

今天是2025年5月19日,星期一,北京,晴。
我们先来看看社区的文档智能的专题,其中有对应的一些技术方案和开源工具的整理。
另外,真的在落地时候,或者从研发者角度看,有真实会遇到什么问题?会有哪些有功能设计?有哪些优化过程?这些其实都可以从开源项目的项目主业自己更新log中找到答案。
因此,我们来看看几个代表性的文档解析及RAG框架发布历程,包括RAGflow、QAnything以及Mineru,会找到一些蛛丝马迹。
抓住根本问题,做根因,专题化,体系化,会有更多深度思考。大家一起加油。
一、老刘说NLP技术社区的文档智能处理专题
我们来温习下文档智能,这个是社区的四大核心方向之一,做了许多分享,典型地并整理成了两个专题:
一个是文档智能专题:

一个是文档智能+大模型专题:
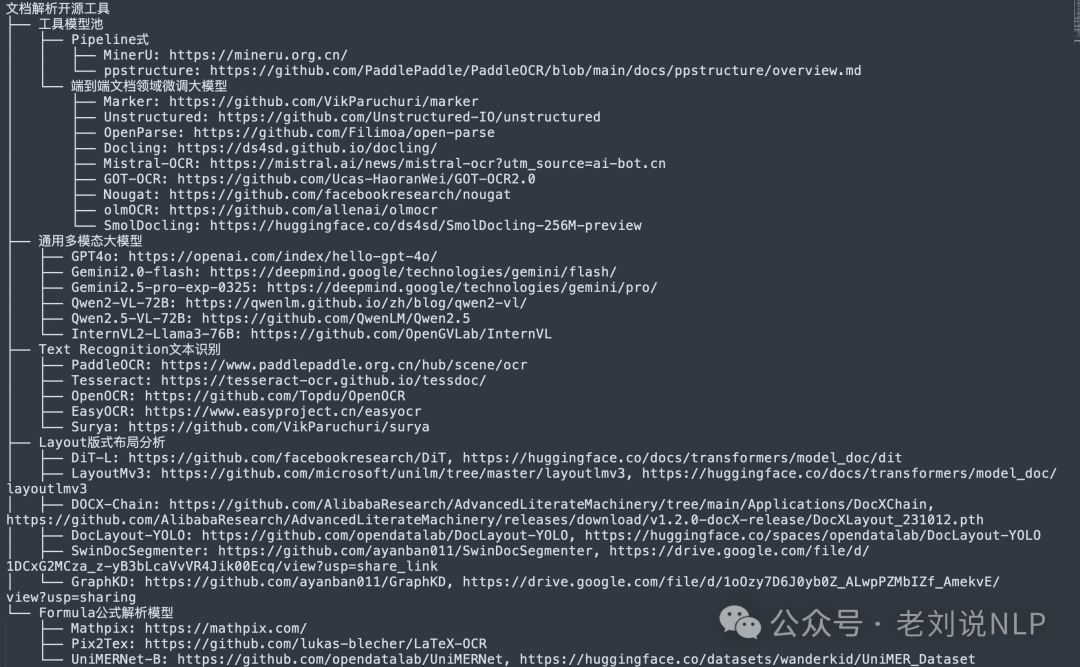
其中,重点的,文档已经走过了一些路程了,到了汇总期,所以关于文档解析的一些工具整理,我已经在《文档解析主流开源工具全家桶及RAG中的文档目录解析PageIndex思路解析》(https://mp.weixin.qq.com/s/xa7IxUmtkN_TiiYECTjbqw)中介绍过许多,包括表格解析、版式分析、公式解析、版式分析等工作,我们再来温习下。
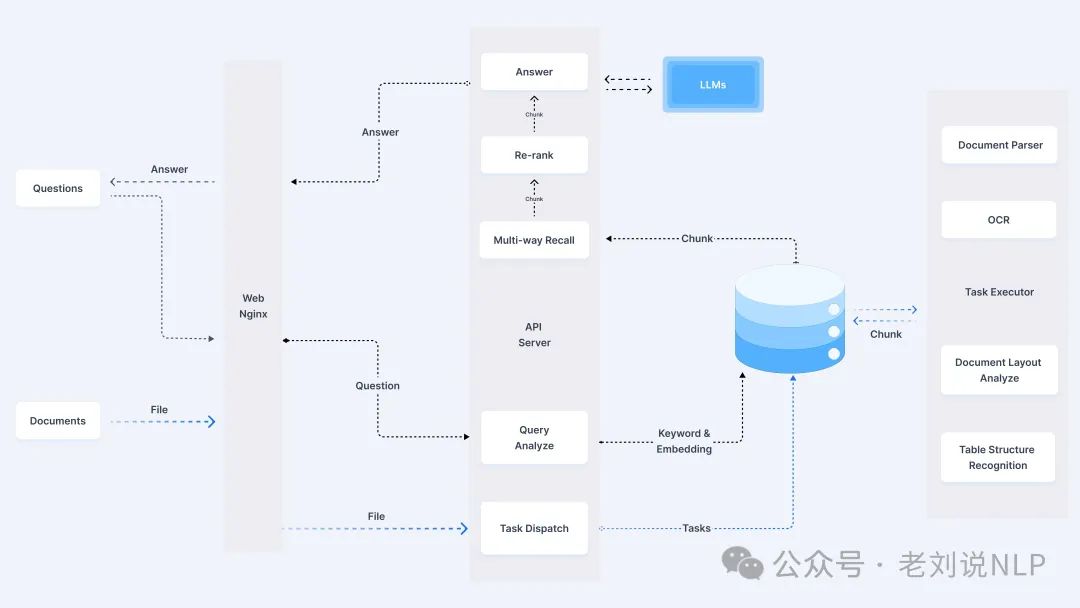
二、从文档解析及RAG框架更新历程
1、RAGflow的更新优化历程
RAGflow(https://github.com/infiniflow/ragflow/blob/main/README_zh.md),是目前的一款RAG框架,可以看看其中的优化设计过程,在功能上,文本切片过程可视化,支持手动调整;答案提供关键引用的快照并支持追根溯源;支持丰富的文件类型,包括 Word 文档、PPT、excel 表格、txt 文件、图片、PDF、影印件、复印件、结构化数据、网页等;大模型以及向量模型均支持配置,提供基于多路召回、融合重排序;
在具体优化上,有6个操作。
1)PDF和DOCX中的图支持用多模态大模型去解析得到描述;
2)结合互联网搜索(Tavily),对于任意大模型实现类似 Deep Research 的推理功能;
3)优化知识图谱的提取和应用,提供了多种配置选择;
4)升级DeepDoc的文档布局分析模型;
5)对解析后的chunk加入关键词抽取和相关问题生成以提高召回的准确度;
6)支持用RAG技术实现从自然语言到 SQL 语句的转换。
2、QAnything的更新优化历程
QAnything (Question and Answer based on Anything,https://github.com/netease-youdao/QAnything/blob/qanything-v2/README_zh.md) 也是一个RAG系统,目标是建成一个支持任意格式文件或数据库的本地知识库问答系统,例如支持PDF(pdf),Word(docx),PPT(pptx),XLS(xlsx),Markdown(md),电子邮件(eml),TXT(txt),图片(jpg,jpeg,png),CSV(csv),网页链接(html)。支持联网检索、FAQ、自定义BOT、文件溯源等。
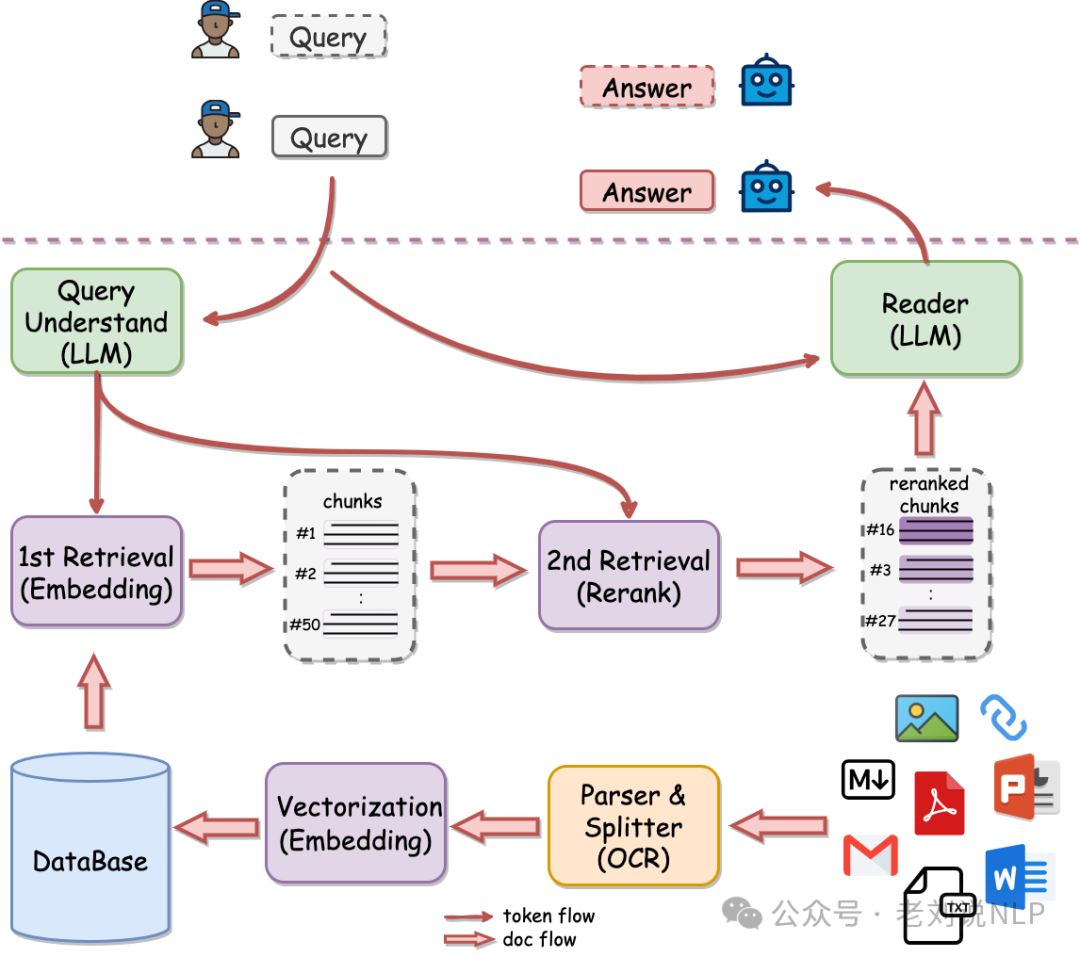
也有一些优化操作,例如:xlsx表格支持多sheet解析;以及在文档解析方面的优化操作,其余的还有:
通过更合理的分块长度,减少了因段落过小或段落不完整而导致的语义和逻辑上的丢失。
改进对分栏文本的识别能力,能够智能判断阅读顺序,即使是跨页的段落也能做出正确处理。新版本能够识别并保存文本段落中的图片和表格,确保不会遗漏任何重要的文本信息;
优化表格解析,包括超出chunk块限制的长表格和复杂结构的xlsx文件的解析和存储;根据识别文档中的小标题,定位和组织对应的文本块,使得解析的结构更加清晰,信息层次更加分明;
优化对于网页url的解析结果,转为.md格式;支持更多编码格式的txt文件和docx文件。
2、MinerU的更新优化历程
Mineru(https://github.com/opendatalab/MinerU/blob/master/README_zh-CN.md),是目前的一个集成式文档解析模型。
在文档解析功能上,支有一下功能:删除页眉、页脚、脚注、页码等元素,确保语义连贯;输出符合人类阅读顺序的文本,适用于单栏、多栏及复杂排版;保留原文档的结构,包括标题、段落、列表等;提取图像、图片描述、表格、表格标题及脚注;自动识别并转换文档中的公式为LaTeX格式;自动识别并转换文档中的表格为HTML格式;自动检测扫描版PDF和乱码PDF,并启用OCR功能;OCR支持84种语言的检测与识别;支持多种输出格式,如多模态与NLP的Markdown、按阅读顺序排序的JSON、含有丰富信息的中间格式等;支持多种可视化结果,包括layout可视化、span可视化等,便于高效确认输出效果与质检;支持纯CPU环境运行,并支持 GPU(CUDA)/NPU(CANN)/MPS 加速;兼容Windows、Linux和Mac平台;
在实际效果上,依旧有许多实际困难,包括:阅读顺序基于模型对可阅读内容在空间中的分布进行排序,在极端复杂的排版下可能会部分区域乱序;不支持竖排文字;目录和列表通过规则进行识别,少部分不常见的列表形式可能无法识别;代码块在layout模型里还没有支持;漫画书、艺术图册、小学教材、习题尚不能很好解析;表格识别在复杂表格上可能会出现行/列识别错误;在小语种PDF上,OCR识别可能会出现字符不准确的情况(如拉丁文的重音符号、阿拉伯文易混淆字符等);部分公式可能会无法在markdown中渲染;
所以,可看看14个优化操作。
1)支持使用自定义公式标识符,可通过修改用户目录下的magic-pdf.json文件中的latex-delimiter-config项实现;
2)优化公式解析功能,提升公式渲染的成功率;
3)ocr默认模型(ch)更新为PP-OCRv4_server_rec_doc(需更新模型),PP-OCRv4_server_rec_doc是在PP-OCRv4_server_rec的基础上,在更多中文文档数据和PP-OCR训练数据的混合数据训练而成,增加了部分繁体字、日文、特殊字符的识别能力,可支持识别的字符为1.5万+,除文档相关的文字识别能力提升外,也同时提升了通用文字的识别能力。
经验证,PP-OCRv4_server_rec_doc模型在中英日繁单种语言或多种语言混合场景均有明显精度提升,且速度与PP-OCRv4_server_rec相当,适合绝大部分场景使用;PP-OCRv4_server_rec_doc在小部分纯英文场景可能会发生单词粘连问题,PP-OCRv4_server_rec则在此场景下表现更好,因此保留PP-OCRv4_server_rec模型,用户可通过增加参数lang=’ch_server'(python api)或–lang ch_server(命令行)调用;
4)修复表格解析模型初始化时lang参数失效的问题;修复在cpu模式下ocr和表格解析速度大幅下降的问题;
5)通过移除一些无用的块,小幅提升ocr-det的速度;修复部分情况下由footnote导致的页面内排序错误;
6)修复windows系统下,在python3.13环境安装时一些依赖包版本不兼容的问题;优化批量推理时的内存占用;优化旋转90度表格的解析效果;优化财报样本中超大表格的解析效果;修复了在未指定OCR语言时,英文文本区域偶尔出现的单词黏连问题(需要更新模型)
7)修复一些兼容问题,支持python 3.13,为部分过时的linux系统(如centos7)做出最后适配,并不再保证后续版本的继续支持,安装说明;
8)安装与兼容性优化。通过移除layout中layoutlmv3的使用,解决了由detectron2导致的兼容问题;torch版本兼容扩展到2.2~2.6(2.5除外);cuda兼容支持11.8/12.4/12.6/12.8(cuda版本由torch决定),解决部分用户50系显卡与H系显卡的兼容问题;
python兼容版本扩展到3.10~3.12,解决了在非3.10环境下安装时自动降级到0.6.1的问题;优化离线部署流程,部署成功后不需要联网下载任何模型文件;性能优化上,通过支持多个pdf文件的batch处理(脚本样例),提升批量小文件的解析速度 (与1.0.1版本相比,公式解析速度最高提升超过1400%,整体解析速度最高提升超过500%);
**通过优化mfr模型的加载和使用,降低了显存占用并提升了解析速度(需重新执行模型下载流程以获得模型文件的增量更新)**;优化显存占用,最低仅需6GB即可运行本项目;优化了在mps设备上的运行速度
9)解析效果优化。mfr模型更新到unimernet(2503),解决多行公式中换行丢失的问题;
10)易用性优化。通过使用paddleocr2torch,完全替代paddle框架以及paddleocr在项目中的使用,解决了paddle和torch的冲突问题,和由于paddle框架导致的线程不安全问题解析过程增加实时进度条显示,精准把握解析进度,让等待不再痛苦;
11)通过引入混合OCR文本提取能力;
12)为表格识别功能接入**RapidTable,**单表解析速度提升10倍以上,准确率更高,显存占用更低;
13)为表格识别功能接入StructTable-InternVL2-1B模型;
14)集成paddle tablemaster表格识别功能;
参考文献
1、https://github.com/infiniflow/ragflow
2、https://github.com/opendatalab/MinerU
(文:老刘说NLP)