


Meta 又从 OpenAI 挖到了大牛。
OpenAI 核心科学家、思维链提示词(CoT)核心作者、o1 关键人物 Jason Wei。
而在离开 OpenAI 之际,Jason Wei 连续更新了两篇博客,对于 RL 之后的发展提出了自己的想法——验证者定律:训练 AI 解决某个任务的容易程度,与该任务的可验证性成正比。所有既可能解决又容易验证的任务,都将被 AI 解决。
某种意义上来说,对于如何定义今天的 AI 能力,给出了自己的回答,也回应了之前姚顺雨的 AI 下半场的讨论。
简单来说,AI 的进步边界,首先受限于我们能否快速、客观地验证结果。未来 AI 会在那些「易验证」的领域持续突破,而「难验证」的领域则进展缓慢。对于创业者来说,这也是选择合适的赛道的一个很好参考标准。
而第二篇文章,则是 RL 对于他人生的影响——想要超越学习的对象,就必须走出自己的路。
翻译版本转载自「腾讯科技」,Founder Park 有所调整。
Founder Park 联合外滩大会组委会、将门创投,征集能真正改变生活的 AI 硬件,寻找 AI 硬件的新可能。
-
30 万大赛奖金
-
创业扶持礼包
-
更多头部资源链接机会

扫码即可报名
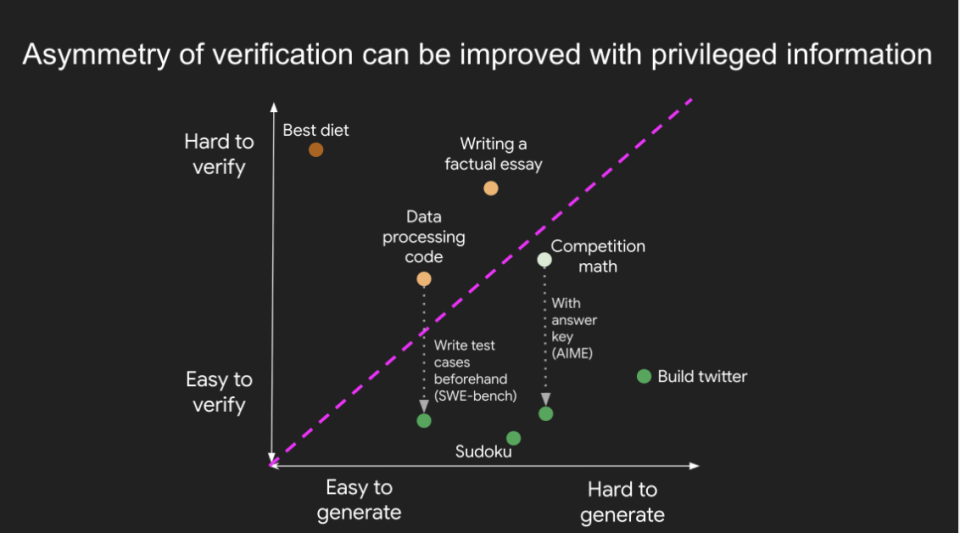
验证的不对称性 (Asymmetry of Verification) 是指,某些任务验证一个解是否正确,要远比从头解决这个问题容易得多。随着强化学习(RL)最终在通用意义上逐渐成熟,验证的不对称性正成为人工智能(AI)领域中最重要的理念之一。
01
通过例子理解验证的不对称性
如果你留心观察,会发现验证的不对称性无处不在。以下是一些典型的例子:
-
数独和填字游戏:解决这些谜题需要花费大量时间,因为你必须在各种约束条件下尝试许多候选答案。但是,要检查一个给定的答案是否正确,却是一件轻而易举的事。
-
网站开发:编写像 Instagram 这样网站的运营代码,需要一个工程师团队花费数年时间。但验证网站是否正常工作,任何一个普通人都能快速完成。
-
网页浏览理解任务(BrowseComp):解决这类问题通常需要浏览数百个网站,但验证任何给定的答案通常要快得多,因为你可以直接搜索答案是否满足约束条件。
有些任务则具有近乎对称的验证性 (near-symmetry of verification):验证答案所需的时间与解决问题本身所需的时间相差无几。例如,验证某些数学问题的答案(比如两个 900 位数的加法)所需的工作量,与你自己解决这个问题几乎一样。另一个例子是某些数据处理程序;跟着别人的代码走一遍并验证其正确性,和你自己编写解决方案所需的时间差不多。
有趣的是,还有一些任务的验证时间可能远超提出方案的时间。例如,对一篇文章中的所有陈述进行事实核查,可能比写这篇文章本身花费的时间还要长(这让人想起了布兰多里尼定律)。许多科学假说也是如此,验证比提出更难。例如,提出一种新的饮食方案(「只吃野牛和西兰花」)很容易,但要验证这种饮食是否对普通人群有益,则需要数年时间。
注:布兰多里尼定律 (Brandolini’s Law)也被称为「废话不对称原理」(The Bullshit Asymmetry Principle),它指出:驳斥谣言或废话所需的能量,要比制造它们高出一个数量级。这恰好描述了那些验证比解决(或创造)更难的任务。
02
改善验证的不对称性
关于验证不对称性最重要的一个认知是:通过对任务进行一些前期研究,可以改善其不对称性。例如,对于一道竞赛数学题,如果你手头有答案,那么检查任何提交的最终答案都是小事一桩。另一个很好的例子是某些编程问题:虽然阅读代码并检查其正确性很繁琐,但如果你有覆盖率足够高的测试用例,就可以快速检查任何给定的解决方案。实际上,这正是 LeetCode 等编程练习平台所做的事情。在某些任务中,可以改善验证过程,但不足以使其变得轻而易举。例如,对于「说出一个荷兰足球运动员的名字」这样的问题,有一份著名的荷兰足球运动员名单会有所帮助,但在许多情况下,验证仍然需要费一番功夫。
03
验证者定律 (Verifier’s Law)
为什么验证的不对称性如此重要?回顾深度学习的历史,我们已经看到,几乎任何可以被量化的东西都可以被优化。用强化学习的术语来说,验证解决方案的能力等同于创建一个强化学习环境的能力。因此,我们得出:
验证者定律:训练 AI 解决一个任务的难易程度,与该任务的可验证性成正比。所有可能被解决且易于验证的任务,都终将被 AI 解决。
更具体地说,训练 AI 解决任务的能力与该任务是否具备以下属性成正比:
-
客观真理 (Objective truth):所有人对什么是好的解决方案有一致的看法。
-
快速验证 (Fast to verify):任何给定的解决方案都可以在几秒钟内得到验证。
-
可扩展验证 (Scalable to verify):可以同时验证许多解决方案。
-
低噪声 (Low noise):验证结果与解决方案的质量尽可能紧密相关。
-
连续奖励 (Continuous reward):对于单个问题,可以很容易地对多个解决方案的好坏进行排序。
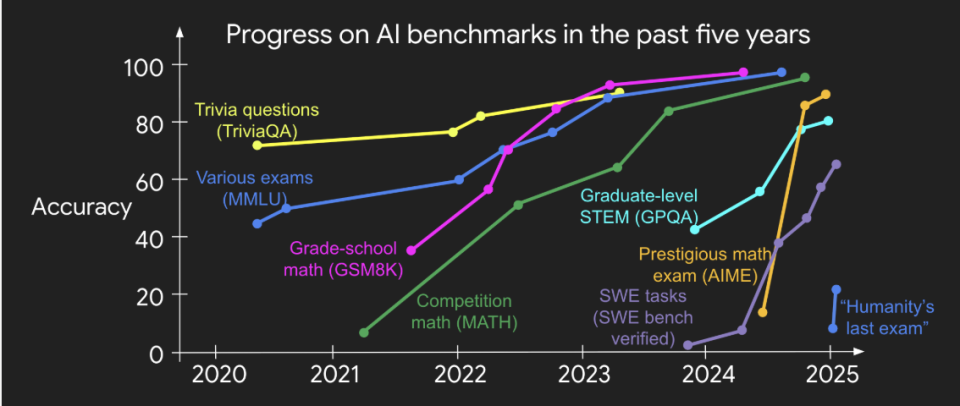
不难相信验证者定律是成立的:过去在 AI 领域提出的大多数基准测试(benchmarks)都易于验证,并且至今都已被解决。请注意,过去十年中几乎所有流行的基准测试都符合前 4 个标准;不符合这些标准的基准测试很难变得流行。另外,尽管大多数基准测试不符合第 5 个标准(一个解要么完全正确,要么完全错误),但你可以通过对许多例子的二元奖励(0 或 1)进行平均,来计算出一个连续的奖励值。
为什么可验证性如此重要?在我看来,最根本的原因是,当上述标准得到满足时,神经网络中发生的学习量是最大化的;你可以进行大量的梯度步骤,并且每一步都包含大量有效的信号。迭代的速度至关重要——这就是为什么数字世界的进步比物理世界的进步快得多的原因。
注:
验证者定律在强化学习中的应用:强化学习,即 AI(称为智能体 Agent)通过与环境互动来学习。它会不断尝试不同的行动,环境则会根据行动的好坏给予奖励 (Reward) 或惩罚。AI 的目标是学会一套策略,以最大化它能获得的总奖励。一个任务的可验证性越高,就越容易为 AI 设计一个清晰、快速的奖励机制,从而极大地加速学习过程。
连续奖励 (Continuous Reward): 在 AI 训练中,奖励是衡量行为好坏的信号。二元奖励 (Binary Reward) 只有两种结果,比如「对」或「错」(1 或 0)。而连续奖励则是一个范围内的数值,比如 0 到 100 分。连续奖励能提供更丰富的信息,告诉 AI 一个「错误」的答案到底有多「差」,或者一个「好」的答案比另一个「好」多少,这使得学习和优化过程更有效率。
梯度步骤 (Gradient Steps): 这是神经网络训练的核心概念,源于梯度下降 (Gradient Descent) 算法。训练过程就像是在一个崎岖的山谷里寻找最低点(代表最佳解决方案)。「梯度」指出了当前位置最陡峭的下山方向,而「步骤」就是沿着这个方向走一小步。快速、低噪声的验证能够提供清晰、准确的梯度方向,让 AI 能更快、更稳地「走下山」,从而最大化学习效率。
04
AlphaEvolve 是验证者定律的成功典型
过去几年里,利用验证不对称性的最杰出公开范例或许就是谷歌开发的 AlphaEvolve。简而言之,AlphaEvolve 可以被看作是一种非常聪明的「猜测与检查」机制的实现,它允许对一个目标进行无情的优化,并已催生了多项数学和操作上的创新。
一个被 AlphaEvolve 优化的简单问题例子是:「找出能容纳 11 个单位六边形的最小外部六边形。」 注意,这个问题完全符合验证者定律的五个理想属性。事实上,我相信任何符合这五个属性的可解问题,都将在未来几年内被解决。
关于 AlphaEvolve 解决的这类问题,有一点值得注意:它可以被视为对单个问题的「过拟合」。在传统机器学习中,我们已经知道了训练集中的标签,其重要的测试是衡量模型对未见过问题的泛化能力。然而,在科学创新领域,我们处于一个完全不同的范畴,我们只关心解决单个问题(训练集 = 测试集!),因为它是一个尚未解决的问题,并且可能具有极高的价值。
注:
AlphaEvolve: 这是谷歌 DeepMind 开发的一个 AI 系统,它使用进化算法来发现新的、更高效的算法。它本质上是一个「算法发现者」。它通过不断地生成、变异和测试新的代码版本,并根据性能(一个易于验证的指标)进行筛选,最终「进化」出超越人类设计的解决方案。
过拟合 (Overfitting): 在传统机器学习中,过拟合通常是个负面词汇,指模型过度学习了训练数据的细节和噪声,以至于它在训练数据上表现完美,但在新的、未见过的数据(测试数据)上表现很差。而在这里,作者指出对于「科学发现」这类任务,目标就是解决一个特定的、悬而未决的问题。因此,AI 所有的努力都集中在这一个问题上,不存在「泛化到新问题」的需求。这种「过拟合」到一个单一难题上,恰恰是解决该问题的最有效方式。
一旦你了解了验证的不对称性,你就会发现它无处不在。一个我们可以衡量的一切都将被解决的世界,是多么令人兴奋。我们很可能会看到一条智能的锯齿状前沿 (jagged edge of intelligence),即 AI 在可验证的任务上要聪明得多,因为解决这些任务要容易得多。这是一个值得期待的、激动人心的未来。
番外
RL 带给我的人生教训
在过去一年里,我成了强化学习的铁杆粉丝,醒着的大部分时间都在琢磨它,这无意中让我领悟了一个关于人生的重要道理。
强化学习中有一个重要概念叫「策略一致」:与其模仿他人的成功轨迹,不如亲自采取行动,并从环境的奖励中学习。显然,模仿学习在初期对于将成功率从零提升起来很有用,但一旦模型能走出合理的轨迹,我们通常就会避免模仿学习,因为要想充分发挥模型自身的(与人类不同)优势,最好的方式就是只从它自己的轨迹中学习。一个广为接受的例子是,相比简单地在人类撰写的思维链上进行监督微调,强化学习是训练语言模型解决数学应用题更好的方法。
同样地,在生活中,我们首先通过模仿学习(学校)来完成起步,这是非常合理的。但即使在我毕业之后,我仍习惯于研究别人如何取得成功并试图模仿他们。有时这确实有效,但最终我意识到,我永远无法完全复制他人的能力,因为他们是在发挥自己的优势,而这些优势我并不具备。这可能是一位研究者在 YOLO 实验上比我更成功,因为他们自己构建了代码库而我却没有;或者一个非 AI 的例子是,一名足球运动员利用我所没有的力量来保持控球。
「在策略学习」的启示是:想要超越老师,就必须走出自己的路,并承担环境带来的风险与回报。举例来说,有两件事我比一般研究员更乐在其中:(1) 大量阅读数据,(2) 做消融实验以理解系统中各个组件的作用。有一次收集数据集时,我花了几天时间阅读数据,并为每位人类标注者提供个性化反馈;最终数据质量极佳,我也因此对要解决的任务有了深刻洞察。今年年初,我花了一个月,回头对之前在深度研究中「拍脑袋」做出的每个决定逐一进行消融。那段时间投入巨大,但通过实验,我学到了关于哪种 RL 更有效的独到见解。不仅追随自己的热情更令人满足,如今我也感觉正走在为自己和研究开辟一个更具优势的生态位的道路上。
简而言之,模仿是好的,起步阶段必须如此。但一旦完成起步,若想超越老师,就必须进行「在策略」强化学习,并立足于自己的长处与短处 :)

(文:Founder Park)