理能力,其本身是camel-ai系列下的一个项目。
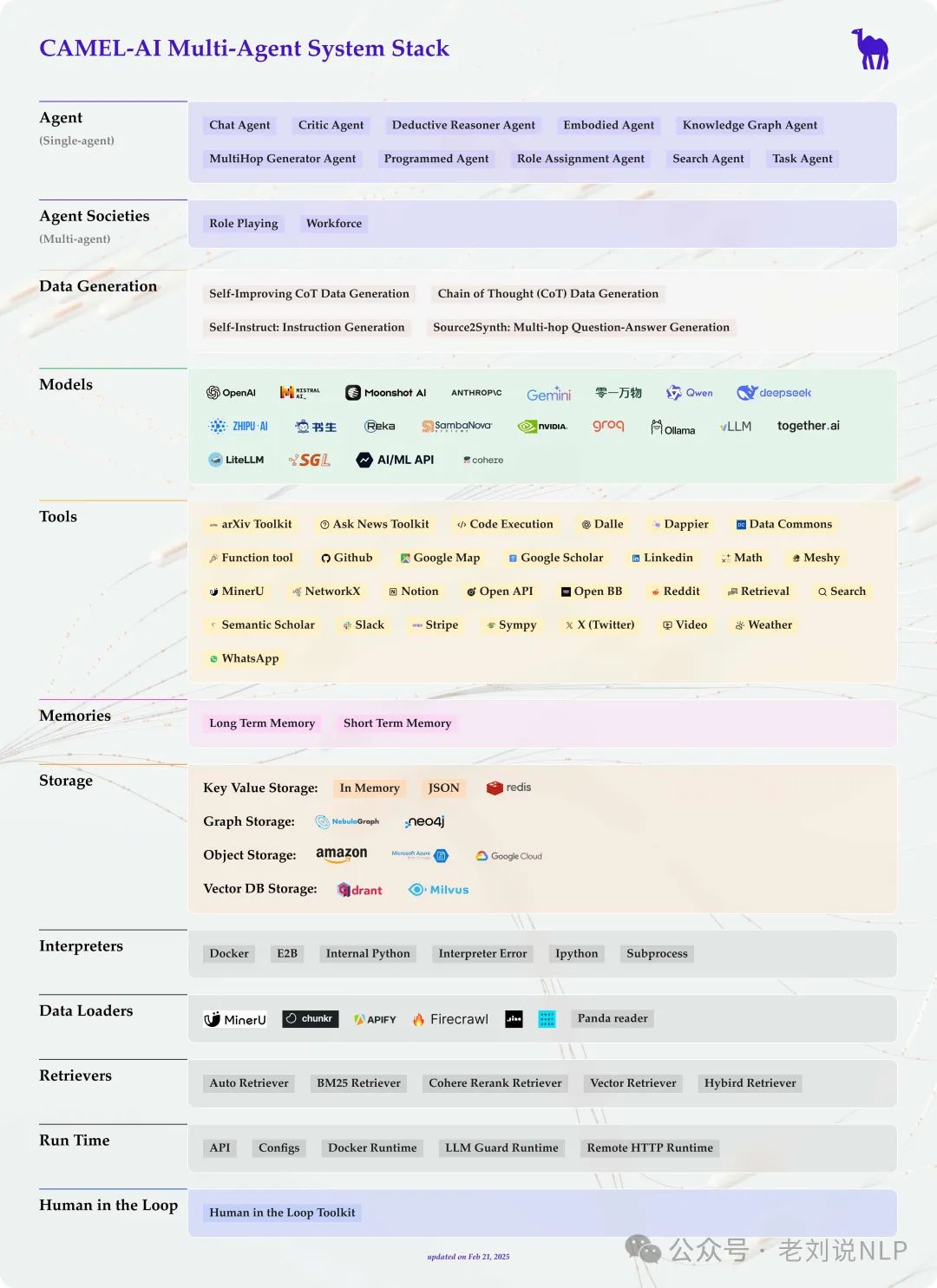
我们来看看其具体实现,其本质上是一个多智能体系统,利用生成器从种子数据集创建合成问题/答案,而验证器则评估这些响应的正确性。然后,可训练代理从这些经过验证的问答中反复学习,通过强化学习和更高级的策略实现可扩展的自我改进。
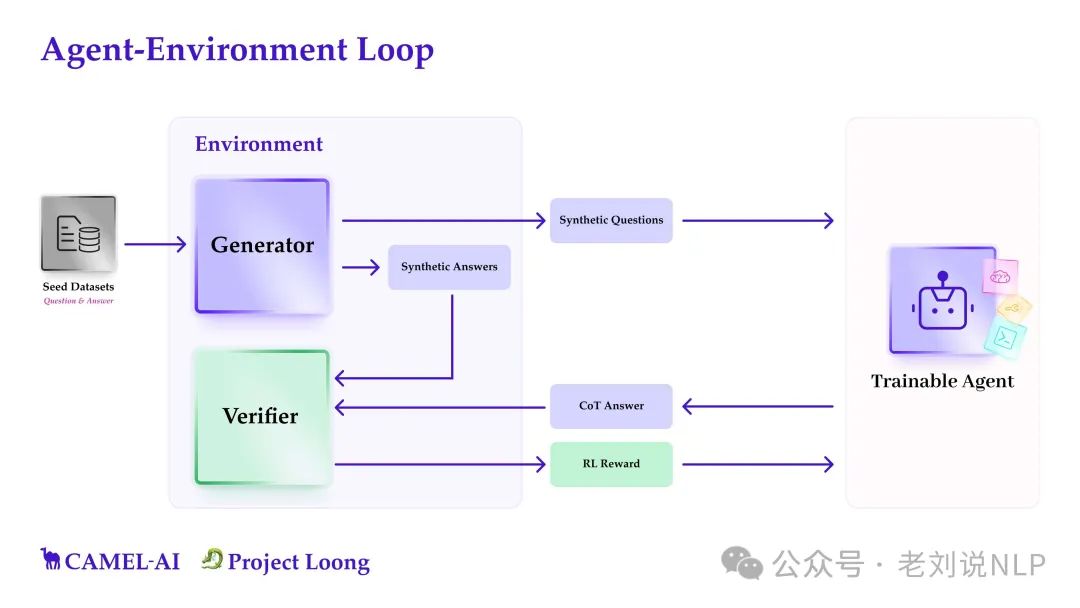
所以,这个项目提供了种子数据集(来自数学、物理、金融等可计算领域的真实、经过人工审查的数据)以及Cookbooks(用于合成数据生成、验证和RL训练循环的模块化脚本,在https://kkgithub.com/camel-ai/loong/blob/main/cookbooks/env_with_generator.ipynb)。
组成包括三个部分。
一个是种子数据集(Seed Dataset),手动收集特定领域的数据集,包含问题和真实答案。种子数据集用于启动合成数据生成过程;每个数据点包括:question、final_answer、rationale(通常是代码)、metadata(许可证、来源、域名、难度、标签、其他任何内容)几个信息。

也可以收集自己的种子数据集并利用 Loong 为您的域生成合成数据。
一个是合成数据生成器(Synthetic Data Generator),基于种子数据集生成任意数量的合成问题和答案。目前包含3551个问题,涵盖8个领域,包括高等数学1615道题、高级物理434道题、计算生物学304个问题、财务20个问题、图形与离散数学179个问题、逻辑110个问题、数学规划68个问题以及安全与保障521个问题。
生成器可以使用多种算法,使用self-instruct(https://arxiv.org/abs/2212.10560)、evol-instruct(https://arxiv.org/abs/2304.12244)或其他数据生成方法(https://github.com/camel-ai/camel/tree/master/camel/datagen)来生成问题,并使用求解器智能体来生成合成答案。
具体流程是:来自种子数据的少量样本提示->生成综合问题、理由和答案->运行验证器->导出监督微调或RL的数据集。
但是,这些合成答案不无法保证总是正确的。虽然可以假设由于代码执行提供了准确的计算,许多合成答案仍然是错误的。不过这不是问题,因为不会从这些原始的合成数据中学习。所以下一步中进一步过滤它,并且只从这些过滤后的合成数据中学习。
一个是验证器(Verifier),几个策略。
首先通过两种独立方法验证合成答案的正确性,直接通过代码执行生成解决方案或者通过自然语言的推理链(Chain-of-Thought,CoT)生成解决方案。如果两种方法的结果一致,则认为答案正确。其次,每个环境还包括一个验证器,用于对LLM响应和合成答案进行语义比较,确保它们实际上是等效的。
所以基于这种设计,可以看到实现代码:
from camel.agents import ChatAgent
from datasets import load_dataset
# Load and initialize a seed dataset
dataset = load_dataset("camel-ai/loong", split="graph_discrete_math")
seed_dataset = StaticDataset(dataset)
# Set up the verifier
verifier = PythonVerifier(required_packages=["numpy", "networkx"])
# Define a model backend to use for the generator
model = ...
# Set up synthetic data generation
generator = FewShotGenerator(seed_dataset=seed_dataset, verifier=verifier, model=model)
# Initialize the Loong environment
env = SingleStepEnv(generator, verifier)
# Define the agent that shall interact with the environment
agent = ChatAgent()
# Example environment interaction
obs = await env.reset()
agent_response = agent.step(obs.question) # a step for the agent
next_obs, reward, done, info = await env.step(agent_response)
大家感兴趣的可以去尝试。
参考文献
1、https://ai.meta.com/blog/llama-4-multimodal-intelligence/
2、https://github.com/camel-ai/loong/
(文:老刘说NLP)