
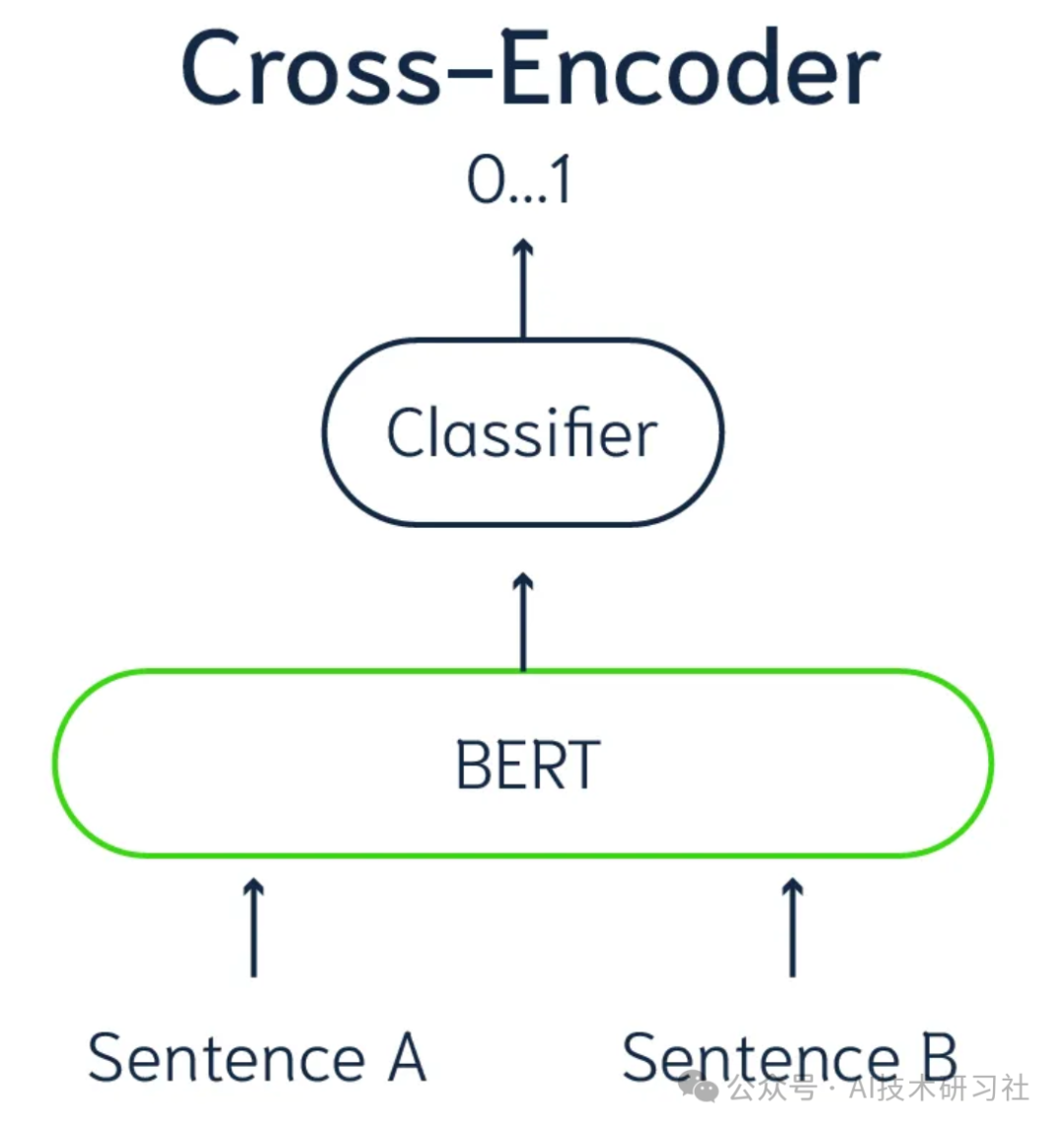
Cross Encoders 跨编码器是一种主要用于自然语言处理(NLP)的神经网络架构,主要用于理解两段文本之间的关系,例如句子对。它们在语义相似度、问答和自然语言推理等任务中特别有效。




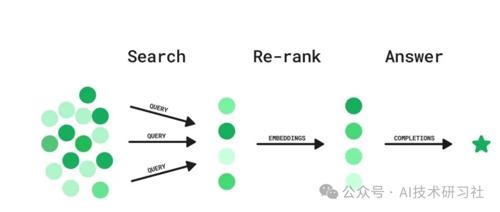
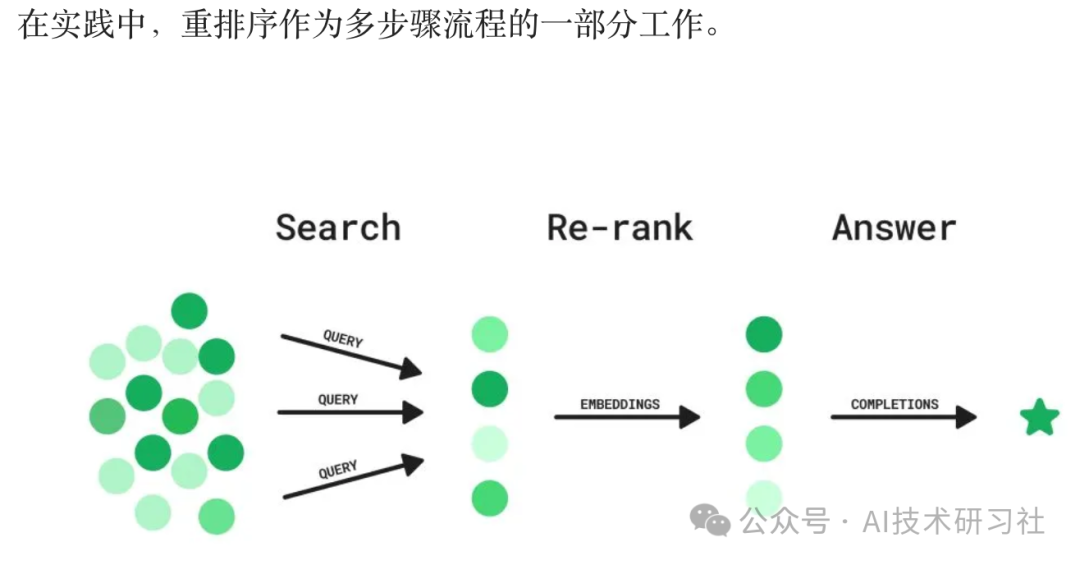
Re-ranking 重新排序,在检索增强生成(RAG)中,重新排序是提高检索到的文档或段落质量的关键步骤,在它们被用于生成最终答案之前。RAG 结合了基于检索的方法(从大型语料库中检索相关文档)和生成模型(根据检索到的内容生成答案)。重新排序有助于确保在生成步骤中优先考虑最相关和高质量的文档。
重排序的需求源于初始检索阶段的局限性。检索器,如 BM25 这样的稀疏检索器或双编码器这样的密集检索器,可能会返回大量候选文档,这些文档按照与查询的相关性排序并不完美。
重排序通过使用更复杂的模型,如交叉编码器,来细化检索文档的顺序,从而更好地评估每个文档与查询的相关性。通过将最相关的文档输入到生成模型中,最终的输出,无论是答案还是摘要,都变得更加准确和符合上下文。
sentence-transformers 库中的 InputExample 类,您可以定义具有标签 0.3 或 0.8 的对 ["sentence1", "sentence2"] ,表示两个文本之间的相关性或相似度。这种格式非常适合需要评分相关性的任务,例如语义文本相似度或文档排序。train_samples = [InputExample(texts=["sentence1", "sentence2"], label=0.3),InputExample(texts=["Another", "pair"], label=0.8),]

create_qa_dataset 函数处理此过程。它接受一个文档目录,将它们分割成更小的块(例如,256 个标记),并使用语言模型(LLM)为每个块生成问题。每个块的问题数量可自定义,允许您控制数据集的密度。
BAAI/bge-reranker-base model 作为基础模型。我们之前已经讨论过这一点。
评估器使用验证数据集( val_dataloader )定期评估模型的性能。
from sentence_transformers.evaluation import SentenceEvaluator
import torch
from torch.utils.data import DataLoader
import logging
from sentence_transformers.util import batch_to_device
import os
import csv
from sentence_transformers import CrossEncoder
from tqdm.autonotebook import tqdm
logger = logging.getLogger(__name__)
class MSEEval(SentenceEvaluator):
"""
Evaluate a model based on its accuracy on a labeled dataset
This requires a model with LossFunction.SOFTMAX
The results are written in a CSV. If a CSV already exists, then values are appended.
"""
def __init__(self,
dataloader: DataLoader,
name: str = "",
show_progress_bar: bool =True,
write_csv: bool =True):
"""
Constructs an evaluator for the given dataset
:param dataloader:
the data for the evaluation
"""
self.dataloader = dataloader
self.name = name
self.show_progress_bar = show_progress_bar
if name:
name = "_"+name
self.write_csv = write_csv
self.csv_file = "accuracy_evaluation"+name+"_results.csv"
self.csv_headers = ["epoch", "steps", "accuracy"]
def __call__(self, model: CrossEncoder, output_path: str =None, epoch: int=-1, steps: int=-1) ->float:
model.model.eval()
total =0
loss_total =0
if epoch !=-1:
if steps ==-1:
out_txt = " after epoch {}:".format(epoch)
else:
out_txt = " in epoch {} after {} steps:".format(epoch, steps)
else:
out_txt = ":"
loss_fnc = torch.nn.MSELoss()
activation_fnc = torch.nn.Sigmoid()
logger.info("Evaluation on the "+self.name+" dataset"+out_txt)
self.dataloader.collate_fn = model.smart_batching_collate
for features, labels in tqdm(self.dataloader, desc="Evaluation", smoothing=0.05, disable=not self.show_progress_bar):
with torch.no_grad():
model_predictions = model.model(**features, return_dict=True)
logits = activation_fnc(model_predictions.logits)
if model.config.num_labels ==1:
logits = logits.view(-1)
loss_value = loss_fnc(logits, labels)
total +=1 # number of batches
loss_total += loss_value.cpu().item()
mse = loss_total/total
logger.info("MSE: {:.4f} ({}/{})\n".format(mse, loss_total, total))
if output_path isnotNoneand self.write_csv:
csv_path = os.path.join(output_path, self.csv_file)
if not os.path.isfile(csv_path):
withopen(csv_path, newline='', mode="w", encoding="utf-8") as f:
writer = csv.writer(f)
writer.writerow(self.csv_headers)
writer.writerow([epoch, steps, mse])
else:
withopen(csv_path, newline='', mode="a", encoding="utf-8") as f:
writer = csv.writer(f)
writer.writerow([epoch, steps, mse])
return mse

(文:AI技术研习社)