

编辑:刘欣、+0
最近,Google 推出了一个可以精准控制画面中光影的项目 —— LightLab。
它让用户能够从单张图像实现对光源的细粒度参数化控制, 可以改变可见光源的强度和颜色、环境光的强度,并且能够将虚拟光源插入场景中。

-
LightLab: Controlling Light Sources in Images with Diffusion Models
-
论文地址:https://arxiv.org/abs/2505.09608
-
项目主页:https://nadmag.github.io/LightLab/
-
HuggingFace:https://huggingface.co/papers/2505.09608
在图像或影视创作中,光线是灵魂,它决定了画面的焦点、景深、色彩乃至情绪。
以电影为例, 好的电影中,光线能巧妙地塑造角色情绪、烘托故事氛围、引导观众目光,甚至能揭示人物的内心世界。

然而,无论是传统的摄影后期处理,还是数字渲染后的调整,精确控制光影方向、颜色和强度,始终是一项耗时耗力、且极依赖经验的挑战。
现有的光照编辑技术,要么需要很多照片才能工作(不适用于单张照片),要么虽然能编辑,但你不能精确地告诉它怎么变(比如具体亮多少、变成什么颜色)。
Google 的研究团队通过在一个特殊构建的数据集上微调(fine-tune)扩散模型,使其学会如何精确地控制图像中的光照。

为了构建这个用于训练的数据集,研究团队结合了两种来源:一部分是少量真实的、带有受控光照变化的原始照片对;另一部分是利用物理渲染器生成的大规模合成渲染图像。
更进一步,研究人员巧妙地利用了「光的线性特性」(linearity of light),从这些图像数据中分离出目标光源和环境光。基于此,他们能够合成出大量描绘不同光照强度和颜色变化的图像对,这些图像对参数化地表示了受控的光影变化。
扩散模型通过学习这些高质量的成对示例,获得了强大的「逼真光影先验能力」(photorealistic prior)。这使得模型能够在图像空间中直接、隐式地模拟出复杂的照明效果,比如间接照明、阴影和反射等。
最终,利用这些数据和恰当的微调方案,训练出的 LightLab 模型能够实现精确的照明变化控制,并提供对光照强度和色彩等参数的明确控制能力。
LightLab 提供了一套丰富的光照控制功能,这些功能可以依次使用,从而创建复杂的光照效果。你可以通过移动滑块来调整每个光源的强度和颜色。

方法
研究团队的方法是使用成对图像来隐式建模图像空间中的受控光变化,这些变化用于训练扩散模型。

后处理流程
对于真实(原始)照片对,研究团队首先分离出目标光源的变化。对于合成数据,研究团队分别渲染每个光源组件。这些分离的组件随后会被缩放并组合,以在线性颜色空间中创建参数化的图像序列。
研究团队既采用了一致的序列色调映射策略,也对每个图像单独进行色调映射,将其转换为标准动态范围(SDR)。
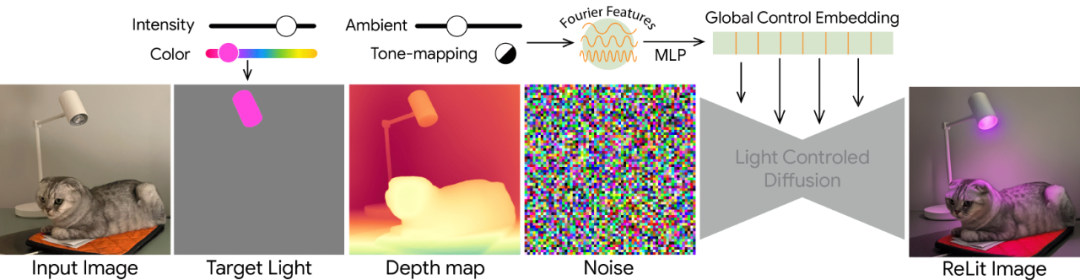
条件信号
研究团队为局部空间信号和全局控制信号使用了不同的条件方案。空间条件包括输入图像、输入图像的深度图,以及两个空间分割掩码,分别用于目标光源的强度变化和颜色。
全局控制(环境光强度和色调映射策略)被投影到文本嵌入维度,并通过交叉注意力机制插入。
数据集摄影捕捉
研究团队使用现成的移动设备、三脚架和触发设备捕捉了一组 600 对原始照片。每对照片描绘相同的场景,唯一的物理变化是打开一个可见光源。
为了确保捕捉到的图像曝光良好,研究团队使用每个设备的默认自动曝光设置,并在后期捕捉时利用原始图像的元数据进行校准。
该数据集提供了几何形状、材料外观和复杂光现象的详细信息,这些信息在合成渲染数据中可能无法找到。遵循之前的研究,研究团队将「off image」视为环境光照,i_ amb: = i_off,并从目标光源中提取光照:i_change = i_on − i_off。
由于捕获的噪声、后期校准过程中的误差或两幅图像之间环境光照条件的细微差异,这个差异可能会有负值。
为了避免因此产生的意外暗淡,研究团队将差异裁剪为非负值: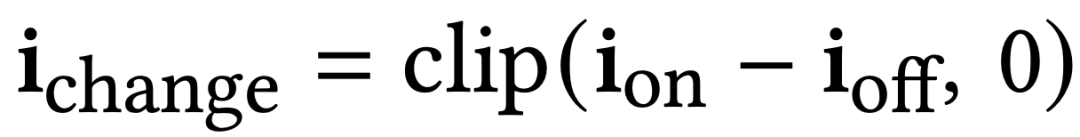 。
。
再结合真实数据有助于将预期的照明变化与合成渲染图像的风格区分开来,这些图像不包括真实物理相机传感器引入的视觉伪影,例如镜头畸变或色差等等。
在后处理中,将每对真实图像的数量增加 60 倍,以涵盖一系列强度和颜色。后处理后,完整的数据集大约包含 36K 张图像。
实验
1、 实现细节
模型和训练:研究团队对一个文本到图像的潜在扩散模型进行微调,其架构布局和隐藏维度与 Stable Diffusion-XL 相同,研究团队在 1024 × 1024 分辨率下训练每个模型 45,000 步,学习率为 10−5,批量大小为 128。训练大约需要 12 小时,使用 64 个 v4 TPU。在训练期间,研究团队有 10% 的时间丢弃深度和颜色条件,以允许无条件推理。
评估数据集:为了进行定量消融和比较,研究团队描述的程序策划的成对数据集上评估训练有素的模型。真实照片数据集包含 200 对不同场景和光源的照片,这些照片在后处理期间被扩展了 60 倍。合成评估数据集包括从两个保留场景中渲染的图像,这些场景包含独特的光源、对象和材质。对于定性评估,不需要真实目标,研究团队收集了 100 张图像。对于这些图像,研究团队手动注释了每张图像中的目标光源,并计算了它们各自的分割掩码和深度。在整个评估过程中以及生成论文中的所有结果时,色调映射条件被设置为 “一起”,除非另有说明。
评估指标:研究团队使用两个常见指标:峰值信噪比(PSNR)和结构相似性指数度量(SSIM)来衡量模型在成对图像上的性能。此外,研究团队通过进行用户研究来验证这些结果是否与用户偏好一致,以与其他方法进行比较。
2、不同域的影响
跨域泛化:研究团队观察到,仅在合成渲染数据上训练的模型无法很好地泛化到真实图像。团队将这种泛化误差归因于风格上的差异,例如缺乏复杂的几何形状、纹理和材质的保真度以及在合成数据集中不存在的相机伪影,如眩光。
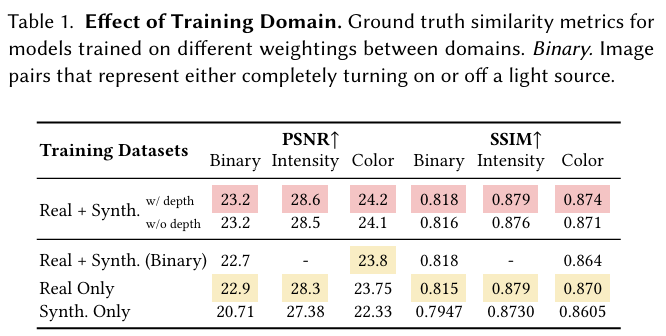
使用多个域:研究团队使用相同的程序在三种数据域的混合上训练三个模型:仅真实捕获、仅合成渲染以及它们的加权混合。表 1 中的结果表明,使用来自两个域的数据混合取得了最佳结果。
值得注意的是,研究团队观察到混合数据集与仅真实捕获之间存在很小的定量相对差异,尽管它们的大小差异显著。例如,添加合成数据仅在平均 PSNR 中带来了 2.2% 的改进。
这可能是由于图像范围内的低频细节掩盖了可感知的局部照明变化,例如小实例阴影和镜面反射。研究团队通过定性比较来证实这种效果,这些比较表明添加合成数据鼓励模型产生仅在真实模型中不存在的复杂局部阴影。
3、 比较
研究团队的方法是第一个提供对真实单图像中光源的细粒度控制的方法。因此,为了进行公平的比较,当与其他工作进行比较时,研究团队仅在二元任务上进行评估。
作为基线,研究团队调整了四种基于扩散的编辑方法:OmniGen 、RGB ↔ X 、ScribbleLight 和 IC-Light 。这些方法使用描述光源位置和输入图像中其他场景内在属性的文本提示。
RGB ↔ X 模型以输入图像的多个预计算法线、反照率、粗糙度和金属度图为条件。ScribbleLight 接收反照率和一个指示光源开关位置的掩码层(与研究团队方法中的光源掩码相反)。最后,为了使用 IC-Light 控制光源,研究团队将整个图像作为前景输入,并提供研究团队的光源分割掩码作为环境光源条件。
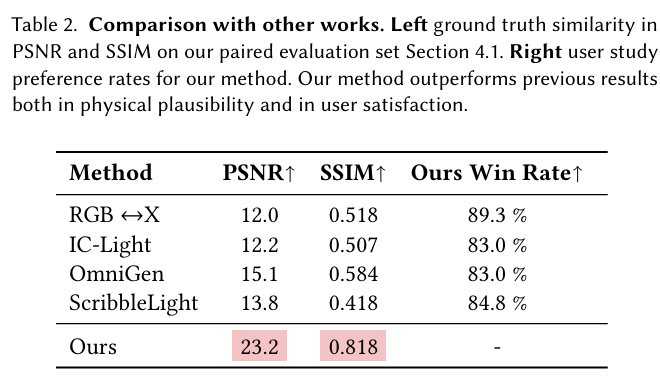
从表 2 可以看出,研究团队的方法显著优于先前的方法。值得注意的是,OmniGen 未能打开 / 关闭目标光源,并引入了局部几何变化。RGB ↔ X、ScribbleLight 和 IC-Light 可以成功地改变输入照明条件,但通常会导致额外的不想要的照明变化或颜色失真。与先前的工作相比,研究团队的方法忠实地控制目标光源,并生成物理上合理的照明。
应用
研究团队介绍了该方法在各种设置中的几种可能应用,主要的应用是能够对照片进行后捕获的光源控制。
光强度

Lightswitch 提供了对光源强度的参数化控制。请注意,不同强度下的光现象保持一致,从而实现交互式编辑。
颜色控制
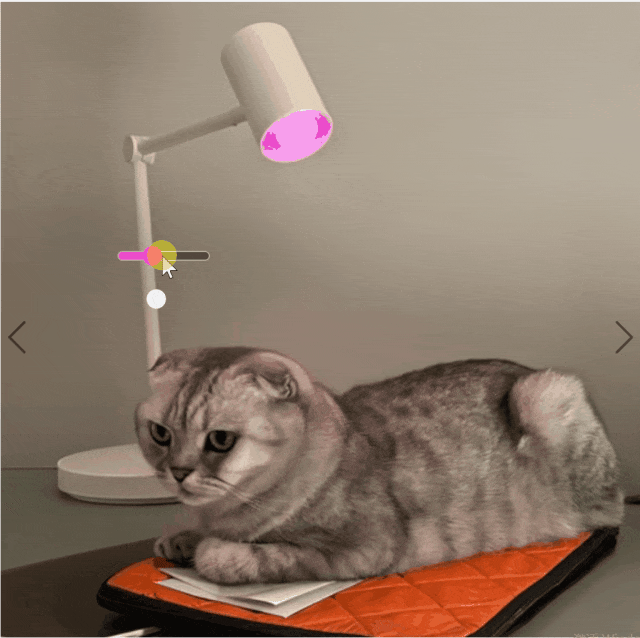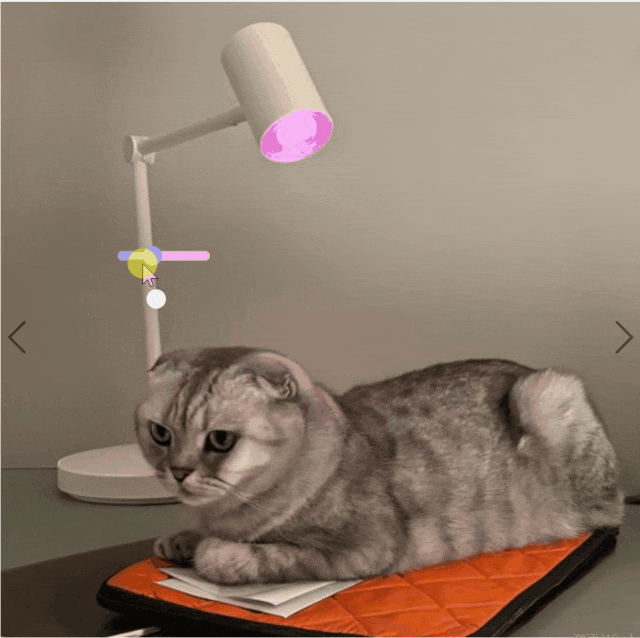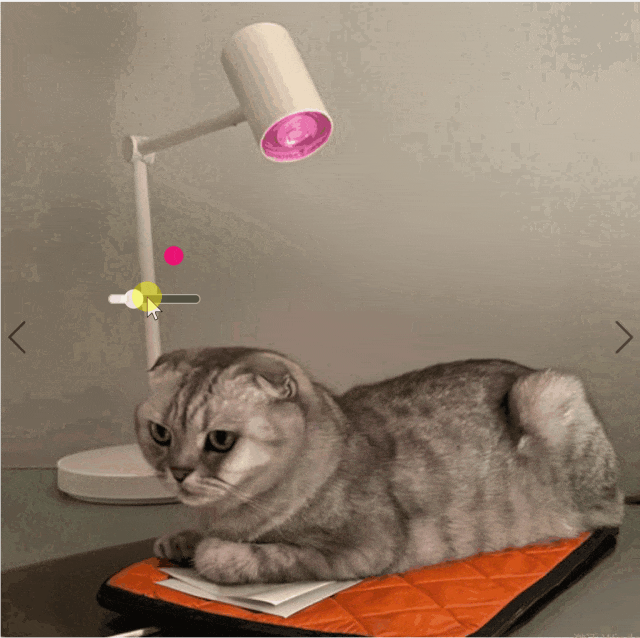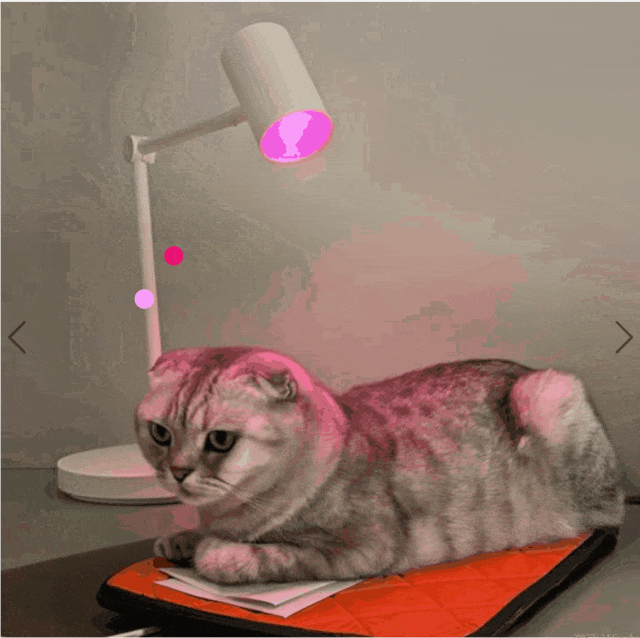
研究团队的方法可以根据用户输入创建彩色照明。使用彩色滑块来调整光源的颜色。
虚拟点光源

通过从合成的 3D 渲染中转移知识,LightLab 可以将虚拟点光源(没有几何形状)插入到场景中。点击圆圈来点亮一个点。
Nex 环境光

将目标光源与环境光分离,使得研究团队能够控制通过窗户进入的光线,这种光线在物理上很难被控制。
物理上合理的光照
左侧:输入序列是通过拍摄围绕多边形狗旋转的熄灭的台灯的照片创建的。中间、右侧:研究团队方法的推断结果以及对狗的放大图。请注意,不同面上的自遮挡以及狗的阴影与台灯的位置和角度相匹配。
更多详细内容请参见原论文。

©
(文:机器之心)