


过去一年,生成式推荐 (Generative Recommendations, GRs) 在工业界取得了显著的进展。GRs 利用大语言模型 (Large Language Models, LLMs) 的序列建模与推理能力,大幅度提升了推荐效果。
基于 LLMs 的 GRs 正形成一种全新的范式,展现出取代传统依赖复杂特征的推荐系统的潜力。本文全面综述该领域,旨在推动进一步研究,涵盖基础概念、工业应用及未来方向。

论文标题:
GR-LLMs: Recent Advances in Generative Recommendation Based on Large Language Models
论文链接:
https://arxiv.org/pdf/2507.06507

背景
大语言模型概论
大预言模型 (Large Language Models, LLMs) 通过大量文本数据进行训练,具备强大的自然语言处理能力。它们通过预测下一个 token 来优化根据过去序列来预测下一个 token 的概率。
LLMs 早期主要用于处理文本数据,现已扩展到支持多模态数据 (如图像、音频、视频),能够完成多种序列生成任务。
传统推荐系统
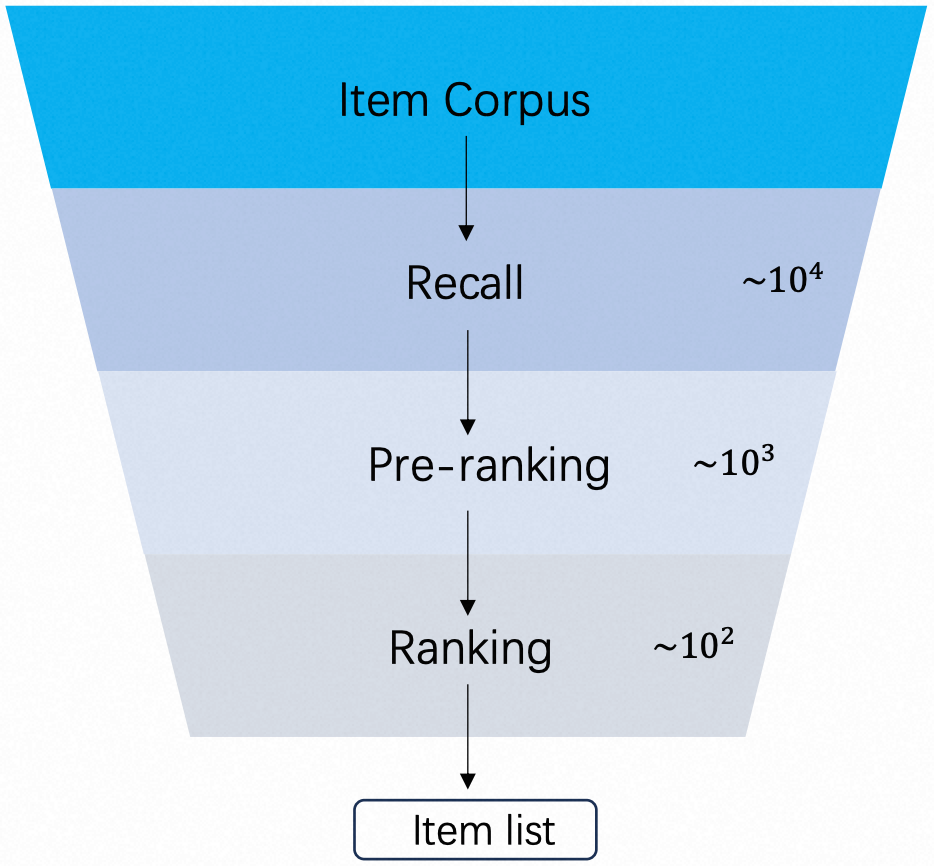
传统推荐系统通常采用多阶段级联架构 (召回 Recall、预排序 Pre-ranking、排序 Ranking) 以平衡效率与精度。
但是,各阶段独立运行,上一阶段的推荐效果是下一阶段推荐效果的上限,制约了整体性能。已有研究虽然尝试增强阶段间的交互,但是依旧遵循多阶段级联架构。
近期,生成式推荐 (Generative Recommendations, GRs) 作为一种统一的端到端架构崭露头角,展现出提升推荐效果的潜力。

从机器学习, 到深度学习, 再到生成式推荐
推荐系统通过分析用户画像和历史行为,推断用户兴趣,从而推荐商品、短视频、新闻等内容。推荐系统在现代数字环境中得到了广泛应用,是帮助用户应对海量信息的重要工具,对电商、社交网络、流媒体和新闻聚合平台的成功起到了关键作用。
推荐系统的发展经历了三个主要阶段:
-
基于机器学习的推荐 (Machine Learning-based Recommendation, MLR)。
-
基于深度学习的推荐 (Deep Learning-based Recommendation, DLR)。
-
生成式推荐 (GRs)。
MLR 依赖传统算法和人工特征工程,常用协同过滤和矩阵分解等技术,存在数据稀疏和冷启动问题。DLR 利用深度神经网络自动学习复杂特征,虽然效果更好,但是模型效率与扩展性仍有提升空间。
总的来说,MLR 和 DLR 依赖人工特征工程和复杂模型结构,存在难以解释、维护成本高、适应性差等问题。
近年来,大语言模型的兴起推动了 GRs 的发展。GRs 利用 Transformer 等架构,通过自回归方式预测用户行为,在序列建模和语义理解方面表现出色。
相关研究如 UCSD 的 SASRec、Meta 的 HSTU、谷歌的 TIGER、快手的 OneRec、美团的 MTGR 和 UNM 等。这些模型不断优化模型结构,提升了工业级推荐系统的效果。
LLM-based GR 与 MLR 和 DLR 有本质不同。其优势包括:
-
提升可解释性,增强用户信任。
-
支持创新和多样性推荐。
-
简化系统设计,减少人工特征工程。
-
大语言模型的扩展性有望进一步提升推荐性能。
本文旨在梳理 LLM-based GRs 的基础概念、应用场景及工业落地中的挑战,并展望未来研究方向,助力该领域的进一步发展。

生成式推荐: 召回, 排序, 端到端
从 2024 到 2025 年,许多公司和高校提出了多种生成式推荐系统,在工业场景中取得了显著成效。目前,GR 在在线推荐中的应用主要分为两类: 一是将生成模型集成到传统系统的召回或排序模块中; 二是直接用于端到端推荐。
召回
召回指的是推荐系统从候选物品库中筛选出相关物品。LLMs 在召回阶段的应用有三种方法:基于提示词 (prompt-based)、基于标记 (token-based) 和基于表征 (embedding-based)。
-
Prompt-based 方法通过设计 prompt,利用预训练大模型生成召回结果。如华为的 LLMTreeRec。
-
Token-based 方法将用户行为序列转化为 token 序列,将召回任务视为下一个 token 预测任务。如 Meta 的 HSTU 和快手的 KuaiFormer。
-
Embedding-based 方法使用 LLMs 生成物品表征,再结合传统深度学习方法。如西湖大学的 MoRec。
排序
排序是决定推荐结果质量和多样性的关键环节,通常作用于召回后的较小候选集上,可使用更复杂的模型。相比 DLR,LLMs 能通过用户行为序列直接建模用户偏好,减少特征工程,且具备更强的扩展性。
LLMs 在排序中的应用分为两类:生成式架构和混合架构。
-
生成式架构直接利用 LLMs 进行评分预测,如 Meta 的 HSTU 和小红书的 GenRank。
-
混合架构将 LLMs 生成的表征作为补充特征融入传统推荐系统,如快手的 LEARN、字节跳动的 HLLM 和美团的 SRP4CTR。
值得注意的是,美团的 MTGR 继承了生成式框架,同时保留了交叉特征,属于生成式架构和混合架构的结合。
端到端
端到端推荐指的是直接根据用户历史行为输出推荐结果。它与召回任务的区别在于是否具备排序能力并替代传统推荐链路。端到端推荐可以避免传统方法中的误差传播和目标不一致的问题。
工业应用中,快手的 OneRec 和 OneSug,美团的 EGA-V2 等模型通过生成式方法提升排序能力,实现全链路替代多阶段级联架构。
学术研究也探索了基于 DPO (Direct Preference Optimization)、负样本增强和自回放机制的强化学习方法,以提升推荐质量,为端到端推荐的发展提供了新思路。

生成式推荐:链路,推理效率,冷启动与世界知识
链路
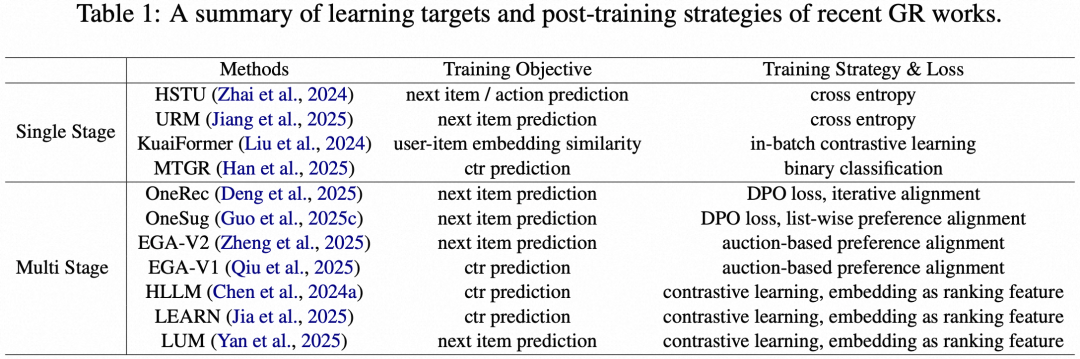
GRs 的核心问题在于如何设计训练方法和目标以适配推荐任务。现有方法有单阶段训练和多阶段训练。
单阶段训练:模型在一个阶段完成推荐任务, 通常专注于召回或排序。如 Meta 的 HSTU、阿里巴巴的 URM 通过预测下一个物品进行召回,美团的 MTGR 则通过 CTR (Click-Through Rate) 预测实现排序。
多阶段训练:分为预训练和微调两阶段。根据微调方式不同,又分为:
-
基于表征的微调:如字节跳动的 HLLM、快手的 LEARN 通过对比学习生成用户和物品表征,再用于传统排序模型。
-
基于模型的微调:如快手的 OneRec 和 OneSug 等采用端到端框架,结合强化学习提升排序能力,适用于视频推荐和广告场景。
推理效率
GRs 在工业场景部署中面临推理延迟高的挑战。可以通过以下方式优化。
-
序列压缩:如小红书的 GenRank,美团的 DFGR,快手的 KuaiFormer 通过缩短序列长度降低计算成本。
-
模型结构优化:Meta 的 HSTU 和美团 RecFormer 改进了注意力机制,将复杂度从二次降低到线性。
-
专用加速技巧:谷歌的 TIGER 生成语义 ID 减少词表大小, HSTU 的 M-FALCON 和美团的 MTGR 通过掩码策略提升排序效率。这些方法有效提升了 GRs 的实时性和可扩展性。
冷启动和世界知识
冷启动问题指的是在用户或物品数据不足时生成准确推荐的问题。LLMs 可以通过两种方式缓解这一问题:
信息增强:利用 LLMs 生成的表征或知识补充推荐数据,如蚂蚁的 SAID 和清华的 CSRec;
模型推理:直接基于 LLMs 学习到的模式生成推荐结果,如 Meta 的 LLM-Rec。
LLM 的“世界知识”来源于其大规模,多领域的训练数据。Llama 和 Qwen 这些开源大模型中的“世界知识”能有效辅助推荐系统在冷启动阶段学习用户-物品交互模式。

此外,结合多模态数据 (如图像、视频、语音) 并通过对比学习对齐不同模态表示,是提升推荐性能的重要途径。
例如,小红书的 NoteLLM-2 利用视觉信息提升笔记推荐效果,TALKPLAY 通过音频和语义信息进行音乐推荐,InteraRec 从网页截图中提取商品信息。这些方法可将多模态信号融入现有生成式推荐系统,有效缓解冷启动问题。

未来方向
尺度定律
尺度定律 (Scaling law) 是大语言模型参数扩展的理论基础。传统深度学习推荐在扩展时存在两大问题:1)无法高效处理长用户行为序列;2)随着候选物品增加,训练和推理成本呈线性增长,导致费用过高。
GRs 虽已观察到一些扩展效应,但模型规模仍较小,大尺寸模型的性能提升尚未充分验证。未来,增大模型规模并处理更长的行为序列是提升推荐能力的重要方向,同时需探索高效的推理方法以满足实际应用需求。
数据清洗
训练数据质量对大语言模型性能影响显著。在 GRs 中,如何进行数据清洗仍研究不足。推荐系统的训练数据不仅包含物品 ID,还包含多模态的多源辅助信息。
由于行为序列缺乏类似自然语言中的语法校验机制,如何评估其有效性、实现质量感知的数据筛选,并建立与数据质量相关的动态训练策略,是提升推荐效果的重要方向。
统一模型
LLMs 的核心目标是通过单一模型和提示切换实现多语言任务的通用处理。近年来,LLMs 的发展推动了统一框架的研究,支持多种模态输入输出。
例如,Meta 的 HSTU 模型已能统一召回与排序,阿里巴巴的 URM 进一步提出生成式推荐可作为通用推荐学习器,支持多场景、多目标推荐等任务。
未来,通过生成式大模型实现推荐与搜索的统一,动态理解用户指令并提供个性化结果,将成为信息检索的重要研究方向。

本文全面综述了基于 LLM-based GR 技术,重点介绍了其基本原理、应用场景及工业落地中的关键考量。同时,分析了其在多种场景下的能力,展望了未来发展方向,旨在为研究人员提供参考,推动该领域的持续进步。
(文:PaperWeekly)