

今天是2025年5月24日,星期六,北京,晴。
今天我们来看看有趣的点。
一个是从GraphRAG的两个有趣问题看问题,当对一个技术并不清楚的时候,所以会有些误解,来说两个典型问题。
另一个是从大模型开源生态全景图看主流研发工具,进入总结期了,聚焦一些主要的、代表性的,能够减少精力分散。
抓住根本问题,做根因,专题化,体系化,会有更多深度思考。大家一起加油。
一、从GraphRAG的两个有趣问题看问题
目前很多人对技术本身还是停留在概念层,并不知道技术本身以及在解决什么问题,来说两个典型问题。
问题1:GraphRAG的成熟生产落地领域?
有个朋友问,目前GraphRAG生产落地的应用有一些案例可以参考吗?在哪些领域会比较成熟?
实际上,这种问法,其实是有问题的,GraphRAG是一种技术,适用的是技术特性,不是领域特性。比如,你要做那种多跳场景、摘要场景这种,那就用graphrag。
所以,应该问,什么任务场景适用比较成熟,面向任务,而非领域。
只要领域里面存在这样的任务需求,就可以试试,但不保熟,毕竟,llm时代,全是实验科学了。
问题2:信息抽取用GraphRAG去做?
又如,另一个朋友问:有个对信息抽取要求很强的场景,客户有几十万份内部研报,要从中抽各行业的三元组做知识图谱。
这种场景,适合用graphrag开展吗?用UIE和OneKE做过三元组抽取实验,但客户质疑结果的可靠度,但又没法协调到行业专家来做标注。
而对于GraphRAG,只是看graphrag中也有抽取的步骤,包括也会生成实体和关系的parquet文件。这个抽取的准确率如果也可以评估,再尝试通过改prompt去提升,那就省事了。
但实际上,并不是这个样,还是要看其中的技术逻辑。它里面是很朴素的,很naive的,不保准的,因为这不是他的点。
专门的任务,就是专门的模型去做,oneke\uie\knowlm等,直接拿来用不行,那就去上大参数量,如果不行,就微调,甚至强化。如果再不行,那就再上策略。
三元组抽取不是抽取就完事,它是一个很严肃的事情,涉及到实体抽取、关系抽取、消歧、更新、归一化这些。不是单个模型,一次就能到位的。重点在于,生产环节中的图谱构建是个很严肃的事情。
graphrag里抽取这些的目的是做索引,做锚点,做关联,能连上就行,所以,不要跟做专门抽取的混为一谈。graphrag还是专注在做问答任务,说白了还是rag,不是ie任务,它背后还是用llm做的抽取、索引和关联。
而至于可信度有两种路径,一个是可信度机器给出,给出阈值,给出溯源,给出量化【但比较扯淡】;一个是下放给用户、拉交互流程、给自己个台阶下。
技术方案总是如此的,根据其技术特性和当初的目的,就直接决定了它适合做什么,能解决什么。使用者也需要清楚这个,用的效果,可能并不是被用方不好,可能是让文科生做物理高考题,用错了。
二、大模型开源生态全景图看主流研发工具
来看看几个有趣的总结图,在进入技术总结期的如今,多看看技术总结,是有意义的。
在《超前点映——2025年大模型开源开发生态全景图解读》(https://mp.weixin.qq.com/s/YSRvoWO5VKxBfDPNagKtJQ)中有两张图,很有总结性借鉴意义,这里做下记录,做个引用。
一个是Open Source LLM Development Landscape 2025,从中可以看到从RAG\agent\训练\数据转换等不同分类下的代表工具。

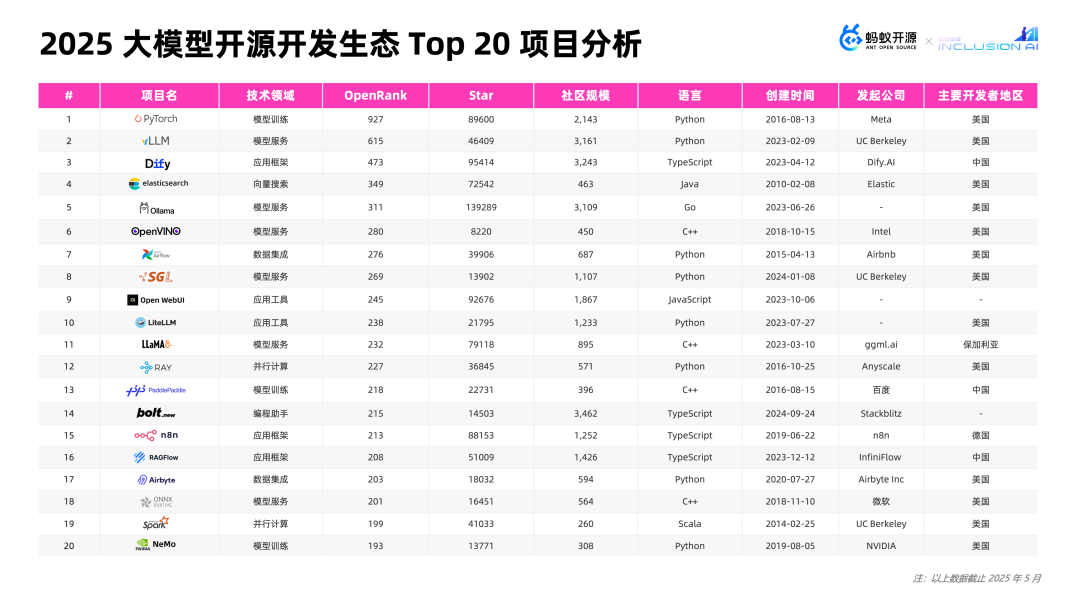
一个是2025年OpenRank排名Top20的项目详情,从中可以看到发布日期等信息,且集中在模型训练框架、高效推理引擎和低代码应用开发框架。
参考文献
1、https://mp.weixin.qq.com/s/YSRvoWO5VKxBfDPNagKtJQ
(文:老刘说NLP)