


AniCrafter 通过引入 3DGS Avatar + 背景视频作为条件控制视频扩散模型,将指定角色在任意场景下的动画化任务转换为视频修复任务,从而实现更加鲁棒和泛用的动画化效果。

项目地址:
https://myniuuu.github.io/AniCrafter/
代码链接:
https://github.com/MyNiuuu/AniCrafter
论文作者:
Muyao Niu (https://myniuuu.github.io/)
作者单位:
Shanghai Artificial Intelligence Laboratory, The University of Tokyo
研究方向:
AIGC,视频扩散模型,视频生成

▲ AniCrafter 能够将指定角色根据动作序列无缝插入到任意场景

研究背景
近年来,基于视频扩散模型(Video Diffusion Models, VDMs),已有多项工作提出了通过动作序列(如 DWPose)将人物图像动画化的方法。这些方法通常依赖于基础的结构条件,因此在遇到大幅动作时容易产生明显的结构扭曲或时序不一致的问题。
此外,大多数方法默认输入图像中的背景固定或与参考图像共享相同的环境。这些限制使得现有方法在需要多变动态背景与极端动作的开放域场景中难以泛化。
此外,另一种技术路径采用显式 3D 高斯泼溅(3DGS)建模。与基于 VDMs 的方法不同,这类方法首先从参考图重建 3DGS 人体模型,然后根据 SMPLX 等 3D 姿态变换进行驱动并渲染为视频。
这些方法在面对极端动作时仍可保持良好的结构和多视角一致性, 但重建结果通常缺乏高频细节,并难以提供真实的非刚体运动,比如头发或衣物。

核心思想
基于对上述两种范式的分析,我们提出了 AniCrafter,能够根据给定的动作序列实现角色在任意场景下的动画化。我们的核心思想是将 3DGS 人体建模范式的优势引入扩散建模型,从而实现高质量且鲁棒的生成效果。
具体来说,驱动后的 3DGS 人体模型能提供一致的 3D 结构信息和姿态对齐的外观信息。因此,给定一张人物图像,我们首先重建其 3D 人体模型,并根据动作序列进行驱动与渲染,接着将渲染结果与背景视频融合。
融合结果与 GT 视频的差别集中在人物区域的退化,例如高频纹理缺失或非刚体动态缺失(如头发、衣物)。
基于这一简单但有效的控制信号,扩散模型的任务便转化为“修复(restoration)任务”:1)精细化 3D 人体渲染中退化的人物外观;2)合成逼真的非刚体动态如头发摆动和衣物飘动。
基于这一表征,我们精心设计了数据处理流程和模型架构,充分利用预训练模型中的先验知识,从而达到了更好更鲁棒的生成效果。

方法概览
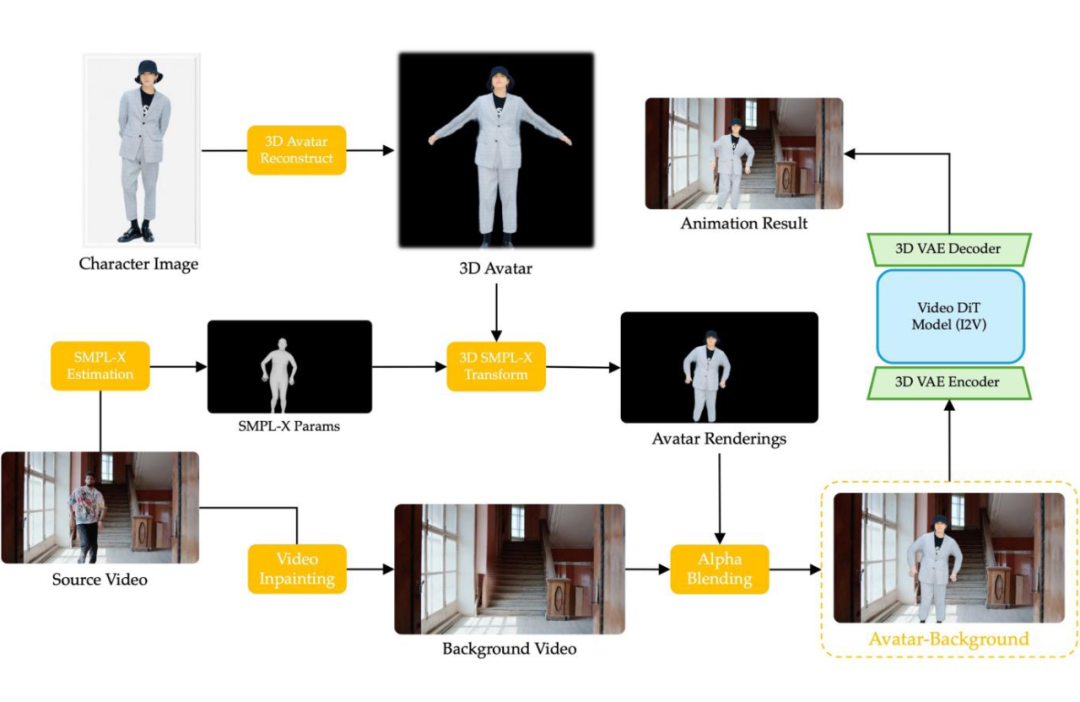
对于源视频序列,我们首先解析出人体掩膜,并利用该掩膜生成背景视频。接着,我们从视频中估计出 SMPLX 参数。
随后,我们根据人物图像重建 3DGS 人体模型,并利用 SMPLX 参数进行驱动,获取渲染结果。然后将渲染结果与背景视频进行融合,生成最终的“人物-背景”视频。最后,我们将参考图像、SMPLX 视频以及“人物-背景”视频一同输入到扩散模型中,生成最终输出结果。
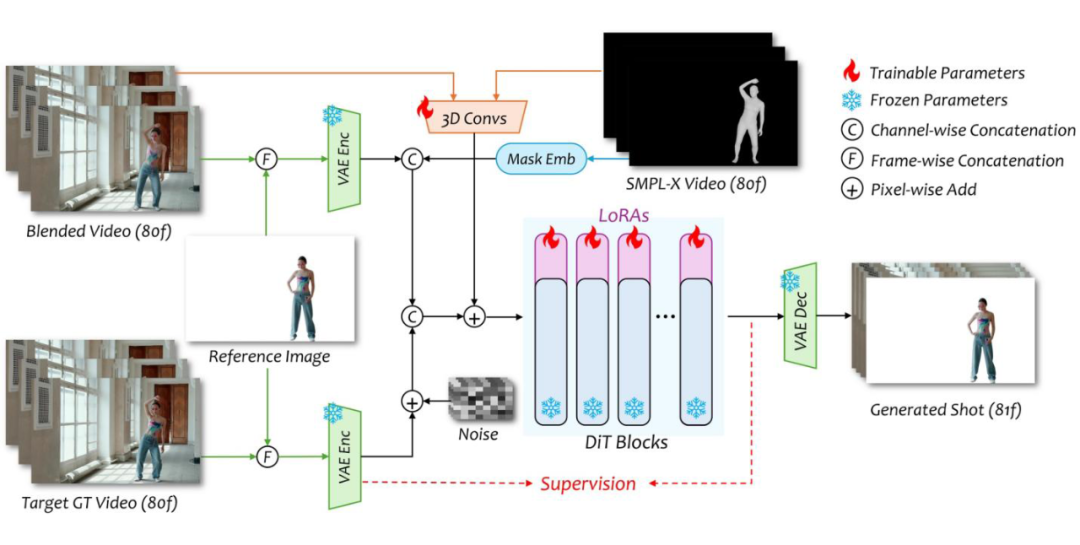
扩散模型网络架构利用 SMPLX 视频与“人物-背景”视频作为控制条件,在 Wan2.1-I2V-14B 的基础上加入 LoRA 模块进行微调。

实验效果

与之前方法不同,AniCrafter 可以实现跨场景,跨角色的动画化,从而大大拓宽方法的应用场景与泛化性。更多结果可参照项目主页。

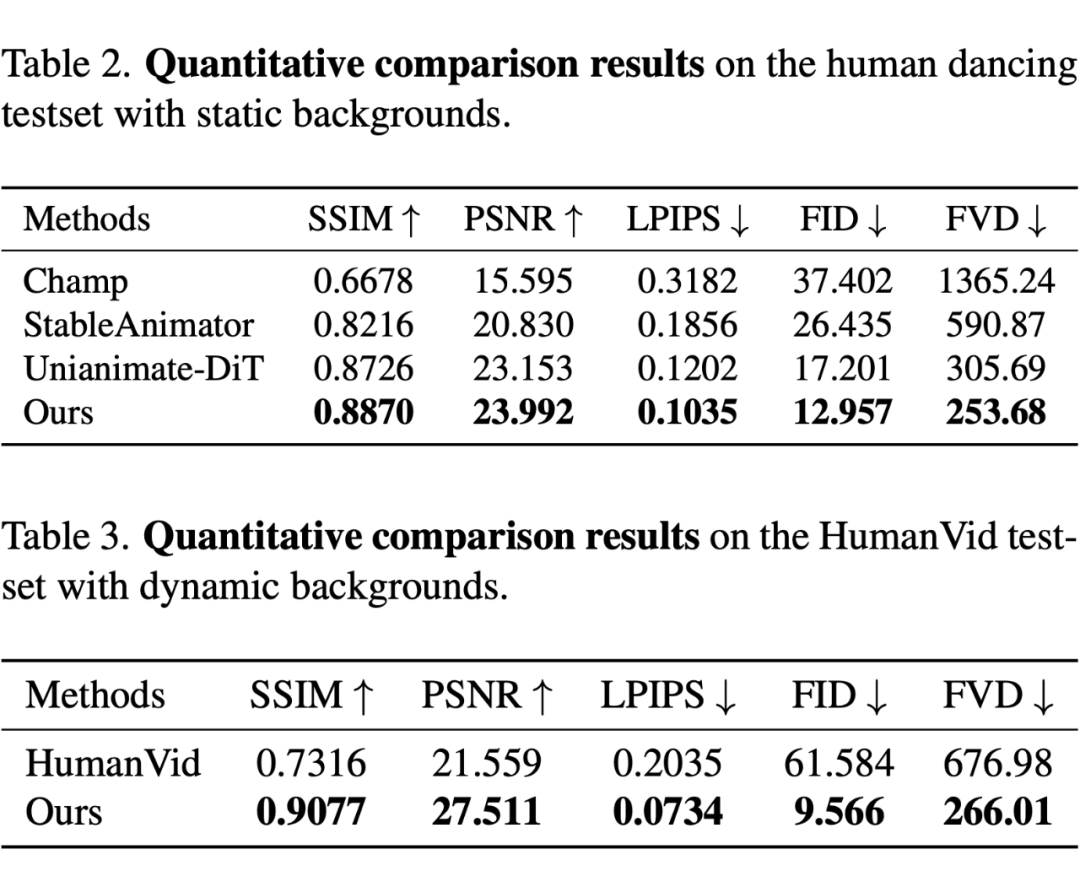
在 Human Dancing 数据集和 HumanVid 数据上的比较试验证明本方法在视觉效果和重建质量上优于现有方法。
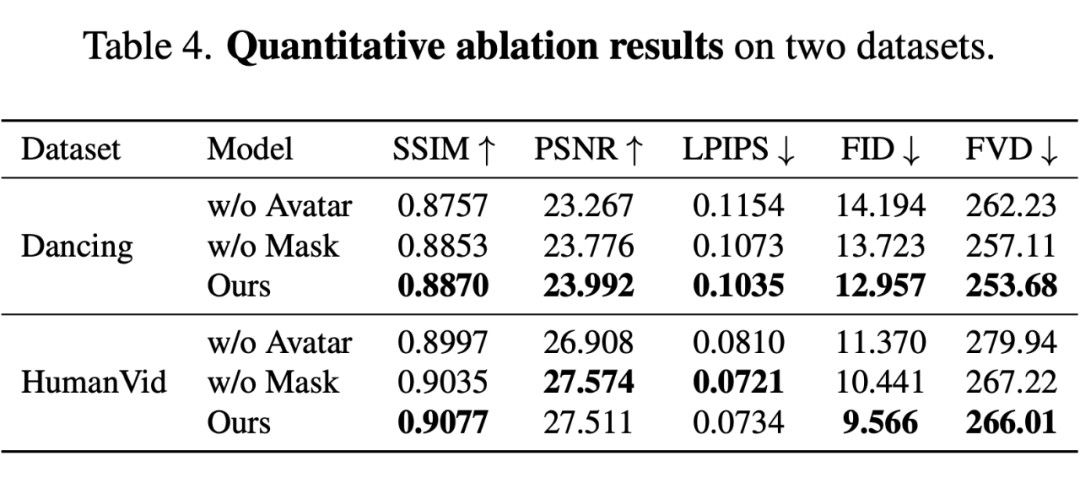
在两个数据集上的消融实验证明了模型各个模块的有效性。

总结一下
我们提出了 AniCrafter,实现了任意角色在任意场景下根据给定的动作序列的动画化。该模型通过引入 3DGS Avatar + 背景视频作为条件控制视频扩散模型,将指定角色在任意场景下的动画化任务转换为视频修复任务,从而实现更加鲁棒和泛用的角色动画化。
模型主页:
https://myniuuu.github.io/AniCrafter/
代码链接:
https://github.com/MyNiuuu/AniCrafter
(文:PaperWeekly)