跳至内容
AI算力之王英伟达,现在也加入到开源大模型的竞赛中,并且干成了Meta没干成的事儿。
日前,英伟达团队在huggingface上更新推出了Llama-Nemotron(LN)系列模型,这是一个开放的异构推理模型家族,可提供出色的推理能力、推理效率和企业使用的开放许可,有三种参数大小——Nano(8B)、Super(49B)和 Ultra(253B),多项指标媲美甚至超越了DeepSeek-R1等最先进推理模型,同时提供了更强的推理吞吐量和内存效率。
今天,Llama-Nemotron相关的技术报告论文一并出炉,论文介绍了英伟达团队在加速推理、知识提炼和持续预训练,以及以推理为中心的后训练阶段所做的创新工作,此外,还顺带发布了完整的训练后数据集和训练代码库。
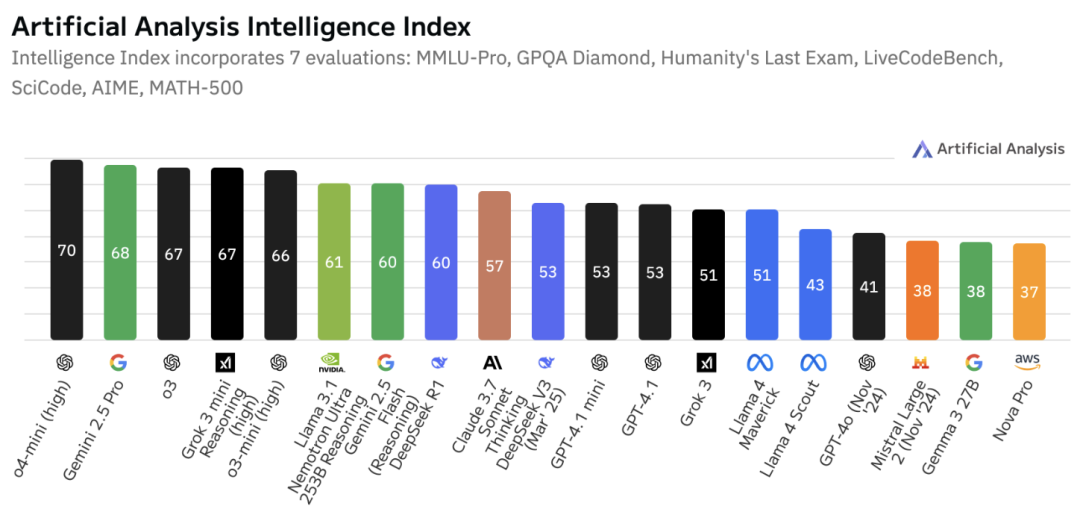
根据第三方评测,截至2025年4月,旗舰型号LN-Ultra已跃居成为最“智能”的开源模型。
OpenAI o1和DeepSeek-R1等推理模型的推出,标志着语言模型发展进入了一个全新阶段,随着推理能力越来越依赖于推理时的模型规模扩展,设计在推理过程中运行高效的模型变得至关重要。
推理效率不再仅仅是部署层面需要考虑的问题,现在也已成为影响模型整体智能水平和智能体流程可行性的核心限制因素。因此,最大限度地提高推理效率是这些模型的主要优化目标。
此外,除了单纯地提升推理效率,向终端用户提供对推理行为的控制能力同样关键。并非所有查询都适合进行详细的多步推理,在某些情况下,回复过于冗长甚至会适得其反,所以,能够确保合理分配推理资源,并且使回复风格与具体任务相匹配也是重点。
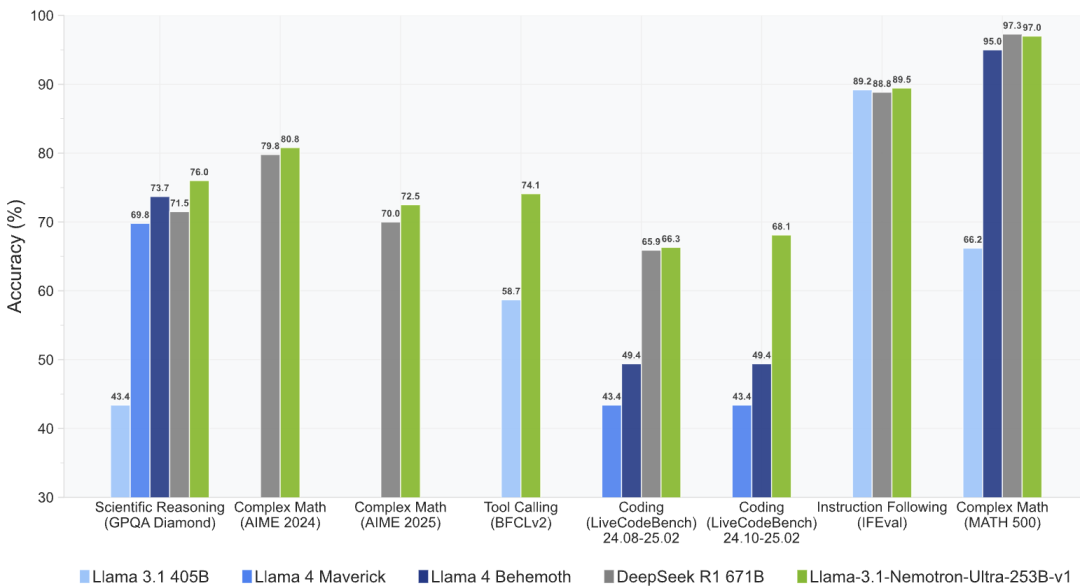
在技术论文中,英伟达团队详细介绍了Llama-Nemotron系列模型的训练过程,LN-Ultra的性能超过了DeepSeek-R1,同时它可以在单个8xH100节点上运行,实现了更高的推理吞吐量。
Llama-Nemotron模型的基座源自Meta公司的Llama 3.1和Llama 3.3,在实现强大推理性能和128K标记的上下文长度的同时,针对高吞吐量推理进行了优化。
第一阶段包括从Llama 3系列模型中通过神经架构搜索(NAS)优化推理效率,并应用前馈网络(FFN)融合技术。
第二阶段包括利用知识蒸馏进行恢复训练和持续预训练。
第三阶段是在标准指令数据和来自如DeepSeek-R1等强 “教师” 模型的推理轨迹的混合数据上进行有监督微调(SFT),这使得模型能够进行多步推理。
第四阶段涉及在复杂的数学和STEM数据集上进行大规模强化学习,这是使 “学生” 模型超越 “教师” 模型能力的关键步骤,英伟达团队还开发了一个定制的训练框架。
最后一个阶段是校准工作,重点在于使模型遵循指令并符合人类偏好。
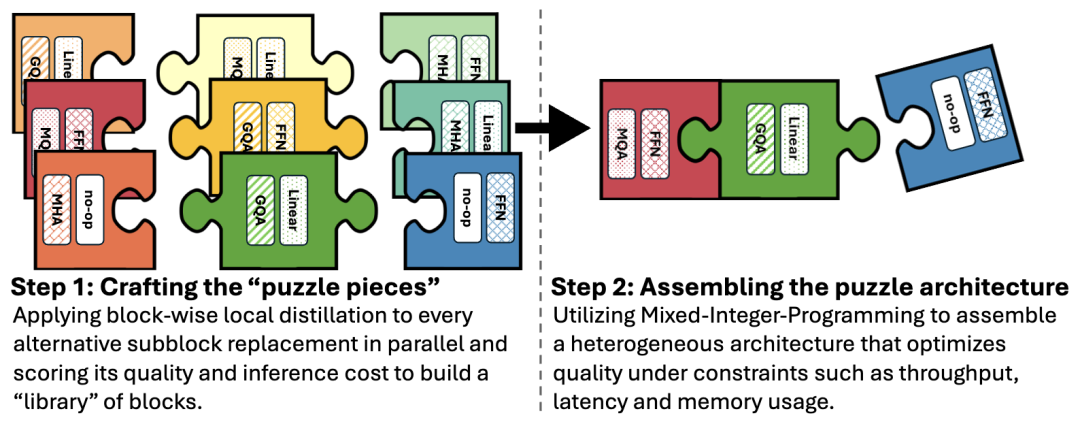
LN大型模型(LN-Super)和LN超大型模型(LN-Ultra)使用Puzzle框架针对高效推理进行了优化。
从Llama 3模型出发,Puzzle应用逐块局部蒸馏法来构建一个可供选择的Transformer模块库,每个模块都独立且并行地进行训练,以近似其原始模块的功能,同时改善诸如延迟、内存使用情况或吞吐量等计算属性。
一旦构建好了模块库,Puzzle框架就会通过为每一层选择一个模块来组装成一个完整的模型。这些模块变体包括:
1、去除注意力机制:一些模块完全省略了注意力机制,从而减少了计算量和键值(KV)缓存的内存消耗。
2、可变的前馈网络维度:前馈网络的中间层大小是可变的,能够在不同的粒度级别上进行压缩,例如,压缩至原始隐藏层大小的87%、75%、50%,甚至低至10%。
英伟达团队的实证评估表明,就整体吞吐量和内存节省而言,去除注意力机制和压缩前馈网络(FFN)对于优化LN-Super和LN-Ultra最为有效。
LN-Super经过优化,能够在单个英伟达H100 GPU且张量并行度为TP1的情况下高效运行,其吞吐量比Llama 3.3-700亿参数指令模型快5倍。
在使用单个H100 GPU时,即使Llama 3.3-700亿参数指令模型以张量并行度为 TP4的最优配置运行,张量并行度为TP1的LN-Super仍具有至少2.17倍的吞吐量优势。该模型还在大约30万个缓存标记的限制条件下进行了优化,这一数据是在单个H100 GPU上以FP8精度测得。
LN-Ultra则是针对一整个H100节点(8块GPU)进行优化的,应用前馈网络融合(FFN Fusion)技术后,最终的模型实现了延迟降低1.71倍的效果。LN-Ultra同样也在缓存标记的限制条件下进行了优化,在H100节点上,以FP8精度计算时最多可支持300万个标记,以BF16精度计算时最多可支持60万个标记。
在完成神经架构搜索阶段后,LN-Super和LN-Ultra都要接受额外的训练,以提升模块间的兼容性,并弥补在逐模块替换过程中出现的性能损失。
LN-Super使用知识蒸馏目标函数,在 “蒸馏混合”(Distillation Mix)数据集上进行了400亿个标记的训练。
LN-Ultra首先在相同的蒸馏数据集上使用知识蒸馏方法进行了650亿个标记的训练,随后在Nemotron-H第四阶段预训练数据集上进行了880亿个标记的持续训练。
在关键基准测试中,LN-Ultra达到了参考模型Llama 3.1-4050亿参数指令模型的水平,甚至超越了它,这表明,通过短期的蒸馏和预训练,激进的架构优化能够与较高的模型性能相协调。
最后,英伟达团队还推出Llama-Nemotron-Post-Training-Dataset数据集,这个数据集是有监督微调(SFT)和强化学习(RL)数据的集合,有助于提升原始Llama模型在数学、代码、通用推理以及指令遵循方面的能力。
该数据集的发布标志着在开源AI模型开发和改进的开放性与透明度越来越高,搭配完整的训练集和训练代码库,为其他团队重新复现和改进提供支持。
根据路透社、The Information等最新消息报道称,在面向中国市场的H20芯片遭美国政府限制后,英伟达正在重新开发针对中国市场的特供AI芯片,新晶片样品最早将在6月提供给客户测试。
据悉,该计划已初步与阿里巴巴、腾讯和字节跳动等主要中国客户进行了沟通,同时也计划开发基于Blackwell架构的新一代中国特供版芯片。
不过,路透社报道称美国也正在拟出台新法案进一步打击向中国出口英伟达芯片,据悉,监控芯片去向的举措得到了美国两党议员的支持,部分议员还提出要求让英伟达在其高性能AI芯片中加入位置追踪功能,跟踪芯片以确保它们在出口管制许可下被授权的地方。
近期,Nvidia正在加大AI深挖力度,在4月底举行的2025国际学习表征会议(ICLR) 上陆续发布了70多篇研究论文,内容涵盖医疗保健、机器人、自动驾驶汽车和大型语言模型等。
整体来看,英伟达的算盘可能并不在于把AI技术创新公开来参与具体的竞争,更多考量因素可能是因为各类AI技术越进步,应用越广泛,其AI算力芯片的生意就会越好,以此来补足政策禁令限制带来的业务损失或下滑风险。
(文:头部科技)