


本文由来自香港城市大学、麦吉尔大学(McGill)、蒙特利尔人工智能实验室(MILA)、人大高瓴人工智能学院、Salesforce AI Research、斯坦福大学、UCSB、香港中文大学等机构的多位研究者共同完成。第一作者为来自香港城市大学的博士生张启源和来自蒙特利尔人工智能实验室(MILA)的博士生吕福源。
当训练成本飙升、数据枯竭,如何继续激发大模型潜能?
💡 在追求通用人工智能(AGI)的道路上,大模型训练阶段的「暴力堆算力」已经逐渐触及天花板。随着大模型训练成本急剧攀升、优质数据逐渐枯竭,推理阶段扩展(Test-Time Scaling, TTS) 迅速成为后预训练时代的关键突破口。与传统的「堆数据、堆参数」不同,TTS 通过在推理阶段动态分配算力,使同一模型变得更高效、更智能 —— 这一技术路径在 OpenAI-o1 和 DeepSeek-R1 的实践中已初显威力。
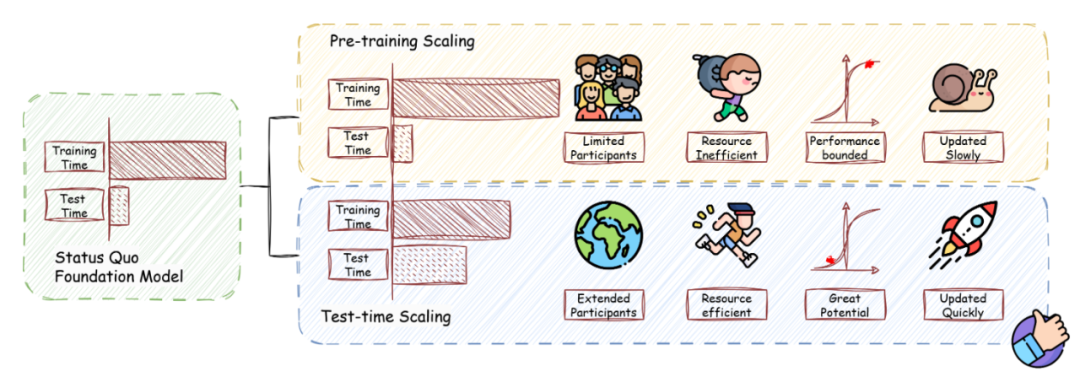
图 1:预训练扩展和推理阶段扩展的示意。
在数学、编程等硬核任务上,TTS 表现亮眼;而在开放问答、多模态理解乃至复杂规划等场景中,它同样展现出巨大潜力。目前,研究者已探索了多种 TTS 策略,如 Chain-of-Thought (CoT)、Self-Consistency、Search 和 Verification,但该领域仍缺乏统一的研究视角与评估框架。
📘 最近,来自香港城市大学、麦吉尔大学(McGill)、蒙特利尔人工智能实验室(MILA)、人大高瓴人工智能学院、Salesforce AI Research、斯坦福大学、UCSB、香港中文大学等机构的多位研究者联合发布了首篇系统性的 Test-Time Scaling 领域综述。该文首次提出「What-How-Where-How Well」四维分类框架,系统拆解推理优化技术,为 AI「深思」绘制全景路线图。

-
论文标题:A Survey on Test-Time Scaling in Large Language Models:What, How, Where, and How Well
-
论文链接:https://arxiv.org/pdf/2503.24235
-
项目主页:https://testtimescaling.github.io/
-
GitHub 仓库:https://github.com/testtimescaling/testtimescaling.github.io/
🔍 论文亮点概览:
本篇 Survey 首次提出了一个覆盖全面、多层次、可扩展的四维正交分析框架:
-
What to scale:扩什么?CoT 长度、样本数、路径深度还是内在状态?
-
How to scale:怎么扩?Prompt、Search、RL,还是 Mixture-of-Models?
-
Where to scale:在哪扩?数学、代码、开放问答、多模态……
-
How well to scale:扩得怎样?准确率、效率、控制性、可扩展性……
在这个框架下,作者系统梳理了当前的主流 TTS 技术路线,包括:
-
并行策略:即同时生成多个答案,并选出最优解(如 Self-Consistency / Best-of-N)
-
逐步演化:即通过迭代修正逐步优化答案(如 STaR / Self-Refine)
-
搜索推理:结合并行与序列策略,探索树状推理路径(如 Tree-of-Thought / MCTS)
-
内在优化:模型自主控制推理步长(如 DeepSeek-R1 / OpenAI-o1)
基于这一框架,作者系统性地梳理了现有文献,实现了四大核心贡献:
-
文献解析:通过结构化分析方法,清晰界定各项研究的创新边界与价值定位;
-
路径提炼:总结出推理阶段扩展技术的三大发展方向:计算资源动态优化、推理过程增强和多模态任务适配;
-
实践指导:针对数学推理、开放问答等典型场景,提供具体可操作的技术选型建议;
-
开放社区:抛弃传统调研自说自话的特点,通过结合主页希望营造一个专门为 TTS 讨论的开放社区,集所有研究者的智慧,不断与时俱进更新更加实践的指导。
与同类综述相比,本文特别注重实用价值和开放讨论,不仅系统评估了不同 TTS 策略的性价比,还前瞻性地探讨了该技术的未来演进方向,包括轻量化部署、持续学习融合等潜在突破点。
作者表示,Test-time Scaling 不仅是大模型推理的「第二引擎」,更是迈向 AGI 的关键拼图。教会模型「三思而后行」,是我们迈向通用人工智能的重要旅程。
框架介绍
作者提出的框架从四个正交维度系统解构 TTS 技术:
1. What to Scale(扩展什么)- 界定推理过程中需要扩展的具体对象,包括:
-
Parallel Scaling(并行扩展):并行生成多个输出,然后将其汇总为最终答案,从而提高测试时间性能;
-
Sequential Scaling(序列扩展):根据中间步骤明确指导后面的计算;
-
Hybrid Scaling(混合扩展):利用了并行和顺序扩展的互补优势;
-
Internal Scaling(内生扩展):在模型内部参数范围内自主决定分配多少计算量进行推理,在推理时并不外部人类指导策略。
其中,作者为每一个扩展的形式,都进行了一些经典工作的介绍,从而丰富了对于扩展策略的外延描述,例如:在并行扩展中作者根据得到覆盖性的来源分为两个更小的类别,在单个模型上的反复采样和多个模型的采样。
2. How to Scale(怎么扩展)- 归纳实现扩展的核心技术路径:
-
训练阶段方法:监督微调(SFT)、强化学习(RL)等
-
推理阶段技术:刺激策略(Stimulation)、验证技术(Verification)、搜索方法(Search)、集成技术(Aggregation)
这个章节是重点章节,作者收录并整理了大量的经典的和最前沿的技术,例如在训练阶段中的强化学习技术,伴随 R1 而大火,因此在短短两个月内涌现出大量的工作,作者将它们尽数收入,同时分成基于奖励模型和不需奖励模型两类;对于刺激策略,作者分成了提示(Prompt),解码(Decode)、自重复(Self-Repetition)、模型混合(mixture-of-model)四类。
3. Where to Scale(在哪里扩展)- 明确技术适用的任务场景与数据集特性。
作者在这里提出尽管 TTS 的推出和验证是在某一类特定的推理任务上得到成功的,可是已经有足够多的工作开始显现出 TTS 是一种通用地能够提升在多样任务的策略,由此作者以推理(Reasoning)和通用 (General Purpose) 两类进行分类,一方面强调了 TTS 在越来越多样、越来越先进的推理任务中有很明显的效果,另一方面也不断跟踪 TTS 在更多通用任务上应用的效果。值得注意的是,作者整理出一个评测基准的表格,方便更多研究者直接从中去选择合适自己的基准。
4. How Well to Scale(效果怎么样)- 建立多维评估体系:
在当下,TTS 已经不仅是一个提高任务准确率的策略,当它成为一个新的值得被研究的核心策略时,对 TTS 的要求会更加多元化,这也是未来研究的主题。作者认为之后对 TTS 的优化重点将不仅仅局限在准确率的提升,是在于如何提高效率、增强鲁棒性和消除偏见等。
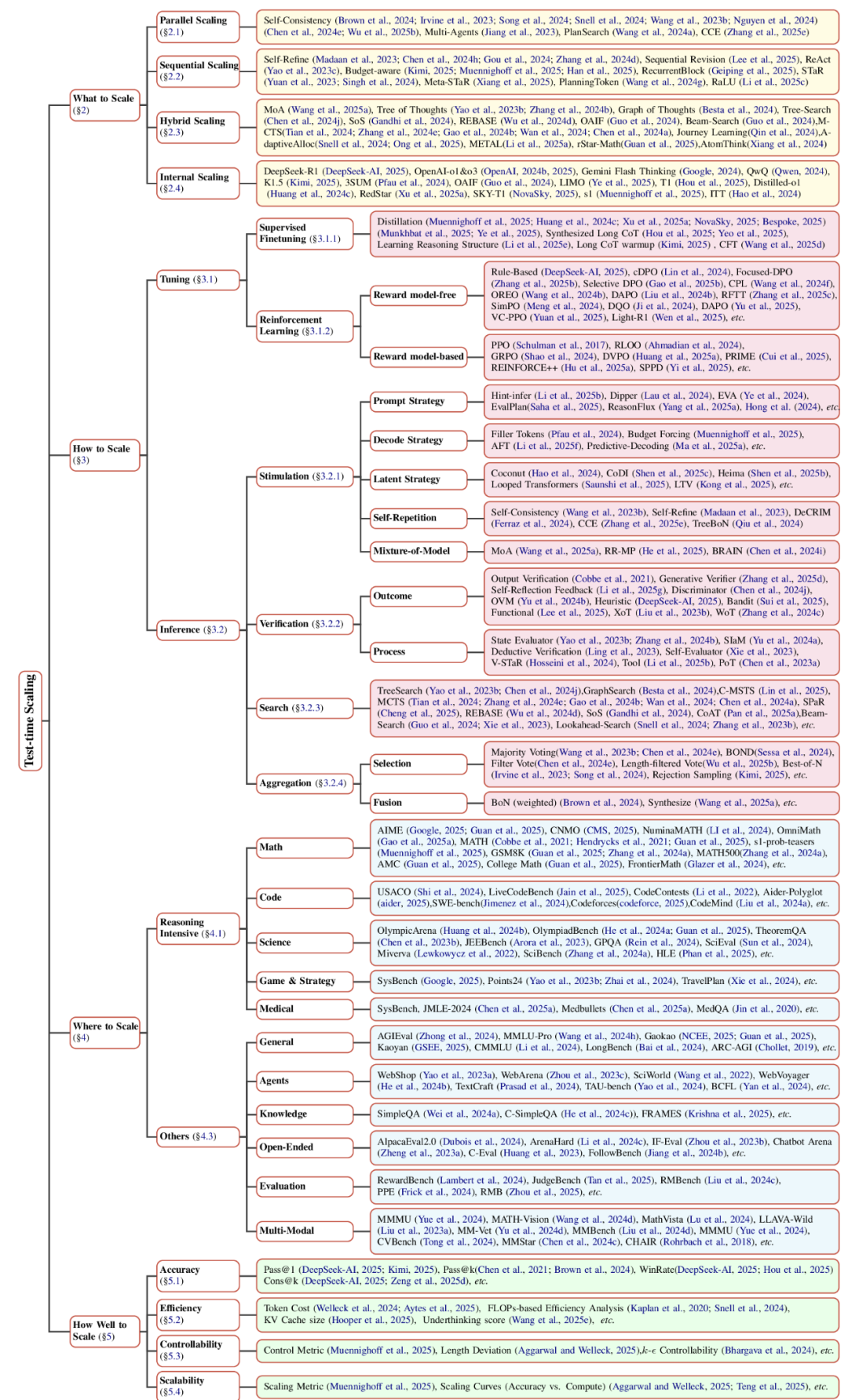
图 2:作者提出的 TTS 框架,包括 what, how, where 和 how well to scale。
作者不仅在每个维度下提供细粒度子类划分,还配套标注了代表性研究工作(如图 2 所示),使分类体系兼具理论完备性和实践指导价值。这一结构化的基础使得后续研究可以无缝地融入作者的分类体系,更清晰地展现其贡献。
为了更好的理解 what to scale 中的并行扩展,序列扩展,结合扩展和内生扩展,作者用一张清晰的示意图进行形象化的展示,同时,在图中使用 how to scale 的技术来组成不同的扩展策略,很好地示意了两个维度如何结合在一起。
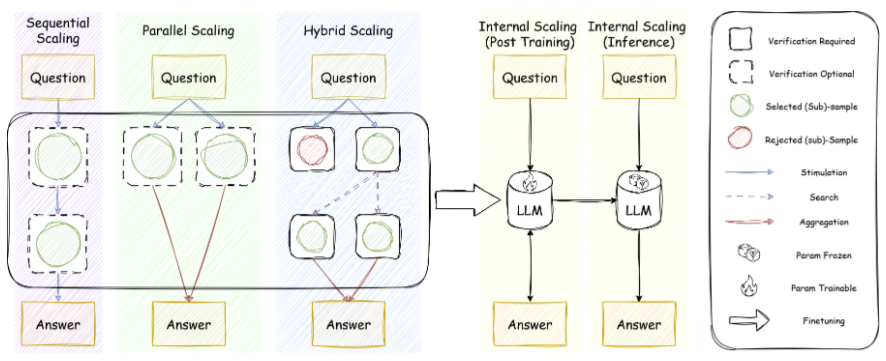
图 3:从 what to scale 到 how to scale。
实践特色
作者强调本篇 Survey 以实用为原则,具体包括:使用所提出的框架分析文献,以及整理操作指南。
文献解析:为了帮助研究者系统性地剖析每项工作,作者设计了一个分析表格,通过将文献贡献对应到框架的四个维度(What/How/Where/How Well),以清晰地解构该工作。这种结构化分析方法不仅能清晰展现各研究的核心创新,更能有效揭示潜在的技术突破方向。
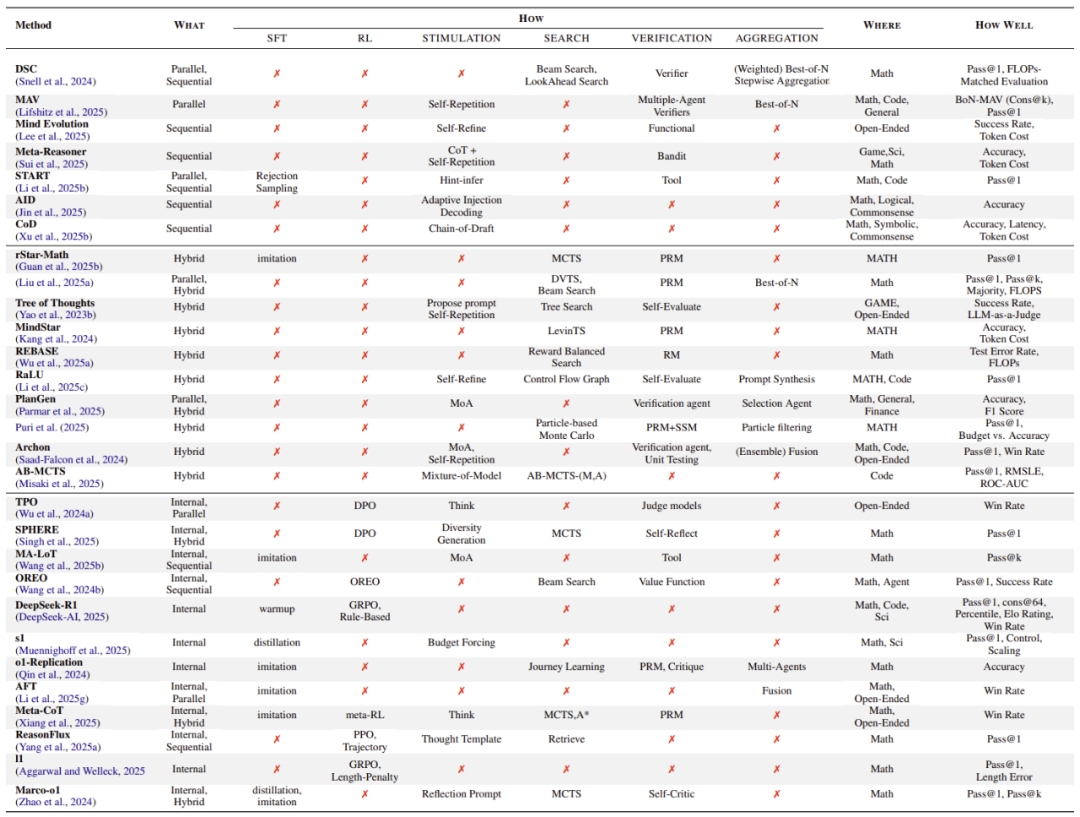
表 1:在现有文献中进行推理扩展时常用的组合方式。
操作指南:另一个潜在的亮点是持续收集 TTS 开发中的实用操作指南,而这些操作指南将以问答的形式展现。作者期待这些问答是具体的、现实的、一线的,因此,作者期待这篇 Survey 将维持开放性,邀请更多在一线研究的学者来参与这项操作指南的收录和编写。下面是作者现阶段的操作指南的内容和风格。

开放社区
有价值的洞见和实践指导是来自于第一线的科研和百花齐放的讨论的,作者期待将论文从传统的静态的一家之言转化为动态的百家之坛,并建立开放的社区来收集任何一线科研者提出的问题和总结的经验,而这些问题和经验在经过筛选后,会更新到最新的论文中,并在致谢中进行感谢。


挑战与未来
尽管 TSS 技术已崭露头角,本文总结了 TTS 当前面临的四大挑战:
-
扩展极限:在未来的 TTS 中,如何突破「暴力采样」的边际收益递减?我们急需在不同方向上探索策略
-
本质理解:tts 中多个模块是否真正驱动了推理改进?reward model 是否需要重新评估?我们依然需要在理论层面揭示技术有效性根源。
-
评估革新:传统指标无法捕捉推理过程质量,随着 test-time scaling 技术的发展,领域内急需开发细粒度评估体系,以便更全面地评估不同策略
-
跨域泛化:当前 TTS 方法在数学、代码任务中表现突出,但如何迁移至法律、金融等高风险场景?如何在推理过程中考虑现实世界的制约?
论文还指出,目前常见的技术如 SFT、RL、Reward Modeling 等虽被频繁使用,但背后的作用贡献尚不清晰,值得深入探索,例如:SFT 真的不如 RL 更泛化吗?R1 的时代下 SFT 的角色是什么?什么样的 Reward Modeling 更加高效?等等
此外未来 TTS 的发展重点包括:1. 统一评估指标(准确率 vs 计算开销);2. 拓展到金融、医学等真实场景;3. 构建具备自适应推理能力的通用智能体。
推理扩展策略正引领 AI 推理范式转变:让模型在「用」的时候持续变强。
©
(文:机器之心)