

逻辑分块、智能体、子图、计划执行、评估等等,带你从零开始打造一个强大的 RAG 系统!
引言
想打造一个生产就绪的 RAG(Retrieval-Augmented Generation)系统?那可不是件简单的事儿!得一步步来,精心设计,反复迭代。咱们得先把数据收拾干净,然后试试不同的分块策略——逻辑分块和传统分块都得试试,找到最适合你的场景。接着,还要匿名化数据,减少那些模型“胡思乱想”的情况(也就是所谓的 hallucination)。为了让检索更精准,可以用子图(subgraphs)来聚焦最相关的信息,过滤掉那些没用的“噪音”。在检索层之上,还得加个计划和执行系统,靠 LLM(大语言模型)驱动,像是派了个智能体,边干边学,决定下一步咋走。最后,系统生成回答后,咱们得用一堆指标来评估它表现如何。
这篇博客会带你从头开始,手把手教你用 LangChain、LangGraph 和 RAGAS(评估框架)构建一个完整的 RAG 系统,模拟真实世界的挑战,展示开发者在打造 RAG 机器人时会遇到的实际问题和解决方案。所有代码都可以在 GitHub 仓库里找到:https://github.com/FareedKhan-dev/complex-RAG-guide
目录
-
• 理解 RAG 管道 -
• 环境配置 -
• 数据拆分(传统/逻辑) -
• 数据清洗 -
• 数据重组 -
• 数据向量化 -
• 创建上下文检索器 -
• 过滤无关信息 -
• 查询重写 -
• 链式推理(Chain-of-Thought, COT) -
• 相关性和事实核查 -
• 测试 RAG 管道 -
• 使用 LangGraph 可视化 RAG 管道 -
• 子图方法与提炼验证 -
• 创建检索与提炼子图 -
• 创建减少幻觉的子图 -
• 创建并测试计划执行器 -
• 重新规划逻辑 -
• 创建任务处理器 -
• 输入问题的匿名化/去匿名化 -
• 编译与可视化 RAG 管道 -
• 测试最终管道 -
• 使用 RAGAS 评估 -
• 总结
理解 RAG 管道
在动手写代码之前,咱们先来“画”一张 RAG 管道的蓝图,方便后面逐步拆解每个部分。
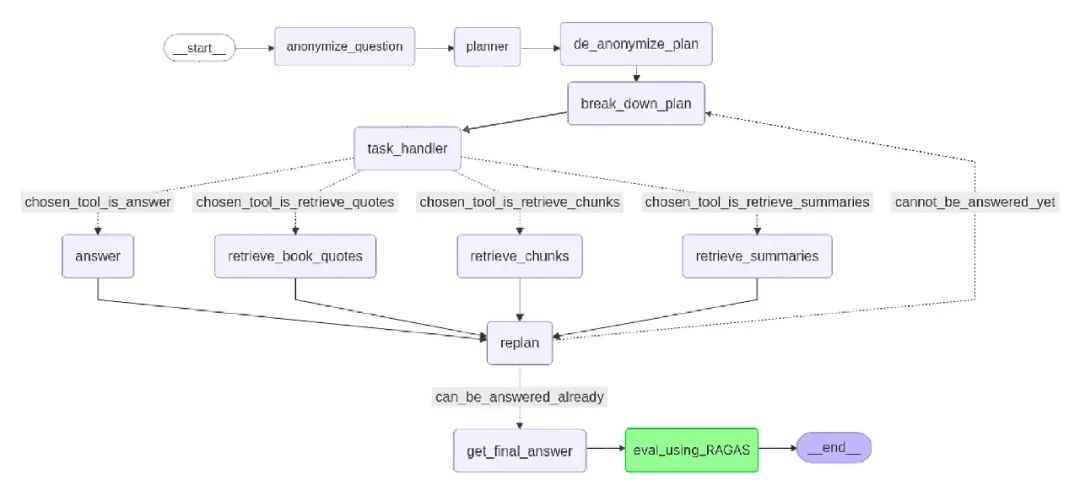
首先,调用 anonymize_question,把具体名字(比如“Harry Potter”“Voldemort”)替换成占位符(Person X, Villain Y),避免 LLM 因预训练知识产生偏见。
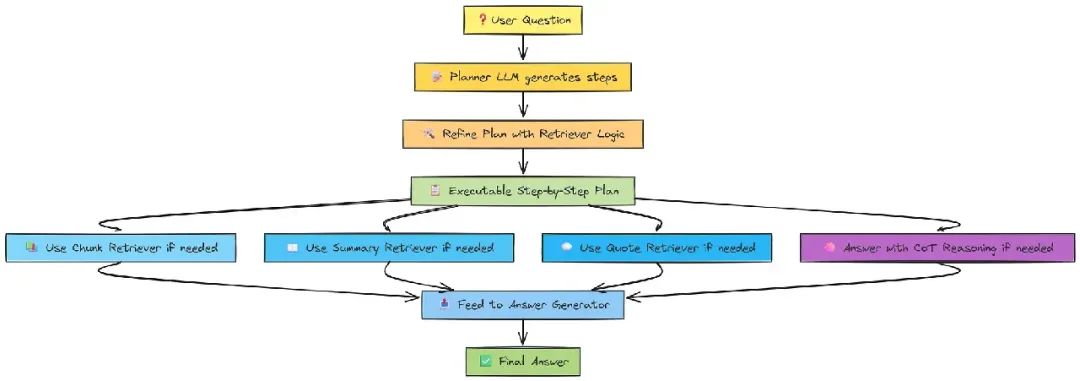
接着,规划器(planner)会制定一个高层次策略。比如,问题“How did X defeat Y?”可能会被规划为:
-
1. 识别 X 和 Y -
2. 找到他们的最终对决 -
3. 分析 X 的行动 -
4. 起草答案
然后,de_anonymize_plan 把占位符换回原名,让计划更具体。更新后的计划交给 break_down_plan,将每个高层次步骤拆成具体任务。
task_handler 再为每个任务选择合适的工具,比如:
-
• chosen_tool_is_retrieve_quotes:找具体对话或引用 -
• chosen_tool_is_retrieve_chunks:获取通用信息和上下文 -
• chosen_tool_is_retrieve_summaries:总结整章内容 -
• chosen_tool_is_answer:当足够上下文时直接回答
用完检索工具(retrieve_book_quotes、retrieve_chunks 或 retrieve_summaries)后,新信息会送去 replan,它会根据进展、目标和新输入决定是否更新计划。
这个循环(task_handler -> 工具 -> replan)一直重复,直到系统判断问题可以直接回答(can_be_answered_already)。然后,get_final_answer 综合所有证据生成最终回答。
最后,用 eval_using_RAGAS 检查回答的准确性和来源忠实度。如果通过,流程以 __end__ 结束,输出一个经过验证、推理充分的答案。
环境配置
LangChain、LangGraph 这些模块加起来是个完整的架构,所以咱们得按需导入,避免一下子加载太多东西,方便学习。
第一步是设置环境变量,存放 API 密钥等敏感信息:
# 设置 OpenAI API 密钥(用于 OpenAI LLMs)
os.environ["OPENAI_API_KEY"] = os.getenv('OPENAI_API_KEY')
# 设置 Together API 密钥(用于 Together AI 模型)
os.environ["TOGETHER_API_KEY"] = os.getenv('TOGETHER_API_KEY')
# 获取 Groq API 密钥(用于 Groq LLMs)
groq_api_key = os.getenv('GROQ_API_KEY')这里用了两个 AI 模型提供商:Together AI 提供开源模型,成本低,性价比高;Groq 能生成结构化输出。如果你的 prompt 模板写得好,能引导 LLM 输出结构化结果,甚至可以不用 Groq,完全依赖 Together AI 或 Hugging Face 本地模型,毕竟 LangChain 生态功能很强大。
数据拆分(传统/逻辑)
要开始,得先有数据集。RAG 管道通常处理大量原始文本数据,比如 PDF、CSV 或 TXT 格式。但这些数据往往需要大量清洗,每个文件可能得用不同方法。

咱们用《哈利·波特》系列作为数据集,因为它很贴近现实场景,包含各种字符串格式问题。你可以从这里下载书。下载后,就可以开始拆分文档了。
定义 PDF 路径:
book_path = "Harry Potter - Book 1 - The Sorcerers Stone.pdf"在预处理或清洗数据之前,最重要的一步是按逻辑和传统方式拆分文档。
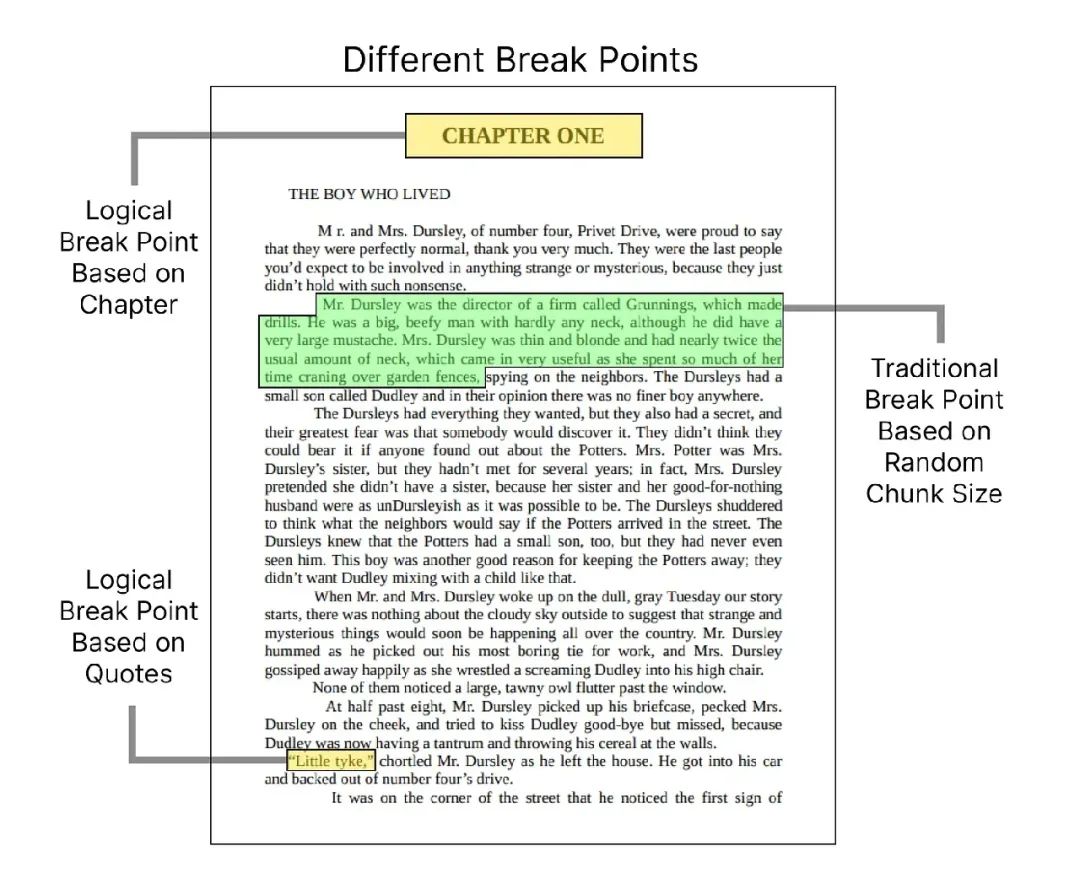
对于《哈利·波特》,按章节拆分是最自然的逻辑方式。咱们先把 PDF 加载成一个完整的文本:
import re
import PyPDF2
from langchain.docstore.document import Document
with open(book_path, 'rb') as pdf_file:
pdf_reader = PyPDF2.PdfReader(pdf_file)
full_text = " ".join([page.extract_text() for page in pdf_reader.pages])然后,用正则表达式按章节标题拆分:
chapter_sections = re.split(r'(CHAPTER\s[A-Z]+(?:\s[A-Z]+)*)', full_text)为每个章节创建 Document 对象:
chapters = []
for i in range(1, len(chapter_sections), 2):
chapter_text = chapter_sections[i] + chapter_sections[i + 1]
doc = Document(page_content=chapter_text, metadata={"chapter": i // 2 + 1})
chapters.append(doc)
print(f"总共提取的章节数: {len(chapters)}")输出:
总共提取的章节数: 17除了章节,引用(quotes)也是重要的断点,因为它们往往概括了关键信息。对于金融文档,表格或财务报表可能是关键断点。咱们再按引用拆分:
quote_pattern_longer_than_min_length = re.compile(rf'"(.{{{min_length},}}?)"', re.DOTALL)
book_quotes_list = []
min_length = 50
for doc in tqdm(chapters, desc="提取引用"):
content = doc.page_content
found_quotes = quote_pattern_longer_than_min_length.findall(content)
for quote in found_quotes:
quote_doc = Document(page_content=quote)
book_quotes_list.append(quote_doc)
print(f"总共提取的引用数: {len(book_quotes_list)}")
print(f"随机引用内容: {book_quotes_list[5].page_content[:500]}...")输出:
总共提取的引用数: 1337
随机引用内容: Most mysterious. And now, over to JimMcGuffin ...最后,用传统的分块方法:
from langchain.text_splitter import RecursiveCharacterTextSplitter
chunk_size = 1000
chunk_overlap = 200
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size, chunk_overlap=chunk_overlap, length_function=len
)
document_splits = text_splitter.split_documents(documents)
print(f"分块后的文档数: {len(document_splits)}")输出:
分块后的文档数: 612这样,我们按章节、引用和传统分块三种方式拆分了数据,接下来开始清洗。
数据清洗
看看第一个章节的内容,发现字母之间有额外的空格(\t 制表符),得用正则表达式清理掉:
print(f"第一个章节内容: {chapters[0].page_content[:500]}...")输出:
第一个章节内容: CHAPTER ONE
THE BOY WHO LIVED
M
r. and M r s. D u r s l e y , o f n u m b e r ...清理制表符:
tab_pattern = re.compile(r'\t')
for doc in chapters:
doc.page_content = tab_pattern.sub(' ', doc.page_content)
print(f"清理后的第一个章节内容: {chapters[0].page_content[:500]}...")输出:
清理后的第一个章节内容: CHAPTER ONE
THE BOY WHO LIVED
M
r. and Mrs. Dursley, of number f ...还有换行符和多余空格,得继续处理:
multiple_newlines_pattern = re.compile(r'\n\s*\n')
word_split_newline_pattern = re.compile(r'(\w)\n(\w)')
multiple_spaces_pattern = re.compile(r' +')
for doc in chapters:
page_content = multiple_newlines_pattern.sub('\n', doc.page_content)
page_content = word_split_newline_pattern.sub(r'\1\2', page_content)
page_content = page_content.replace('\n', ' ')
page_content = multiple_spaces_pattern.sub(' ', page_content)
doc.page_content = page_content
print(f"最终清理的章节内容: {chapters[15].page_content[:500]}...")输出:
最终清理的章节内容:
THE BOY WHO LIVED
Mr. and Mrs. Dursley, of number f ...对传统分块数据也做同样处理:
for doc in document_splits:
doc.page_content = tab_pattern.sub(' ', doc.page_content)
doc.page_content = multiple_newlines_pattern.sub('\n', doc.page_content)
doc.page_content = word_split_newline_pattern.sub(r'\1\2', doc.page_content)
doc.page_content = multiple_spaces_pattern.sub(' ', doc.page_content)分析数据:
chapter_word_counts = [len(doc.page_content.split()) for doc in chapters]
max_words = max(chapter_word_counts)
min_words = min(chapter_word_counts)
average_words = sum(chapter_word_counts) / len(chapter_word_counts)
print(f"章节最大词数: {max_words}")
print(f"章节最小词数: {min_words}")
print(f"章节平均词数: {average_words:.2f}")输出:
章节最大词数: 6343
章节最小词数: 2915
章节平均词数: 4402.18章节词数都在 LLM 上下文窗口限制内,暂时没问题。
数据重组
引用数据已经很精简,但章节数据量大,包含很多不必要的对话。可以用 LLM 总结章节,保留关键信息:

from langchain.prompts import PromptTemplate
template = """Write an extensive summary of the following:
{text}
SUMMARY:"""
summarization_prompt = PromptTemplate(
template=template,
input_variables=["text"]
)
chain = load_summarize_chain(deepseek_v3, chain_type="stuff", prompt=summarization_prompt)
chapter_summaries = []
for chapter in chapters:
summary = chain.invoke([chapter])
cleaned_text = re.sub(r'\n\n', '\n', summary["output_text"])
doc_summary = Document(page_content=cleaned_text, metadata=chapter.metadata)
chapter_summaries.append(doc_summary)这里用 stuff 链类型,因为章节最大词数(6K)在 DeepSeek V3 的上下文窗口内。如果数据超限,可以用 map_reduce 或 refine 链类型。
数据向量化
用 ML2 BERT 模型(32k 上下文窗口)向量化数据,用 FAISS 存储:
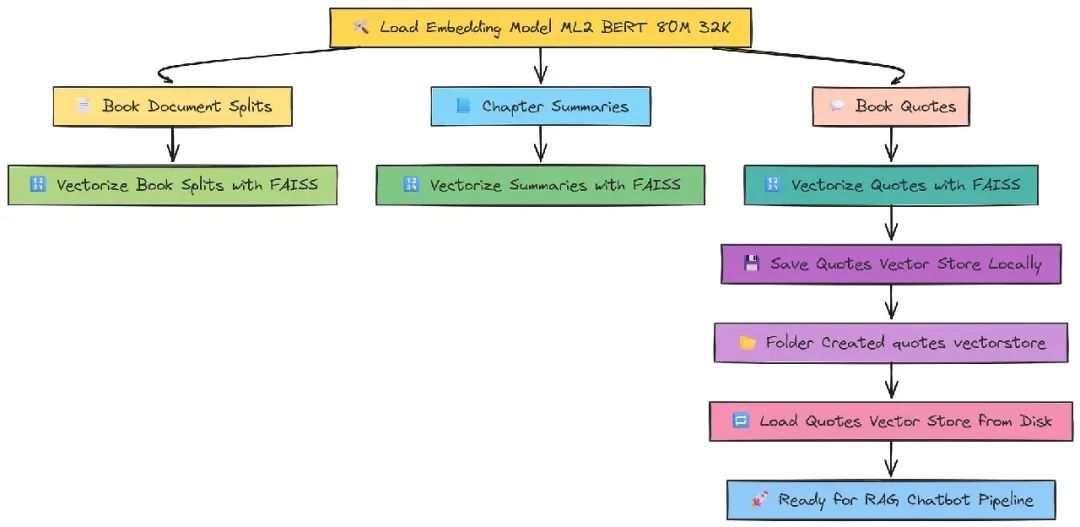
from langchain.vectorstores import FAISS
book_splits_vectorstore = FAISS.from_documents(document_splits, m2_bert_80M_32K)
chapter_summaries_vectorstore = FAISS.from_documents(chapter_summaries, m2_bert_80M_32K)
quotes_vectorstore = FAISS.from_documents(book_quotes_list, m2_bert_80M_32K)
quotes_vectorstore.save_local("quotes_vectorstore")可以加载本地向量数据库:
quotes_vectorstore = FAISS noctua2_bert_80M_32K, allow_dangerous_deserialization=True)创建上下文检索器
为每个数据集(章节摘要、引用、传统分块)创建检索器:
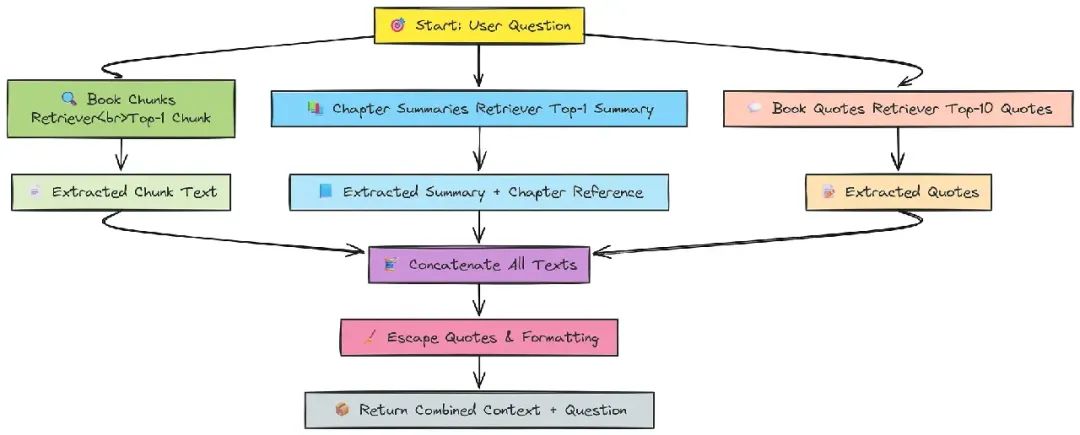
book_chunks_retriever = book_splits_vectorstore.as_retriever(search_kwargs={"k": 1})
chapter_summaries_retriever = chapter_summaries_vectorstore.as_retriever(search_kwargs={"k": 1})
book_quotes_retriever = quotes_vectorstore.as_retriever(search_kwargs={"k": 10})
defretrieve_context_per_question(state):
question = state["question"]
docs = book_chunks_retriever.get_relevant_documents(question)
context = " ".join(doc.page_content for doc in docs)
docs_summaries = chapter_summaries_retriever.get_relevant_documents(state["question"])
context_summaries = " ".join(f"{doc.page_content} (Chapter {doc.metadata['chapter']})"for doc in docs_summaries)
docs_book_quotes = book_quotes_retriever.get_relevant_documents(state["question"])
book_qoutes = " ".join(doc.page_content for doc in docs_book_quotes)
all_contexts = context + context_summaries + book_qoutes
all_contexts = all_contexts.replace('"', '\\"').replace("'", "\\'")
return {"context": all_contexts, "question": question}过滤无关信息
用 LLM 过滤无关内容:
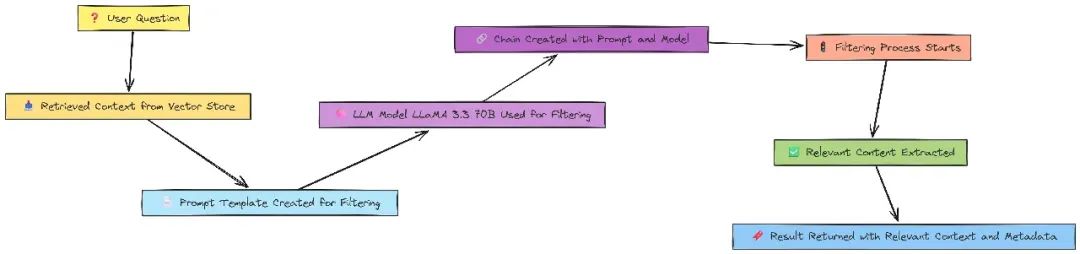
keep_only_relevant_content_prompt_template = """
You receive a query: {query} and retrieved documents: {retrieved_documents} from a vector store.
You need to filter out all the non-relevant information that does not supply important information regarding the {query}.
Your goal is to filter out the non-relevant information only.
You can remove parts of sentences that are not relevant to the query or remove whole sentences that are not relevant to the query.
DO NOT ADD ANY NEW INFORMATION THAT IS NOT IN THE RETRIEVED DOCUMENTS.
Output the filtered relevant content.
"""
classKeepRelevantContent(BaseModel):
relevant_content: str = Field(description="The relevant content from the retrieved documents that is relevant to the query.")
keep_only_relevant_content_prompt = PromptTemplate(
template=keep_only_relevant_content_prompt_template,
input_variables=["query", "retrieved_documents"],
)
keep_only_relevant_content_llm = ChatTogether(
temperature=0,
model_name="meta-llama/Llama-3.3-70B-Instruct-Turbo-Free",
api_key=together_api_key,
max_tokens=2000
)
keep_only_relevant_content_chain = (
keep_only_relevant_content_prompt
| keep_only_relevant_content_llm.with_structured_output(KeepRelevantContent)
)
defkeep_only_relevant_content(state):
question = state["question"]
context = state["context"]
input_data = {"query": question, "retrieved_documents": context}
print("保留仅相关内容...")
output = keep_only_relevant_content_chain.invoke(input_data)
relevant_content = output.relevant_content
relevant_content = "".join(relevant_content)
relevant_content = relevant_content.replace('"', '\\"').replace("'", "\\'")
return {"relevant_context": relevant_content, "context": context, "question": question}查询重写
用户查询可能不够明确,需用 LLM 重写:
class RewriteQuestion(BaseModel):
rewritten_question: str = Field(description="优化后的查询")
explanation: str = Field(description="重写说明")
rewrite_question_string_parser = JsonOutputParser(pydantic_object=RewriteQuestion)
rewrite_llm = ChatGroq(
temperature=0,
model_name="llama3-70b-8192",
groq_api_key=groq_api_key,
max_tokens=4000
)
rewrite_prompt_template = """You are a question re-writer that converts an input question to a better version optimized for vectorstore retrieval.
Analyze the input question {question} and try to reason about the underlying semantic intent / meaning.
{format_instructions}
"""
rewrite_prompt = PromptTemplate(
template=rewrite_prompt_template,
input_variables=["question"],
partial_variables={"format_instructions": rewrite_question_string_parser.get_format_instructions()},
)
question_rewriter = rewrite_prompt | rewrite_llm | rewrite_question_string_parser
defrewrite_question(state):
question = state["question"]
print("重写查询...")
result = question_rewriter.invoke({"question": question})
new_question = result["rewritten_question"]
return {"question": new_question}链式推理(COT)
用链式推理(Chain-of-Thought, COT)提高回答质量:
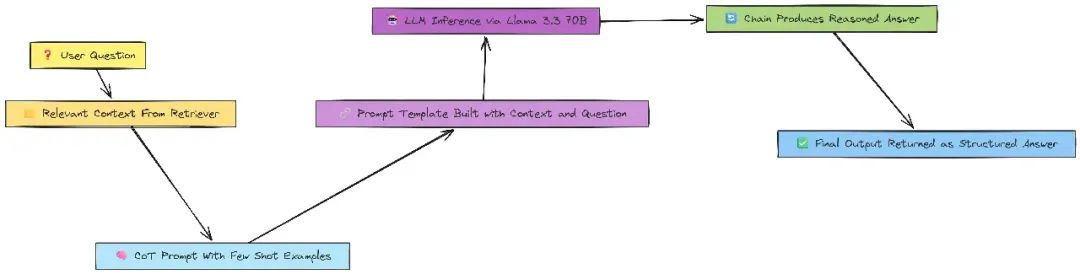
class QuestionAnswerFromContext(BaseModel):
answer_based_on_content: str = Field(description="基于上下文的回答")
question_answer_from_context_llm = ChatTogether(
temperature=0,
model_name="meta-llama/Llama-3.3-70B-Instruct-Turbo-Free",
api_key=together_api_key,
max_tokens=2000
)
question_answer_cot_prompt_template = """
Chain-of-Thought Reasoning Examples
Example 1
Context: Mary is taller than Jane. Jane is shorter than Tom. Tom is the same height as David.
Question: Who is the tallest person?
Reasoning:
Mary > Jane
Jane < Tom → Tom > Jane
Tom = David
So: Mary > Tom = David > Jane
Final Answer: Mary
...
Context: {context}
Question: {question}
"""
question_answer_from_context_cot_prompt = PromptTemplate(
template=question_answer_cot_prompt_template,
input_variables=["context", "question"],
)
question_answer_from_context_cot_chain = (
question_answer_from_context_cot_prompt
| question_answer_from_context_llm.with_structured_output(QuestionAnswerFromContext)
)
defanswer_question_from_context(state):
question = state["question"]
context = state["aggregated_context"] if"aggregated_context"in state else state["context"]
input_data = {"question": question, "context": context}
print("从检索上下文回答问题...")
output = question_answer_from_context_cot_chain.invoke(input_data)
answer = output.answer_based_on_content
print(f'回答(未检查幻觉): {answer}')
return {"answer": answer, "context": context, "question": question}相关性和事实核查
进一步检查文档相关性和事实依据:
class Relevance(BaseModel):
is_relevant: bool = Field(description="文档是否相关")
explanation: str = Field(description="相关性说明")
is_relevant_json_parser = JsonOutputParser(pydantic_object=Relevance)
is_relevant_llm = ChatGroq(
temperature=0,
model_name="llama3-70b-8192",
groq_api_key=groq_api_key,
max_tokens=2000
)
is_relevant_content_prompt = PromptTemplate(
template=is_relevant_content_prompt_template,
input_variables=["query", "context"],
partial_variables={"format_instructions": is_relevant_json_parser.get_format_instructions()},
)
is_relevant_content_chain = is_relevant_content_prompt | is_relevant_llm | is_relevant_json_parser
defis_relevant_content(state):
question = state["question"]
context = state["context"]
input_data = {"query": question, "context": context}
print("判断文档相关性...")
output = is_relevant_content_chain.invoke(input_data)
if output["is_relevant"]:
print("文档相关。")
return"relevant"
else:
print("文档不相关。")
return "not relevant"事实核查:
class is_grounded_on_facts(BaseModel):
grounded_on_facts: bool = Field(description="回答是否基于事实")
is_grounded_on_facts_llm = ChatTogether(
temperature=0,
model_name="meta-llama/Llama-3.3-70B-Instruct-Turbo-Free",
api_key=together_api_key,
max_tokens=2000
)
is_grounded_on_facts_prompt_template = """You are a fact-checker that determines if the given answer {answer} is grounded in the given context {context}...
"""
is_grounded_on_facts_prompt = PromptTemplate(
template=is_grounded_on_facts_prompt_template,
input_variables=["context", "answer"],
)
is_grounded_on_facts_chain = (
is_grounded_on_facts_prompt
| is_grounded_on_facts_llm.with_structured_output(is_grounded_on_facts)
)
defgrade_generation_v_documents_and_question(state):
context = state["context"]
answer = state["answer"]
question = state["question"]
grounded = is_grounded_on_facts_chain.invoke({"context": context, "answer": answer}).grounded_on_facts
ifnot grounded:
print("回答是幻觉。")
return"hallucination"
print("回答基于事实。")
can_be_answered = can_be_answered_chain.invoke({"question": question, "context": context})["can_be_answered"]
if can_be_answered:
print("问题可以完全回答。")
return"useful"
else:
print("问题无法完全回答。")
return "not_useful"测试 RAG 管道
测试一个简单问题:

init_state = {"question": "who is fluffy?"}
context_state = retrieve_context_per_question(init_state)
relevant_content_state = keep_only_relevant_content(context_state)
is_relevant_content_state = is_relevant_content(relevant_content_state)
answer_state = answer_question_from_context(relevant_content_state)
final_answer = grade_generation_v_documents_and_question(answer_state)
print(answer_state["answer"])输出:
检索相关分块...
检索相关章节摘要...
保留仅相关内容...
判断文档相关性...
文档相关。
从检索上下文回答问题...
回答(未检查幻觉): Fluffy is a three-headed dog.
检查回答是否基于事实...
回答基于事实。
判断问题是否完全回答...
问题可以完全回答。
Fluffy is a three-headed dog.Fluffy 是《哈利·波特》中的三头犬,管道正确识别,说明运行正常。
使用 LangGraph 可视化 RAG 管道
用 LangGraph 可视化管道:
from typing import TypedDict
from langgraph.graph import END, StateGraph
from langchain_core.runnables.graph import MermaidDrawMethod
from IPython.display import display, Image
classQualitativeRetievalAnswerGraphState(TypedDict):
question: str; context: str; answer: str
wf = StateGraph(QualitativeRetievalAnswerGraphState)
for n, f in [("retrieve", retrieve_context_per_question),
("filter", keep_only_relevant_content),
("rewrite", rewrite_question),
("answer", answer_question_from_context)]:
wf.add_node(n, f)
wf.set_entry_point("retrieve")
wf.add_edge("retrieve", "filter")
wf.add_conditional_edges("filter", is_relevant_content, {
"relevant": "answer",
"not relevant": "rewrite"
})
wf.add_edge("rewrite", "retrieve")
wf.add_conditional_edges("answer", grade_generation_v_documents_and_question, {
"hallucination": "answer",
"not_useful": "rewrite",
"useful": END
})
display(Image(wf.compile().get_graph().draw_mermaid_png(draw_method=MermaidDrawMethod.API)))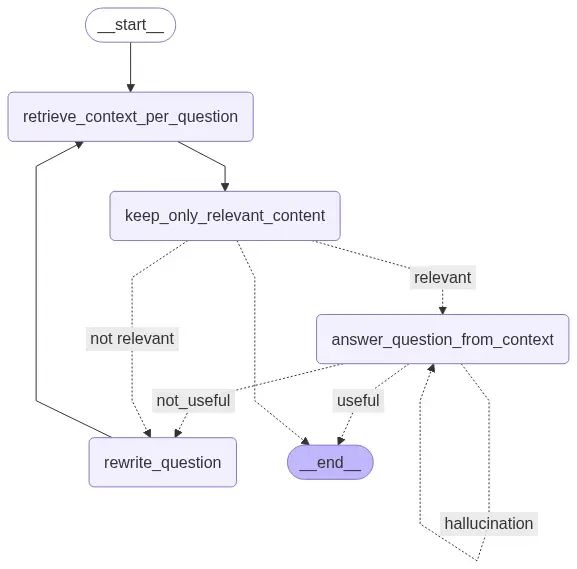
这个图清晰展示了从检索上下文到过滤、查询重写、回答生成和事实核查的流程。
子图方法与提炼验证
复杂任务需要子图(subgraphs)来拆分功能,比如检索、提炼和验证:
is_distilled_content_grounded_on_content_prompt_template = """
You receive some distilled content: {distilled_content} and the original context: {original_context}.
You need to determine if the distilled content is grounded on the original context.
...
"""
classIsDistilledContentGroundedOnContent(BaseModel):
grounded: bool
explanation: str
is_distilled_content_grounded_on_content_json_parser = JsonOutputParser(
pydantic_object=IsDistilledContentGroundedOnContent
)
is_distilled_content_grounded_on_content_prompt = PromptTemplate(
template=is_distilled_content_grounded_on_content_prompt_template,
input_variables=["distilled_content", "original_context"],
partial_variables={"format_instructions": is_distilled_content_grounded_on_content_json_parser.get_format_instructions()},
)
is_distilled_content_grounded_on_content_llm = ChatGroq(
temperature=0,
model_name="llama3-70b-8192",
groq_api_key=groq_api_key,
max_tokens=4000
)
is_distilled_content_grounded_on_content_chain = (
is_distilled_content_grounded_on_content_prompt
| is_distilled_content_grounded_on_content_llm
| is_distilled_content_grounded_on_content_json_parser
)
defis_distilled_content_grounded_on_content(state):
print("判断提炼内容是否基于原始上下文...")
distilled_content = state["relevant_context"]
original_context = state["context"]
input_data = {"distilled_content": distilled_content, "original_context": original_context}
output = is_distilled_content_grounded_on_content_chain.invoke(input_data)
grounded = output["grounded"]
if grounded:
print("提炼内容基于原始上下文。")
return"grounded on the original context"
else:
print("提炼内容不基于原始上下文。")
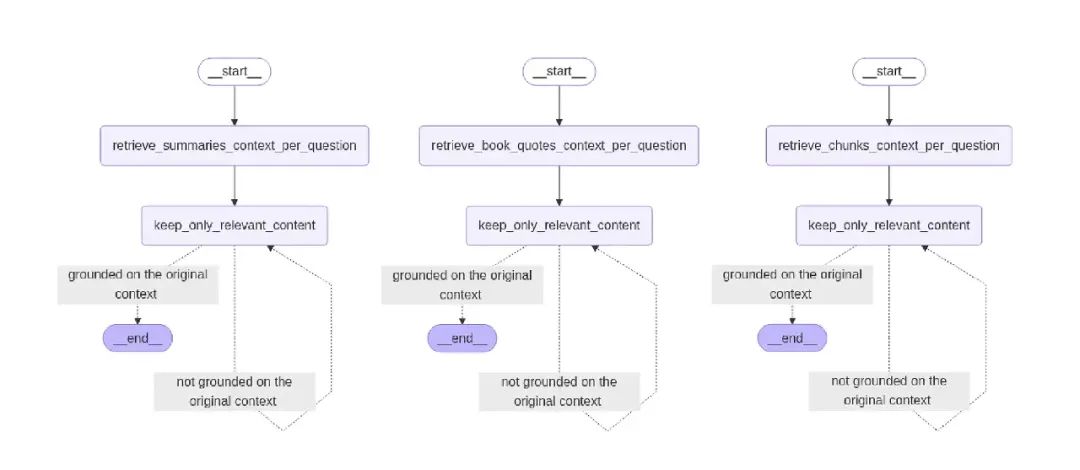
return "not grounded on the original context"创建检索与提炼子图
为章节摘要、引用和传统分块创建单独的检索函数:
def retrieve_chunks_context_per_question(state):
print("检索相关分块...")
question = state["question"]
docs = book_chunks_retriever.get_relevant_documents(question)
context = " ".join(doc.page_content for doc in docs)
context = context.replace('"', '\\"').replace("'", "\\'")
return {"context": context, "question": question}
defretrieve_summaries_context_per_question(state):
print("检索相关章节摘要...")
question = state["question"]
docs_summaries = chapter_summaries_retriever.get_relevant_documents(state["question"])
context_summaries = " ".join(f"{doc.page_content} (Chapter {doc.metadata['chapter']})"for doc in docs_summaries)
context_summaries = context_summaries.replace('"', '\\"').replace("'", "\\'")
return {"context": context_summaries, "question": question}
defretrieve_book_quotes_context_per_question(state):
print("检索相关书籍引用...")
question = state["question"]
docs_book_quotes = book_quotes_retriever.get_relevant_documents(state["question"])
book_qoutes = " ".join(doc.page_content for doc in docs_book_quotes)
book_qoutes_context = book_qoutes.replace('"', '\\"').replace("'", "\\'")
return {"context": book_qoutes_context, "question": question}
classQualitativeRetrievalGraphState(TypedDict):
question: str
context: str
relevant_context: str
defbuild_retrieval_workflow(node_name, retrieve_fn):
graph = StateGraph(QualitativeRetrievalGraphState)
graph.add_node(node_name, retrieve_fn)
graph.add_node("keep_only_relevant_content", keep_only_relevant_content)
graph.set_entry_point(node_name)
graph.add_edge(node_name, "keep_only_relevant_content")
graph.add_conditional_edges(
"keep_only_relevant_content",
is_distilled_content_grounded_on_content,
{
"grounded on the original context": END,
"not grounded on the original context": "keep_only_relevant_content",
},
)
app = graph.compile()
display(Image(app.get_graph().draw_mermaid_png(draw_method=MermaidDrawMethod.API)))
return graph
build_retrieval_workflow("retrieve_chunks_context_per_question", retrieve_chunks_context_per_question)
build_retrieval_workflow("retrieve_summaries_context_per_question", retrieve_summaries_context_per_question)
build_retrieval_workflow("retrieve_book_quotes_context_per_question", retrieve_book_quotes_context_per_question)创建减少幻觉的子图
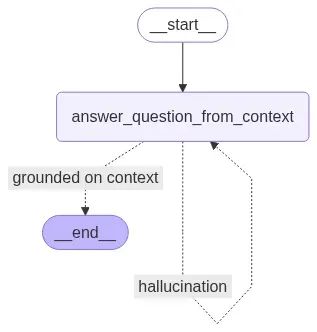
减少幻觉的子图:
def is_answer_grounded_on_context(state):
print("检查回答是否基于事实...")
context = state["context"]
answer = state["answer"]
result = is_grounded_on_facts_chain.invoke({"context": context, "answer": answer})
grounded_on_facts = result.grounded_on_facts
ifnot grounded_on_facts:
print("回答是幻觉。")
return"hallucination"
else:
print("回答基于事实。")
return"grounded on context"
classQualitativeAnswerGraphState(TypedDict):
question: str; context: str; answer: str
wf = StateGraph(QualitativeAnswerGraphState)
wf.add_node("answer", answer_question_from_context)
wf.set_entry_point("answer")
wf.add_conditional_edges("answer", is_answer_grounded_on_context, {
"hallucination": "answer",
"grounded on context": END
})
display(Image(wf.compile().get_graph().draw_mermaid_png(draw_method=MermaidDrawMethod.API)))测试幻觉子图:
question = "who is harry?"
context = "Harry Potter is a cat."
init_state = {"question": question, "context": context}
for output in qualitative_answer_workflow_app.stream(init_state):
for _, value in output.items():
pass
print("--------------------")
print(f'answer: {value["answer"]}')输出:
从检索上下文回答问题...
回答(未检查幻觉): Harry Potter is a cat.
检查回答是否基于事实...
回答基于事实。
--------------------
answer: Harry Potter is a cat.即使上下文错误,系统仍基于上下文回答,说明它不会凭空“捏造”。
创建并测试计划执行器
定义计划执行器:
class PlanExecute(TypedDict):
curr_state: str
question: str
anonymized_question: str
query_to_retrieve_or_answer: str
plan: List[str]
past_steps: List[str]
mapping: dict
curr_context: str
aggregated_context: str
tool: str
response: str
classPlan(BaseModel):
steps: List[str] = Field(description="按顺序执行的步骤")
planner_prompt = """For the given query {question}, come up with a simple step by step plan of how to figure out the answer. ..."""
planner_prompt = PromptTemplate(
template=planner_prompt,
input_variables=["question"],
)
planner_llm = ChatTogether(
temperature=0,
model_name="meta-llama/Llama-3.3-70B-Instruct-Turbo-Free",
api_key=together_api_key,
max_tokens=2000
)
planner = planner_prompt | planner_llm.with_structured_output(Plan)
break_down_plan_prompt_template = """You receive a plan {plan} which contains a series of steps to follow in order to answer a query. ..."""
break_down_plan_prompt = PromptTemplate(
template=break_down_plan_prompt_template,
input_variables=["plan"],
)
break_down_plan_llm = ChatTogether(
temperature=0,
model_name="meta-llama/Llama-3.3-70B-Instruct-Turbo-Free",
api_key=together_api_key,
max_tokens=2000
)
break_down_plan_chain = break_down_plan_prompt | break_down_plan_llm.with_structured_output(Plan)测试计划执行器:
question = {"question": "how did the main character beat the villain?"}
my_plan = planner.invoke(question)
print(my_plan)
refined_plan = break_down_plan_chain.invoke(my_plan.steps)
print(refined_plan)输出:
steps = [
'从向量存储中识别英雄和反派。',
'从向量存储中找到高潮或最终对决。',
'从向量存储中分析英雄在此对决中的行动。',
'从向量存储中确定击败反派的关键行动/策略。',
'使用检索到的上下文总结英雄如何击败反派。'
]重新规划逻辑
更新计划:
replanner_prompt_template = """
For the given objective, come up with a simple step by step plan of how to figure out the answer. ...
"""
classActPossibleResults(BaseModel):
plan: Plan = Field(description="未来计划")
explanation: str = Field(description="行动说明")
act_possible_results_parser = JsonOutputParser(pydantic_object=ActPossibleResults)
replanner_prompt = PromptTemplate(
template=replanner_prompt_template,
input_variables=["question", "plan", "past_steps", "aggregated_context"],
partial_variables={"format_instructions": act_possible_results_parser.get_format_instructions()},
)
replanner_llm = ChatTogether(temperature=0, model_name="LLaMA-3.3-70B-Turbo-Free", max_tokens=2000)
replanner = replanner_prompt | replanner_llm | act_possible_results_parser创建任务处理器
任务处理器决定使用哪个子图:
tasks_handler_prompt_template = """
You are a task handler that receives a task: {curr_task} and must decide which tool to use to execute the task. ...
"""
class TaskHandlerOutput(BaseModel):
query: str = Field(description="用于检索或回答的查询")
curr_context: str = Field(description="回答查询的上下文")
tool: str = Field(description="使用的工具:retrieve_chunks, retrieve_summaries, retrieve_quotes, 或 answer_from_context")
task_handler_prompt = PromptTemplate(
template=tasks_handler_prompt_template,
input_variables=["curr_task", "aggregated_context", "last_tool", "past_steps", "question"],
)
task_handler_llm = ChatTogether(temperature=0, model_name="meta-llama/Llama-3.3-70B-Instruct-Turbo-Free", api_key=together_api_key, max_tokens=2000)
task_handler_chain = task_handler_prompt | task_handler_llm.with_structured_output(TaskHandlerOutput)输入问题的匿名化/去匿名化
匿名化问题以避免 LLM 偏见:
class AnonymizeQuestion(BaseModel):
anonymized_question: str
mapping: dict
explanation: str
anonymize_question_chain = (
PromptTemplate(
input_variables=["question"],
partial_variables={"format_instructions": JsonOutputParser(pydantic_object=AnonymizeQuestion).get_format_instructions()},
template="""You anonymize questions by replacing named entities with variables. ...""",
)
| ChatTogether(temperature=0, model_name="meta-llama/Llama-3.3-70B-Instruct-Turbo-Free", api_key=together_api_key, max_tokens=2000)
| JsonOutputParser(pydantic_object=AnonymizeQuestion)
)
classDeAnonymizePlan(BaseModel):
plan: List
de_anonymize_plan_chain = (
PromptTemplate(
input_variables=["plan", "mapping"],
template="Replace variables in: {plan}, using: {mapping}. Output updated list as JSON."
)
| ChatTogether(temperature=0, model_name="meta-llama/Llama-3.3-70B-Instruct-Turbo-Free", api_key=together_api_key, max_tokens=2000).with_structured_output(DeAnonymizePlan)
)编译与可视化 RAG 管道
执行计划并打印步骤:
def execute_plan_and_print_steps(state):
state["curr_state"] = "task_handler"
curr_task = state["plan"].pop(0)
inputs = {
"curr_task": curr_task,
"aggregated_context": state.get("aggregated_context", ""),
"last_tool": state.get("tool"),
"past_steps": state.get("past_steps", []),
"question": state["question"]
}
output = task_handler_chain.invoke(inputs)
state["past_steps"].append(curr_task)
state["query_to_retrieve_or_answer"] = output.query
state["tool"] = output.tool if output.tool != "answer_from_context"else"answer"
if output.tool == "answer_from_context":
state["curr_context"] = output.curr_context
return state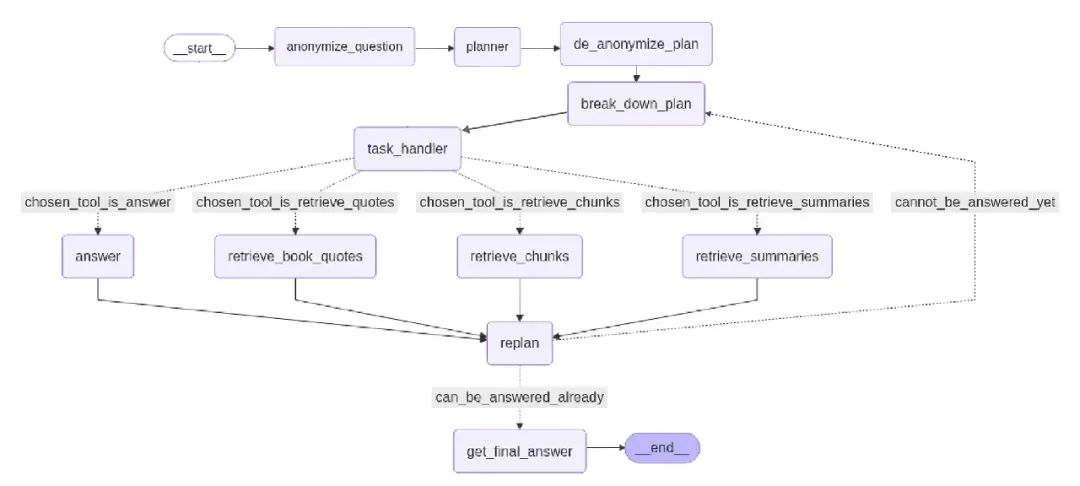
整体流程:
-
1. 匿名化问题 -
2. 规划器创建高层次策略 -
3. 去匿名化计划 -
4. 拆分计划为小任务 -
5. 任务处理器选择工具 -
6. 检索或回答 -
7. 根据新信息重新规划 -
8. 生成最终回答 -
9. 结束
测试最终管道
测试无法回答的问题:
input = {"question": "卢平教授教了什么?"}
final_answer, final_state = execute_plan_and_print_steps(input)输出:
...
最终回答: 数据中未找到答案。测试复杂问题:
input = {"question": "帮助反派的教授教什么课?"}
final_answer, final_state = execute_plan_and_print_steps(input)输出:
...
最终回答: 帮助反派的教授是奇洛教授,教黑魔法防御术。测试推理问题:
input = {"question": "哈利如何击败奇洛?"}
final_answer, final_state = execute_plan_and_print_steps(input)输出:
...
最终回答: 哈利击败奇洛因为他母亲的保护魔法使奇洛在接触哈利时会被灼伤。使用 RAGAS 评估
用 RAGAS 评估管道:
questions = [
"守护魔法石的三头犬叫什么?",
"谁给了哈利·波特他的第一把飞天扫帚?",
"分院帽最初为哈利考虑哪个学院?"
]
ground_truth_answers = [
"Fluffy",
"麦格教授",
"斯莱特林"
]
data_samples = {
'question': questions,
'answer': generated_answers,
'contexts': retrieved_documents,
'ground_truth': ground_truth_answers
}
data_samples['contexts'] = [[context] ifisinstance(context, str) else context for context in data_samples['contexts']]
dataset = Dataset.from_dict(data_samples)
metrics = [
answer_correctness,
faithfulness,
answer_relevancy,
context_recall,
answer_similarity
]
llm = ChatTogether(temperature=0, model_name="meta-llama/Llama-3.3-70B-Instruct-Turbo-Free", api_key=together_api_key, max_tokens=2000)
score = evaluate(dataset, metrics=metrics, llm=llm)
results_df = score.to_pandas()评估结果显示管道在小规模测试中表现良好,部分指标得分约 0.9。
总结
我们从零开始,清洗数据、拆分数据,创建检索器、过滤器、查询重写器和 COT 管道。为了处理复杂查询,引入了子图方法,构建了检索、提炼等子图,还开发了减少幻觉的组件,设计了规划器和任务处理器,最后用 RAGAS 评估了系统。希望你学到了新东西!
(文:PyTorch研习社)