

今天是2025年7月13日,星期日,北京,晴
我们今天接着昨天的Agent和Graph结合问题,趁热打铁,看看Agent执行中的数据合成问题。
讲两个比较落地的工具,一个是ACEBench的合成思路,一个是面向RAG场景的多步骤智能体数据合成工具TaskCraft
数据合成很重要,可以多关注。
一、Agent工具调用数据合成思路ACEBench
大模型工具调用的能力,核心还是取决于大模型的训练数据和训练方式,但最核心的还是如何获取大规模真实的工具调用数据。
这就自然会涉及到数据合成的问题。
正如,最近kimi-k2-blog(https://moonshotai.github.io/Kimi-K2/)中提到的Large-Scale Agentic Data Synthesis for Tool Use Learning。
为了教会模型复杂的工具使用能力,受ACEBench启发,开发了一个全面的流程,可以大规模模拟现实世界的工具使用场景,其涉及到数百个包含数千种工具(包括真实的MCP工具和合成工具)的领域,并生成了数百个拥有不同工具集的Agent,所有任务均基于评分标准,从而实现一致的评估,代理与模拟环境和用户代理交互,创建逼真的多轮工具使用场景。
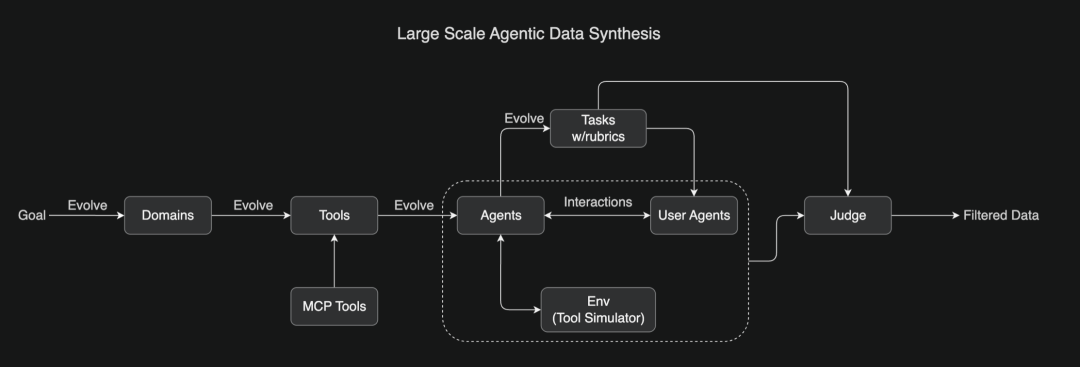
LLM评委根据任务评分标准评估模拟结果,筛选出高质量的训练数据,这种可扩展的流程能够生成多样化、高质量的数据,为大规模拒绝采样和强化学习奠定基础。
既然说到,ACEBench,那么就来看下具体的步骤,因为前者并没有具体说实现细节。
ACEBench《ACEBench: Who Wins the Match Point in Tool Usage?》(https://github.com/ACEBench/ACEBench,https://arxiv.org/pdf/2501.12851),涵盖8大领域和68个子领域,包括技术、金融、娱乐、社会、健康、文化、环境等,共包含4,538个API,中英文均可。
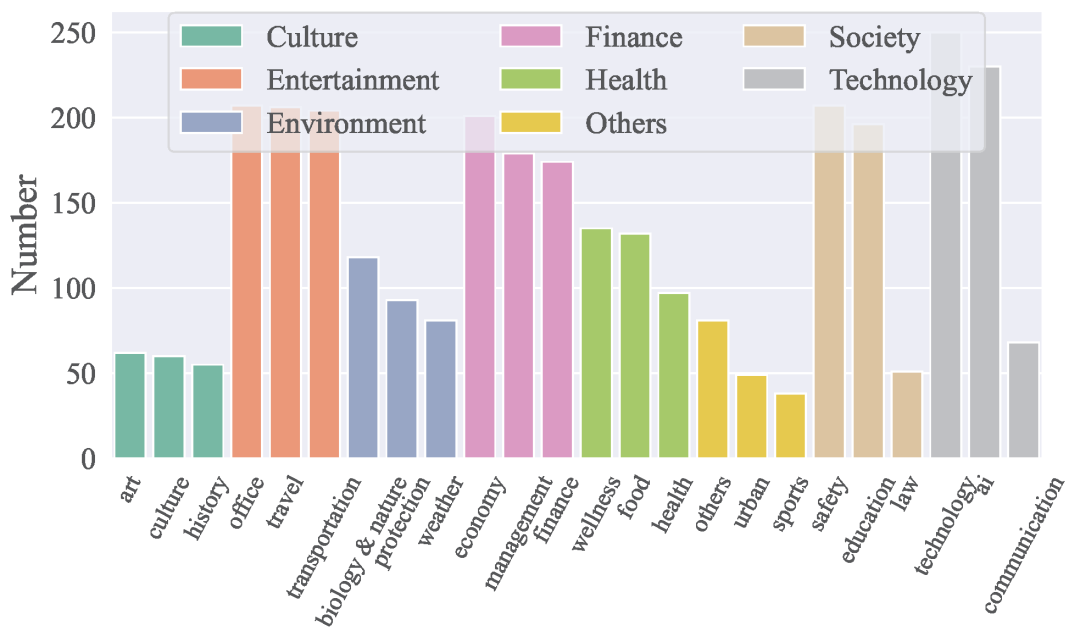
其将数据分为三类:Normal(基础场景)、Special(特殊场景)和Agent(多智能体交互场景)。
Normal数据评估模型在基础场景下的工具调用能力;
Special数据评估模型在指令不完整或参数错误等特殊情况下的表现;
Agent数据通过多智能体交互模拟真实世界的多轮对话,评估模型的复杂任务处理能力。
数据生成通过API合成和对话生成两个主要步骤完成,并经过多阶段的质量验证,包括自动化规则检查和人工专家审核。
可以看下其实现方式:
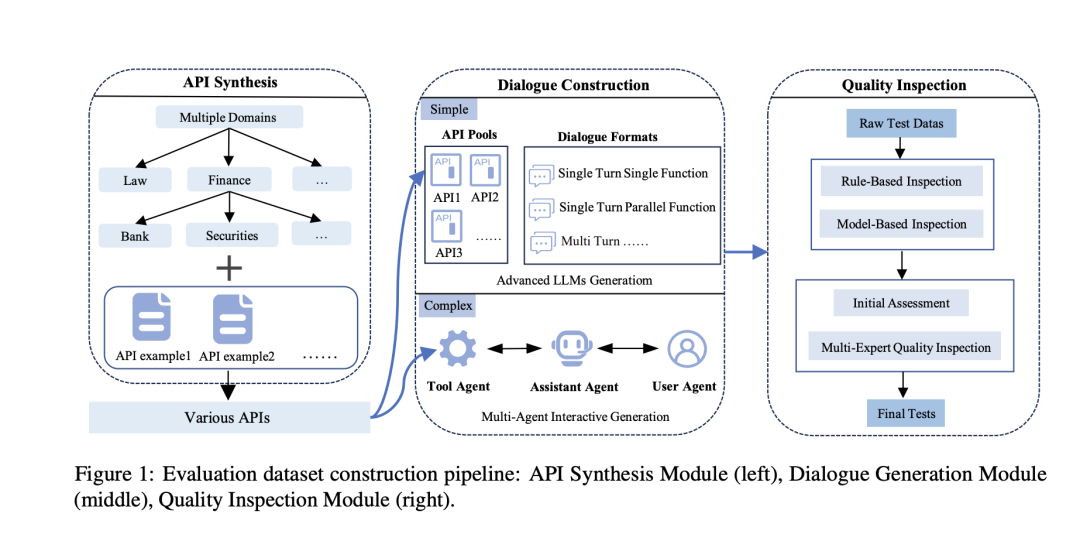
整个过程分为三个核心模块:API合成模块(左)、对话生成模块(中)和质量检测模块(右),具体的例子如下:

1)API合成模块(API Synthesis Module),目标是生成覆盖多领域、功能稳定的API池,为后续对话构建提供工具基础。
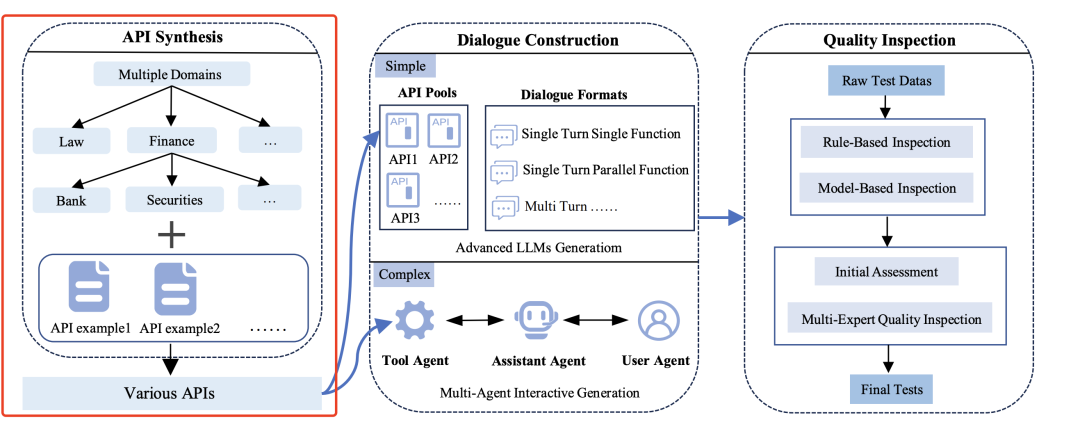
首先,基于现实场景中的API(如天气查询、金融计算等)提取参数结构和功能描述,确保合成API的实用性。
然后,进行分层上下文树构建,通过自演化方法生成API层次结构,例如,根节点包括领域分类(如“金融”“医疗”);子节点包括具体功能(如“汇率计算”“病历查询”);然后根据技术文档迭代补充参数约束(如正则表达式校验、枚举值范围)。
最终,生成4,538个中英文API,覆盖8大领域(技术、金融、文化等)和68个子类。
2)对话生成模块(Dialogue Generation Module),目标是基于API池生成多样化的对话数据,模拟真实用户交互场景。
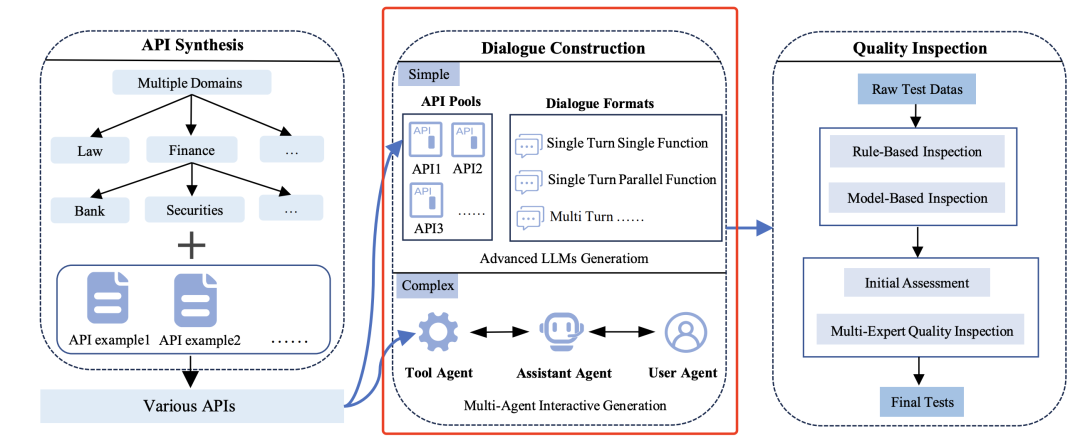
包括两个实现策略,单论对话和多轮对话,其中:
首先,单轮对话采用模板化生成,例如用户直接请求“查询北京天气”,系统调用WeatherAPI并返回结果。
其次,多轮对话通过多智能体(用户、助手、工具)角色扮演生成动态交互,此外,再做特殊场景处理,例如相似API混淆,随机插入功能相近的API(如“航班查询”与“火车票查询”),测试模型的分辨能力;个性化数据,结合用户画像(如“素食主义者”)生成参数偏好。
3)质量检测模块(Quality Inspection Module),目标是通过自动化与人工审核结合,确保数据合规性和逻辑合理性。
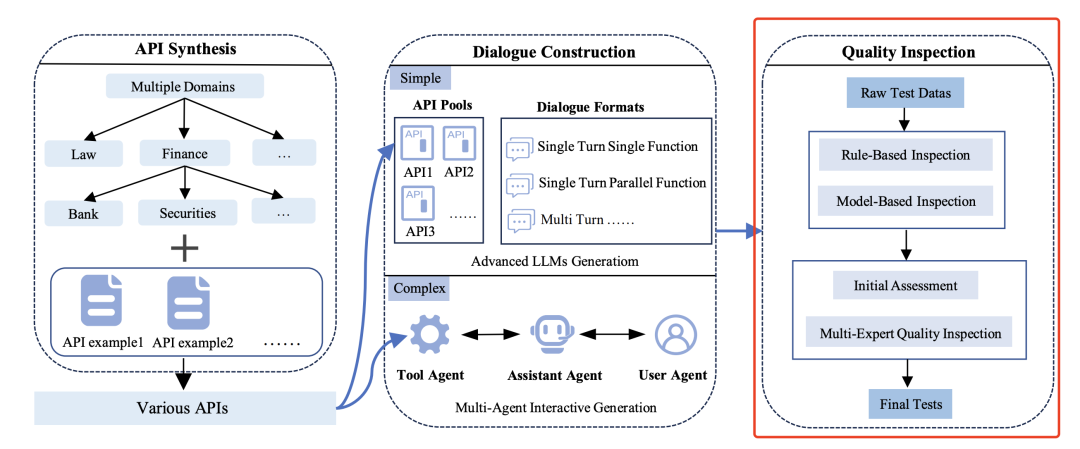
整个检测流程比较重要,包括自动化规则检、模型辅助验证以及专家人工复审几个环节。其中:
自动化规则检测,主要检测API定义完整性验证参数名称、类型、必填字段是否缺失;对话逻辑校验确保工具调用与用户指令匹配(如用户请求“转账”时必须包含金额参数)。
模型辅助验证,使用LLM检测语义错误(如指令歧义),采用投票机制过滤低质量数据。
其实,还有另一个是工作,
二、面向RAG场景的多步骤数据合成思路TaskCraft
更进一步的,回到文档问答,尤其是RAG这种场景,那么,就可以看另一个框架,TaskCraft。
《TaskCraft: Automated Generation of Agentic Tasks》,https://arxiv.org/abs/2506.10055,https://github.com/OPPO-PersonalAI/TaskCraft,用于生成可扩展难度、支持多工具且可验证的代理任务及其执行轨迹,例如生成那种需要多步骤推理才能回答问题的RAG任务。
从实现上看,包括两种模式:
深度扩展(Depth-based Extension)模式通过递归生成依赖关系,构建多步骤任务;宽度扩展(Width-based Extension)模式通过合并多个子任务,生成需要并行解决的任务。
但无论是怎么模式,都需要做文档解析,也就是直接处理 PDF/HTML/URL 等异构数据源。
来看下基本流程,
1、原子任务生成
从PDF/HTML/URL/Image 中提取内容以生成原子任务。
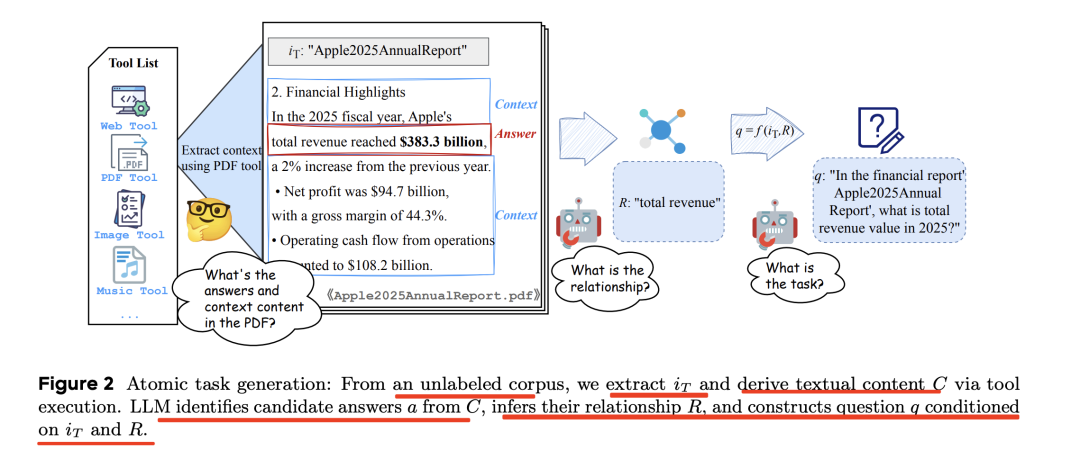
从这个语料库中,提取iT并通过工具执行文本内容C。例如,浏览、PDF和图片理解工具产生网页标题、PDF名称和图片路径,从提取文本内容C用于答案采样,提示大模型(LLM)从C中识别关键候选答案a并推断它们与C的关系R,最终根据iT和R构建问题q。
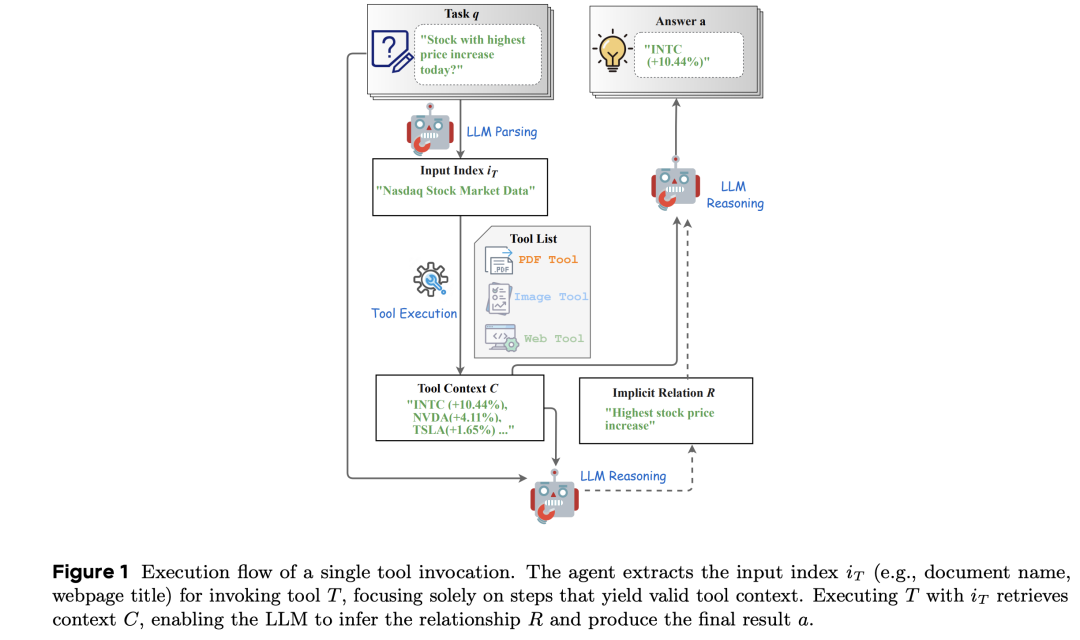
里面的prompt如下:

例如,对应的输出:
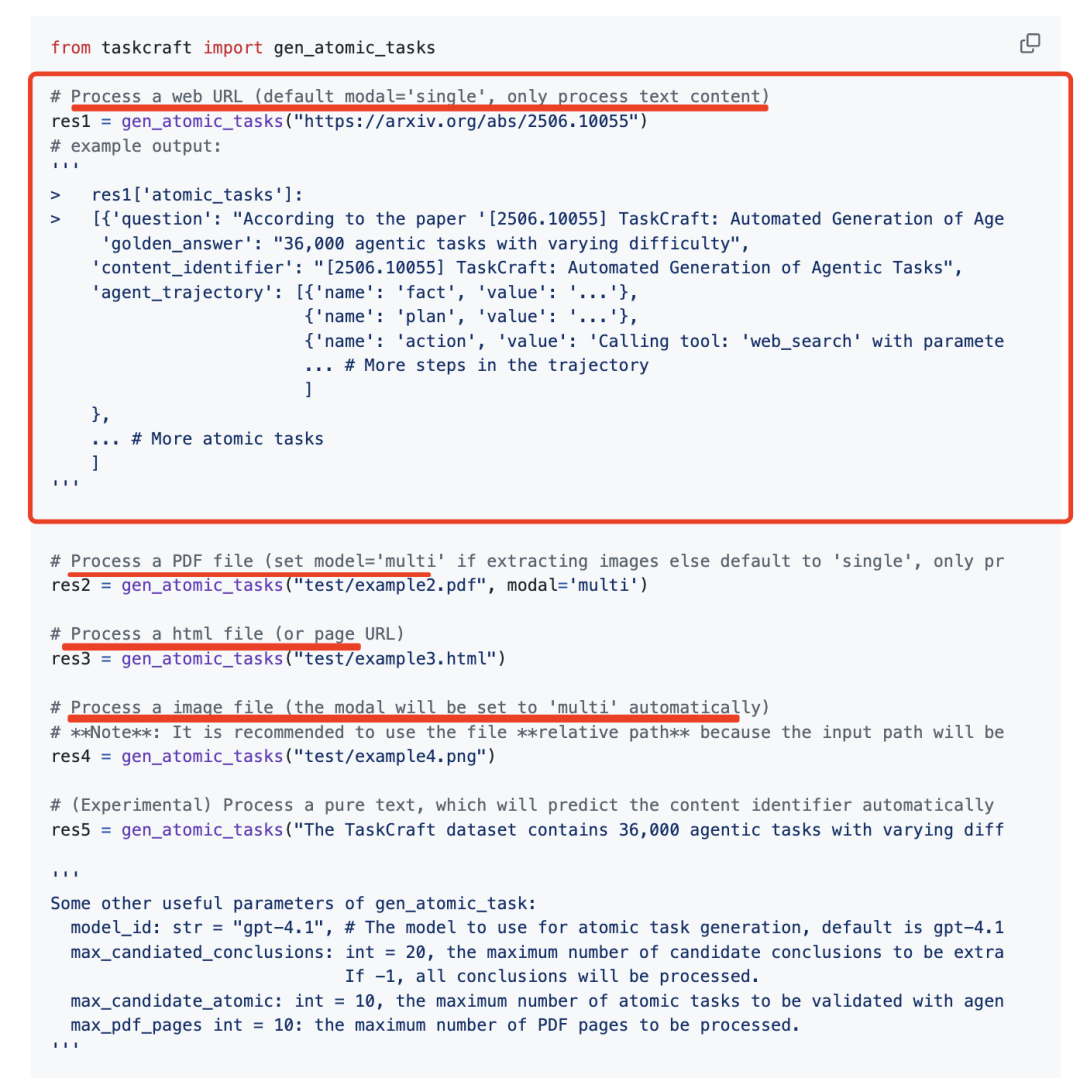
2、基于深度的扩展
从原子任务生成多跳推理任务,构建需要多次顺序工具执行的任务,其中每一步都依赖于前一步的输出。
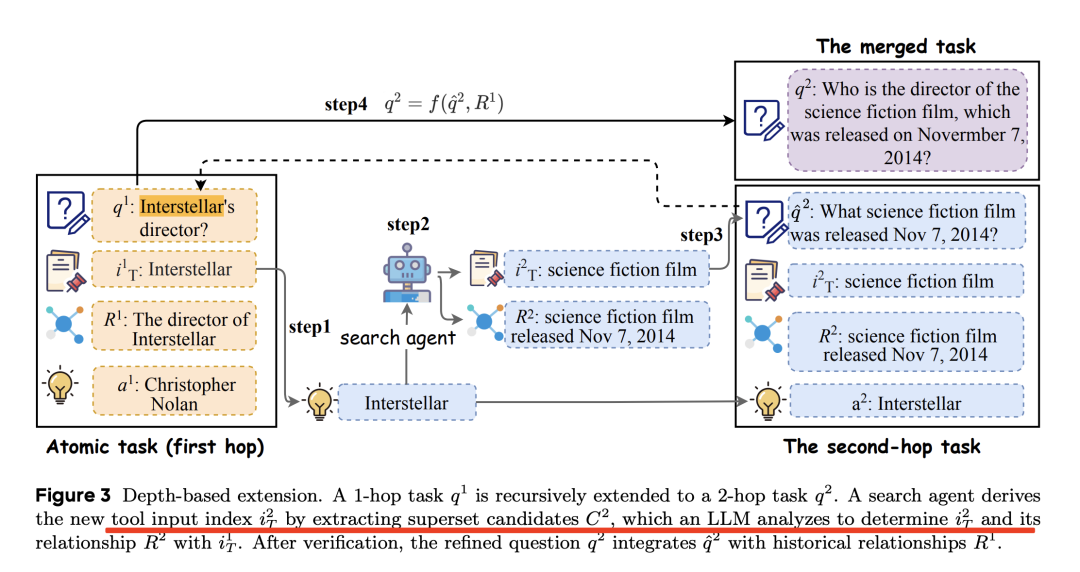
例如,对应的输出:

3、基于宽度的扩展
基于宽度的扩展的目的是生成一个新任务,该任务需要分解成多个子任务来完成。为了简便起见,对于两个子任务q1→a1和q2→a2,组合任务q宽度可以表示为(qwidth=q1+q2)a1+a2,
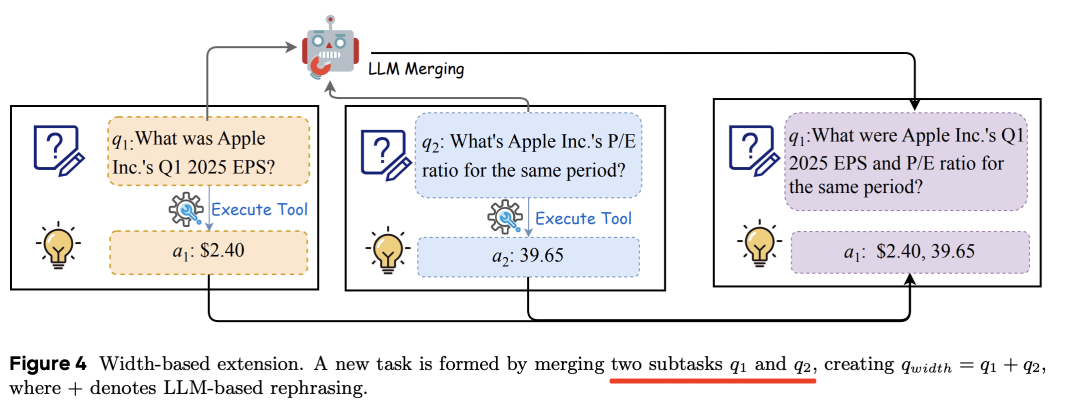
例如,对应的输出:

参考文献
1、https://github.com/ACEBench/ACEBench
2、https://arxiv.org/abs/2506.10055
(文:老刘说NLP)