


大推理模型(LRM)在非常复杂或困难的任务中表现非凡,这依赖于其强大的系统 2 思维模式(深思熟虑的慢思考)。但在日常的使用中,大量用户提问的问题更多是系统 1 问题(这些问题可以直觉快速回答),他们期待模型尽快回答,而不是等待模型冗长的思考。
一些初期的示例级的探索反映出了 LRM 在这类问题上存在思考冗长的直观表现。这不仅消耗了更多无用资源,也大大降低了用户体验(甚至很多自媒体博主做了不少视频调侃这个现象)。
但当前仍缺乏全面评估这一现象的基准测评集。现有的数据集,要么领域单一(只有小学数学题),要么没那么简单(有些问题对人类简单,但模型并不容易答对)。
为了填补这一研究空白,本文正式提出了 S1-Bench,一个适用于系统 1 思维的简单、多样、自然的测评数据集。这项研究旨在揭示 LRM 的系统 1 表现缺陷,为 LRM 迈向双系统兼容的目标提供评测基础。

论文标题:
S1-Bench: A Simple Benchmark for Evaluating System 1 Thinking Capability of Large Reasoning Models
论文作者:
张文源,聂帅怡,张兴华,张泽锋,柳厅文
论文链接:
https://arxiv.org/abs/2504.10368
Github链接:
https://github.com/WYRipple/S1_Bench
Huggingface链接:
https://huggingface.co/datasets/WYRipple/S1-Bench

S1-Bench:适用于系统 1 思维的基准测试
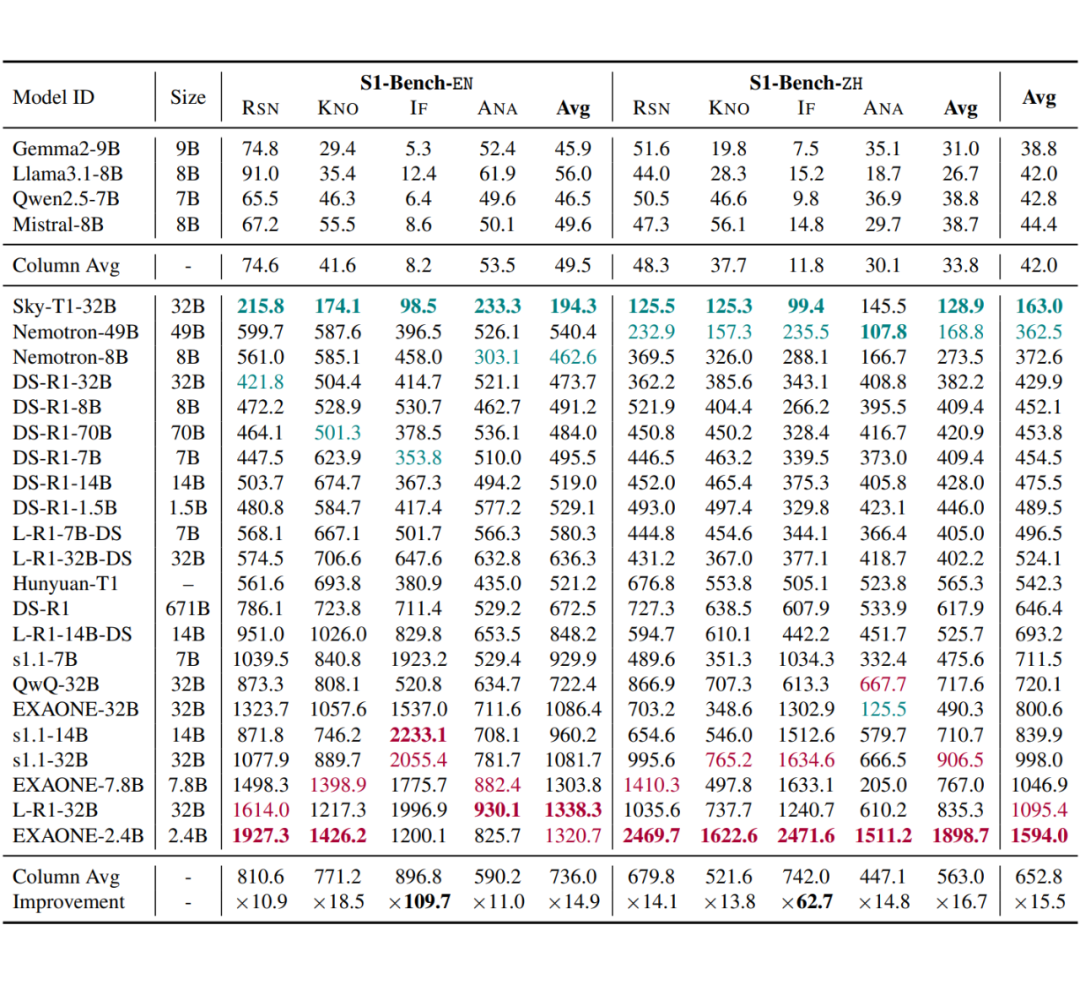
S1-Bench 是一个包含英汉双语、多领域的基准,共 422 个问答对,旨在评估 LRM 在极其简单问题上的系统 1 思维能力。传统的大模型能够轻松解决这些问题,对人类来说也不难。S1-Bench 由四个广泛用于大模型评估的类别构成:推理(RSN)、知识(KNO)、遵循指令(IF)和分析(ANA),并包含 28 个子类别。
1.1 如何确保问题简单
通过两个方面确保问题简单且适合系统 1 思维:先验的简单性约束和后验的简单性验证。
先验简单性约束要求问题满足如下准则:
(1)问题必须自然、清晰地表达,并且不含歧义,且没有故意设置的陷阱。
(2)答案必须是独特的或易于证伪的(例如,提供一个三个字母的英语单词)。
进一步对类别限制以确保简单性:
-
RSN:仅限于可用最少推理或直觉解决的问题。
-
KNO:限制为具有独特、可验证答案的常识性知识,答案来源如维基百科。
-
IF:涉及简单的指令,不要求严格的格式。
-
ANA:仅限于答案可以直接从提示中推断的问题,例如二分类。这些限制确保所有问题对人类回答者保持简单明了。
后验简单性验证要求问题满足如下准则:
由于语言模型与人类之间存在 bias,对于人类来说简单的问题可能对大模型来说较为困难。因此,引入了额外的事后验证,以确保问题足够简单:不同家族的小型大模型能够正确且稳健地回答正确。
1.2 如何构建 S1-Bench

为了实现先验约束,本文引入遵循先验设置的数据生成器(generator)和质量鉴别器(discriminator)。为了确保后验验证,本文引入简单性验证器(validator)和正确性评估器(evaluator)。
生成器、鉴别器和评估器的配置均为温度 0.7 和 top-p=0.9,而验证器的温度设置为 0.0、0.2 和 0.4,每个采样 10 次。此外,招募了三名经验丰富的研究生作为注释员,他们熟悉大模型,并充分理解 S1-Bench 的构建目标。
子类准备
为了确保多样性,本文借鉴现有的基准分类方法(如 MMLU、IFEval 和 GSM8K)以及大模型评估综述,选择或合并现有的子类别,并设计新的子类别。本文确保所有子类别满足简单性的要求,并为每个子类别提供一个示例问题。
生成与修改
本文使用两个数据生成器为每个候选子类别创建初始问题和答案。生成过程遵循 prompt 的要求(详情可参考原论文),确保双语内容与子类别定义一致,同时保持多样化的视角。
每个问题都附有辅助答案,每个子类别生成 50 对初始双语问答对。这些问答对由三位注释员和两位质量鉴别员独立评估,确保问题明确、边界清晰,并且仅接受一个正确答案。对于每个问答对,进行五次独立评估。
基于这些评估,注释员进行讨论并集体决定是否保留、修改或丢弃每个问题,以确保符合先验简单性要求。保留的问题提交给验证器进行测试,并由评估器评估回答的准确率。正确答案的问题被纳入 S1-Bench,而其他问题则进行重新处理。
在 30 次采样迭代中,只要有一次错误出现的问题将经历一个迭代的难度降低过程。这些问题会返回给生成器,并附上特定的 prompt 以降低复杂性,随后进行相同的鉴别、讨论和评估程序。
在经过三次难度降低迭代后仍未能达到无误表现的问题将被排除在工作流之外。最终的 S1-Bench 由满足人类设定的先验简单性约束和后验简单性验证的问题组成。

实验设置
2.1 基线测试模型和设置
本文评估了 22 种不同的 LRMs,这些模型被明确训练为首先进行思考过程,然后生成最终答案的模式。
这些 LRMs 包括开源模型族,如 DeepSeek(深度求索)、Qwen(阿里)、Nemotron(英伟达)、Light-R1(360)、s1.1(李飞飞等人团队)、EXAONE(LG)和 Sky-T1(加州伯克利 NovaSky 团队),以及闭源模型 Hunyuan-T1(腾讯),其参数大小从小型(1.5B)到巨型(671B)不等。
OpenAI 的 o 系列模型未被包括在内,因为它们不向用户披露思考过程。对于每个模型,考虑了两组生成配置:Greedy sampling(温度 t=0);Top-p sampling(温度 t=0.6,top-p=0.95,采样大小 k=5)。
2.2 评估指标
格式指标
通常,LRMs 的输出应通过一个“结束思考标记”(例如,<\/think>)进行分隔,以区分思维过程与最终答案。然而,LRMs 并不总是以正确的格式生成响应。为了评估这一点,本文计算符合所需格式标准的响应百分比,分类如下(对于 top-p sampling,每个指标在5次生成中取平均):
S-Corr(严格格式正确率):严格遵循格式的响应所占的百分比,即它们严格遵循仅包含一个“结束思考标记”后跟一个非空的最终答案的格式。
L-Corr(宽松格式正确率):松散遵循格式的回应所占的百分比,即除了无限重复思考,或没有任何思考和回复内容的其他所有情况。
效率指标
本文计算平均响应 token 数(ART),该指标表示满足宽松格式要求的响应中 token 的平均数量。token 计数是通过 Qwen2.5 的 token 分析器获得的。
准确率指标
本文分别针对严格和宽松的格式要求计算准确率指标。使用 GPT-4o 作为评估器来评估响应的正确性,评估提示可以参考原文附录。对于 Greedy sampling,直接计算准确率;对于 top-p sampling,使用两个指标:
pass@1:遵循 DeepSeek-R1 等研究设定,计算 pass@1 以评估 k=5 个响应中正确响应的百分比,其中 是第 个响应的正确性,具体定义为:

acc@k:具体而言,当所有 个响应均正确时,acc@k=1;否则,acc@k=0。它的定义为:
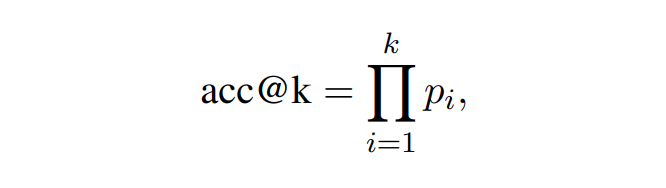
值得注意的是,S-Corr 代表在严格格式要求下 pass@1 和 acc@5 的上限,而 L-Corr 遵循相同的原则。

实验结果
3.1 主实验结果
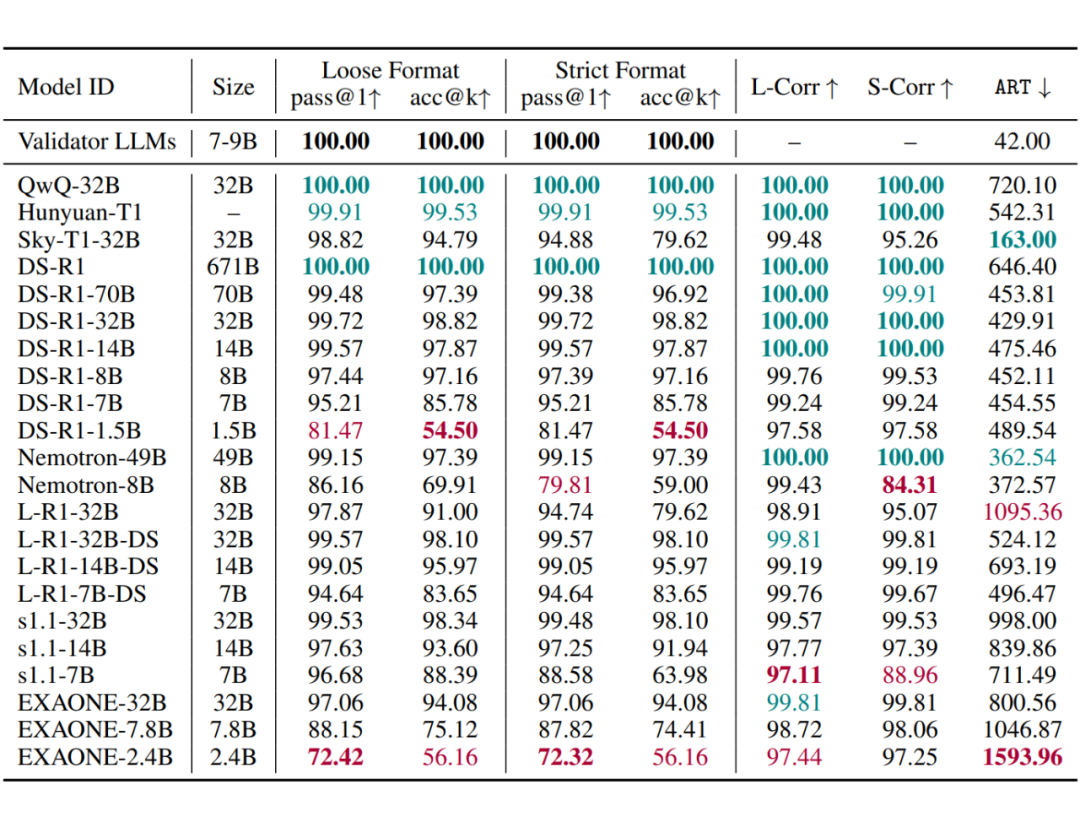
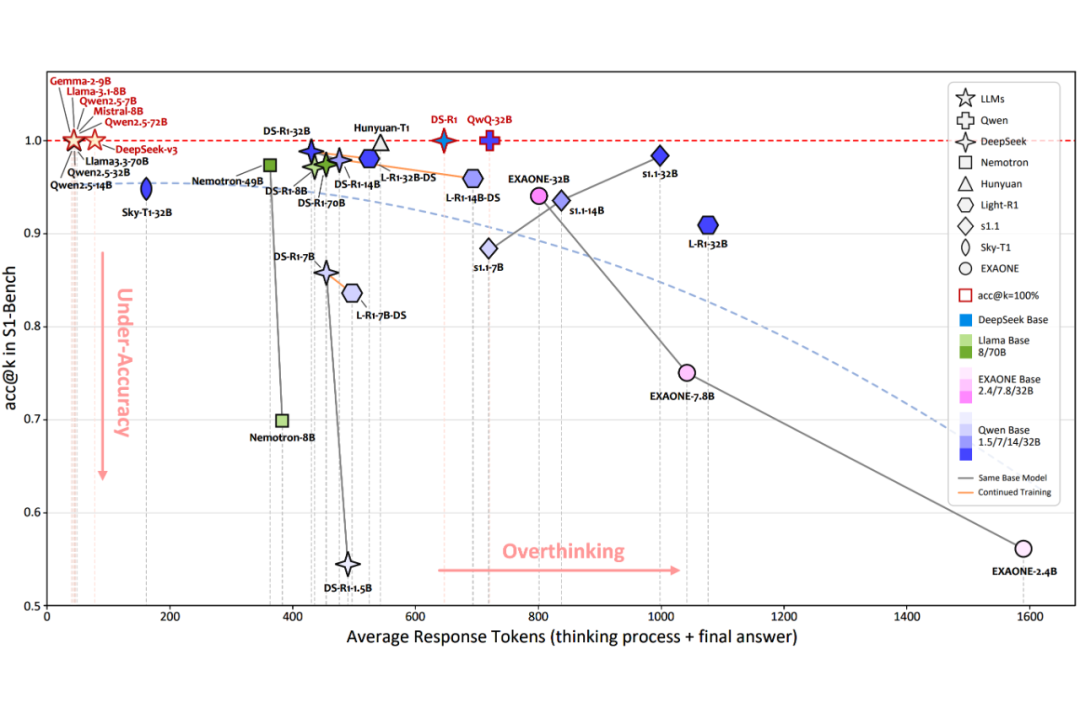
LRMs 在 S1-Bench 上的效率明显低于 LLMs,并且在 ART 与模型大小之间未观察到明显的相关系数。
即使是先进的 LRMs,如 DeepSeek-R1 和 QwQ-32B,并未显示出在效率上的明显优势。相比之下,Sky-T1-32B 经过特定优化以利用 SimPO 减轻过度思考,实现了最高效率。L-R1-DS 7B/14B/32B 模型生成的响应比 DS-R1-7B/14B/32B 模型更长,前者是在后者的基础上进行进一步的后训练。
这表明,进一步的后训练可能会提高复杂任务的推理能力,但代价是简单任务的响应效率降低。最后,s1.1 模型生成的响应明显长于 DeepSeek-R1-Distilled 模型。
尽管这两种模型都是仅通过 SFT 训练以获得长链推理能力,但 DeepSeek-R1-Distilled 模型使用了 80 万个训练样本,而 s1.1 模型仅使用了 1000 个。这一差异表明,较小的训练集可能导致对长推理模式的表面模仿,从而在简单问题上产生冗长的思维。
一些 LMRs 在简单问题上表现出低准确率。观察表明,尽管采用了深度推理,大多数 LRMs 在简单问题上的准确率仍低于传统的 LLMs。例如,DS-R1-1.5B 和 EXAONE-2.4B 的准确率仅略高于 50% 的 acc@k。此外,随着模型大小的减小,准确率也会下降。
最后,许多 LRMs 在 top-p 采样中的稳健性正确性上存在困难,其中 acc@k 显著低于 pass@1。这个问题在较小的 LRMs 中尤为明显。例如,DS-R1-1.5B 的 pass@1 达到了 81.47%,但其 acc@k 仅为54.50%。
3.2 效率实验 1:不同类型问题的 ART 分析
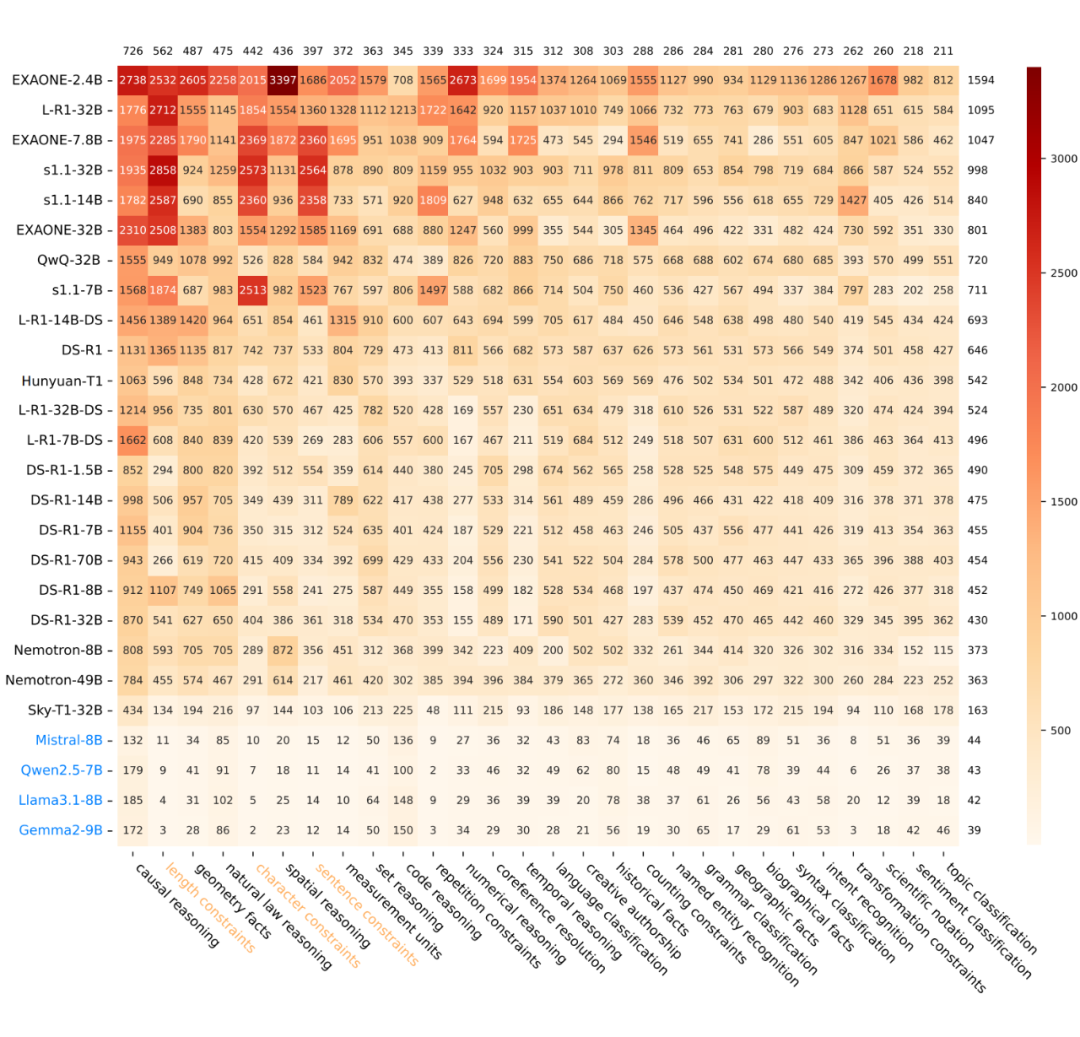
LRMs 在遵循指令的问题上表现出 ART 的显著增加,并且在解决方案空间较大时往往会过度探索。
尽管小型 LLMs 在 S1-Bench 的所有主要类别中,遵循指令问题拥有最简洁的响应,但 LRMs 在中文中的回应长度是其 109.7 倍,在英文中是 62.7 倍,使其成为所有类别中回应长度最长的类型。
本文进一步分析了遵循指令问题的子类别。如热力图所示,在长度限制、字符限制和句子限制的子类别中,ART 显著较长。这三种问题类型有一个共同特征:它们的正确性是可验证的,但解决方案空间非常广泛。
文章发现,尽管模型很快识别出正确答案,但它陷入了搜索空间,不断探索替代方案,未能及时停止。这种现象在 ART 较高的家族中更为明显,如 s1.1 和 EXAONE。
LRMs 在推理任务中的 ART 也显著增加。推理问题的 ART 也显著提高,热力图进一步展示了这一现象在不同推理子类别中的 ART。对此现象的一个可能解释是,推理问题与 LRMs 的训练数据分布密切对齐,从而进一步刺激了 LRMs 的长链推理行为。
LRMs 在中文和英文中始终表现出低效率。大多数 LRMs 在英文问题上显示出更高的 ART,而 QwQ32B 和 Hunyuan-T1 在中文和英文中表现出相似的 ART。
3.3 效率实验 2:思维过程中的解分析
为了理解 LRMs 在 S1-Bench 中低效的原因,本节进一步分析最终答案正确、格式严格正确且思维过程非空的样例。首先将每个思维过程划分为若干个解决方案,每个解决方案被定义为 LRMs 明确得出直接与正确答案相符的结论的点。
划分过程由 DeepSeek-v3 执行,prompt 可以参考原文附录。然后,计算 LRMs 的平均初始思维代价。
对于每个样本,如果思维过程包含至少一个解决方案,则代价定义为第一个解决方案中的 token 数量。如果没有提供清晰且正确的解决方案,则代价为思维过程中所有 token 的总数。文章发现:
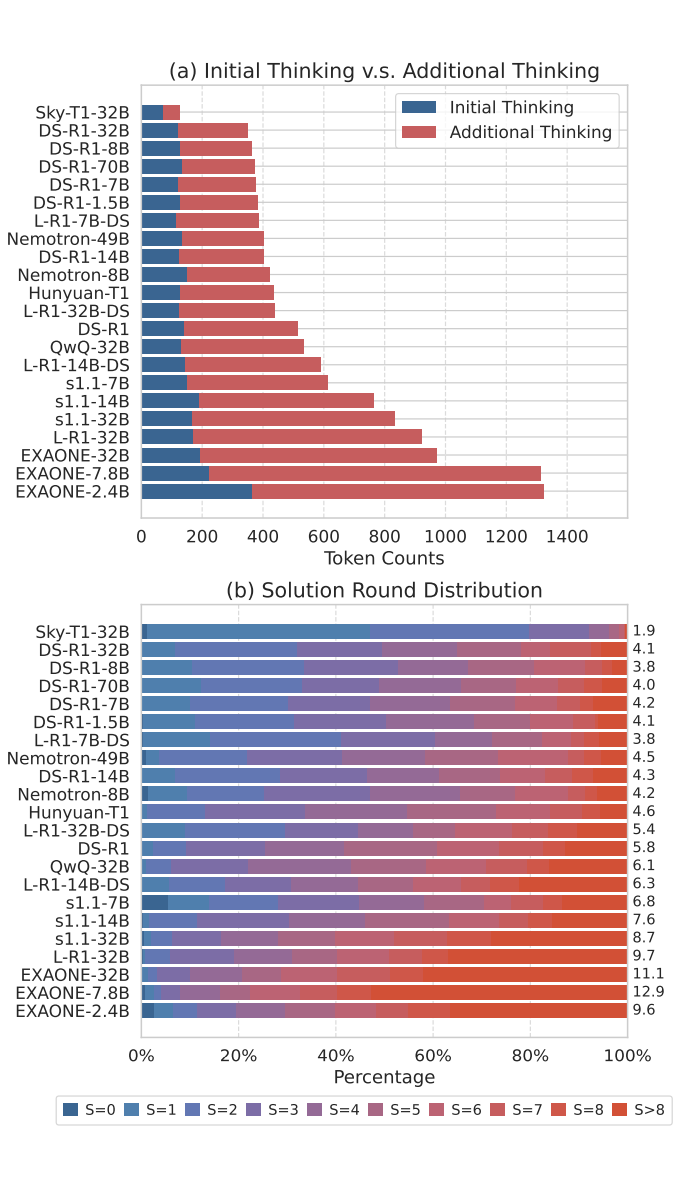
在初始思维过程中的逐步推理并不是 LRMs 效率低下的主要原因。如图所示,尽管不同 LRMs 的 ART 差异显著,但它们的初始思维成本相似,仅占总成本的一小部分。
在得出正确答案后生成不必要的解题轮次是导致 LRMs 效率低下的原因之一。本文进一步检查了 S1-Bench 上各种 LRMs 的解题轮次分布,发现思维过程较长的模型往往会产生过多的解题轮次,反复验证已经解决的简单问题。这种冗余的验证显著导致了计算效率的低下。
3.4 效率实验3:思维过程中的冗余

信息冗余随着推理序列的增加而增加。本文进行相似度分析,以分析在推理序列增加时,LRMs 思维过程中的信息冗余如何变化。
具体而言,首先将完整的思维过程划分为 k 个等长段落。然后,使用 all-MiniLM-L6-v2 模型对每个段落进行编码。对于每个段落,计算其与所有前面的段落的余弦相似度,并使用最大相似度作为其信息冗余的衡量标准。
如图所示,随着推理序列的增加,所有四个主要类别中的信息冗余均有所增加。Sky-T1-32B 显示出整体较低的相似度,这源于其较短的思维过程,但仍然表现出上升的趋势。
3.5 错误分析实验
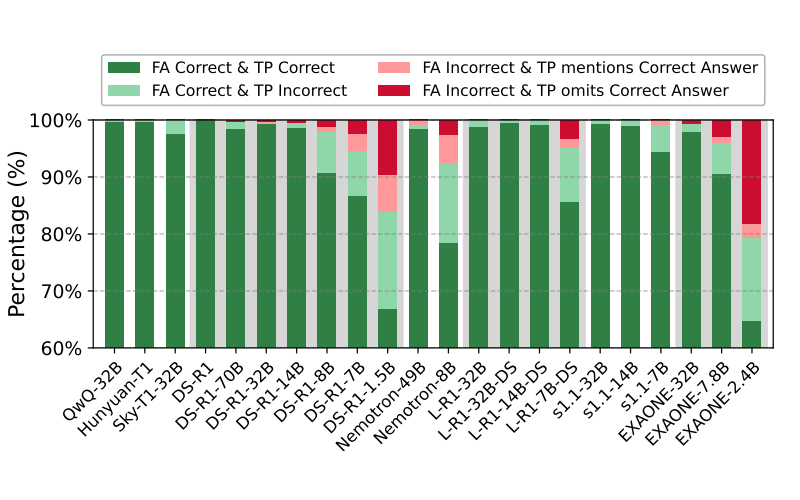
本节探讨了思维过程质量与最终答案准确率之间的关系。本文关注格式严格正确且思维过程非空的样本。对于最终答案正确的样本,根据思维过程是否在中间步骤中包含显式错误结论进行分类。对于最终答案错误的样本,根据在推理过程中是否至少提到一次正确答案进行分类。
使用 DeepSeek-v3 进行分类,提示见表 13。上图展示了不同 RLMs 中这四类的分布。分析得出了以下观察结果:
1. 准确率较低的 LRMs 在推理中往往包含错误的中间结论,即使它们最终得出了正确的最终答案(浅绿色);
2. 尽管 LRMs 在推理过程中有时能得出正确答案,但它们可能会偏离,最终产生错误结论(浅红色)。
3.6 简单性预判发现
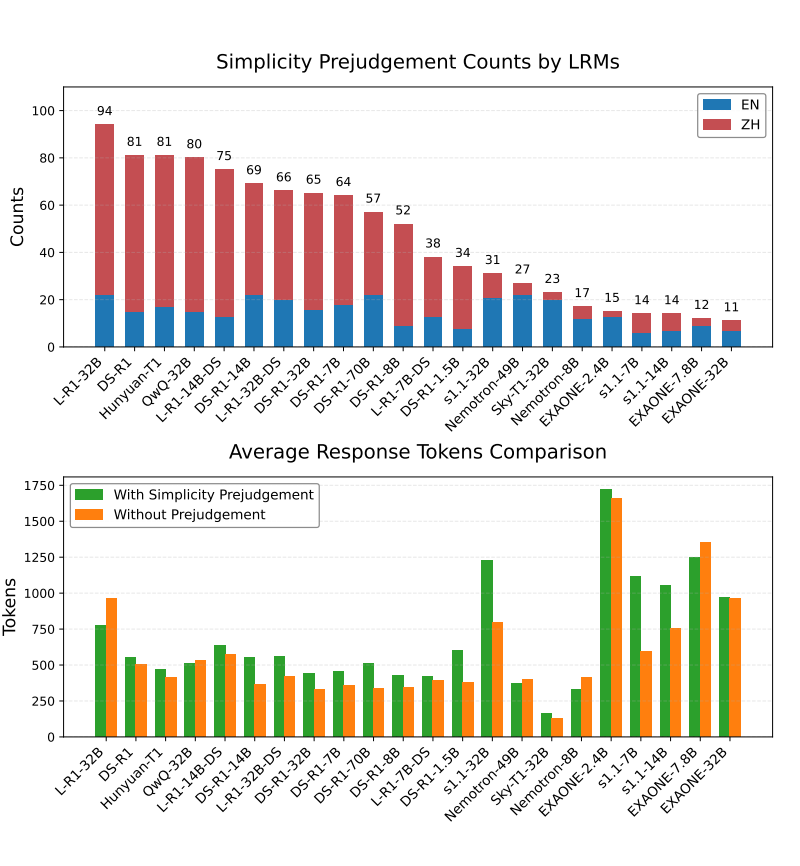
本文发现了一个有趣的现象:LRMs 可以对某些简单问题进行预判。具体而言,从每个思考过程中提取前 50 个 tokens,并使用 DeepSeek-v3 识别显示判断的句子,进一步提取判断词。上展示了将问题判断为简单的词语频率,研究发现:
LRMs 具有预判问题简单性的能力,特别是在中文里。所有 LRMs 在其思维过程中都表现出部分的预判现象,显示出直接评估问题难度的能力。此外,14 个 LRMs 在中文中的预判倾向显著更强,这一现象主要集中在 L-R1、DS-R1、QwQ 和 Hunyuan 模型家族中。
即便存在预判,LRMs 的思维长度并未缩短。如图所示,表现出预判的思维过程的平均 ART 并没有下降。本文认为进一步探索这一现象是未来研究的方向之一。这些结果表明,LRMs 具备对问题难度的内在理解,这为 LRMs 的双系统兼容性开辟了一条新的路径。
3.7 格式类型分析
本节提供了一种全面的 LRM 格式分类法,并强调在未来的研究工作中解决这些问题的重要性。与传统的 LLM 不同,LRMs 经常出现格式错误,这种错误表现为响应未能遵循生成单一结束思考标记(ETM)的要求。
这种不一致性在区分思维过程和最终答案时造成了重大挑战。格式错误与过度思考和不足准确率现象是不同的类别,但同样表明对基本推理陷阱的脆弱性。
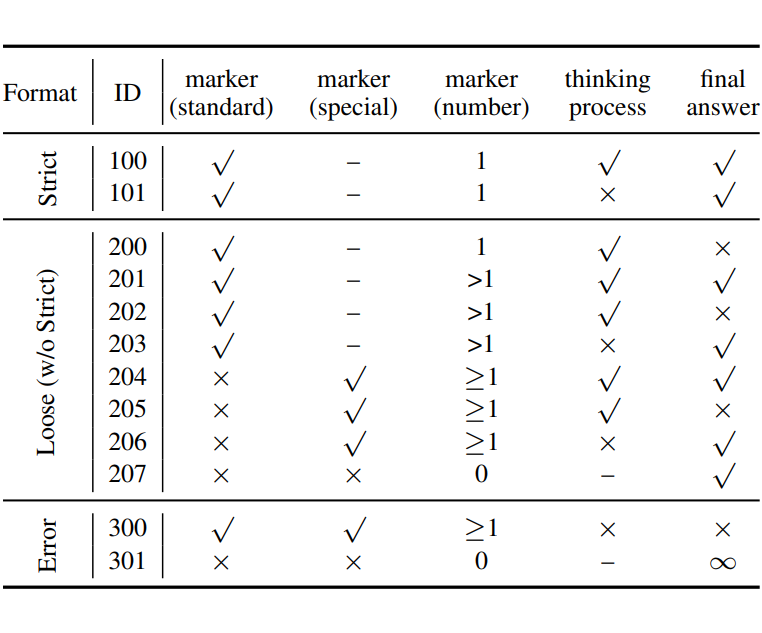
如表所示,本文识别并分类了 12 种不同的格式类型,每种格式类型都分配了一个唯一的 ID。这些格式类型可以分为严格格式和宽松格式,其中严格格式代表了宽松格式的一个专业子集。
松散格式(Loose Format)
ID-100 和 ID-101 代表两种标准解码模式,并额外归类为严格格式(Strict Format)。两者仅包含一个 ETM。在这两者中,ID-100 包含一个思维过程,而 ID-101 仅生成 ETM 和最终答案。
类似于 ID-100 和 ID-101,ID-201 包含一个 ETM,但仅包括思维过程。LRMs 有时会产生多个 ETM,这些 ETM 由 ID-202/203/204 表示。此外,LRMs 可能无法正确生成标准 ETM。
本文将这些情况分类为 ID-204/205/206,本文提供了一组特殊ETM的参考集合: </ think>、</th think>、</ reason>、\nanswer\n、Final Answer 和答案。当模型不输出任何标准或特殊 ETM 时,将其归类为 ID-207。
误差格式(Error Format)
LRM 产生两种类型的不可解码误差:ID-300 表示 LRM 仅输出一个 ETM 而没有任何额外内容,而 ID-301 则表示 LRM 的思维过程达到了最大长度。
上表展示了在 top-p sample 设置下 12 种格式类型的分布。分析揭示了三个关键见解:
1. 无限思维现象在大多数模型中普遍存在,尤其集中在参数少于 32B 的语言模型中。这表明在训练过程中应优先考虑输出格式,以减少格式错误,特别是在使用较弱的基础模型时。
2. Nemotron 和 EXAONE 系列经常产生格式正确的响应,而没有明显的推理过程。这种行为可以视为一种减轻过度思考的机制。然而,EXAONE 系列仍然表现出显著的过度思考倾向,这表明语言模型在没有明显推理的情况下响应的能力与其过度思考的倾向可能是正交特征。
3. 评估的语言模型中没有表现出被分类为 ID-205/206 的行为,这可能是因为特殊的 ETM 被语言模型视为唯一替代标准 ETM 的选项。此外,没有观察到 ID-300,表明高温度采样通常会产生语义上有意义的响应。
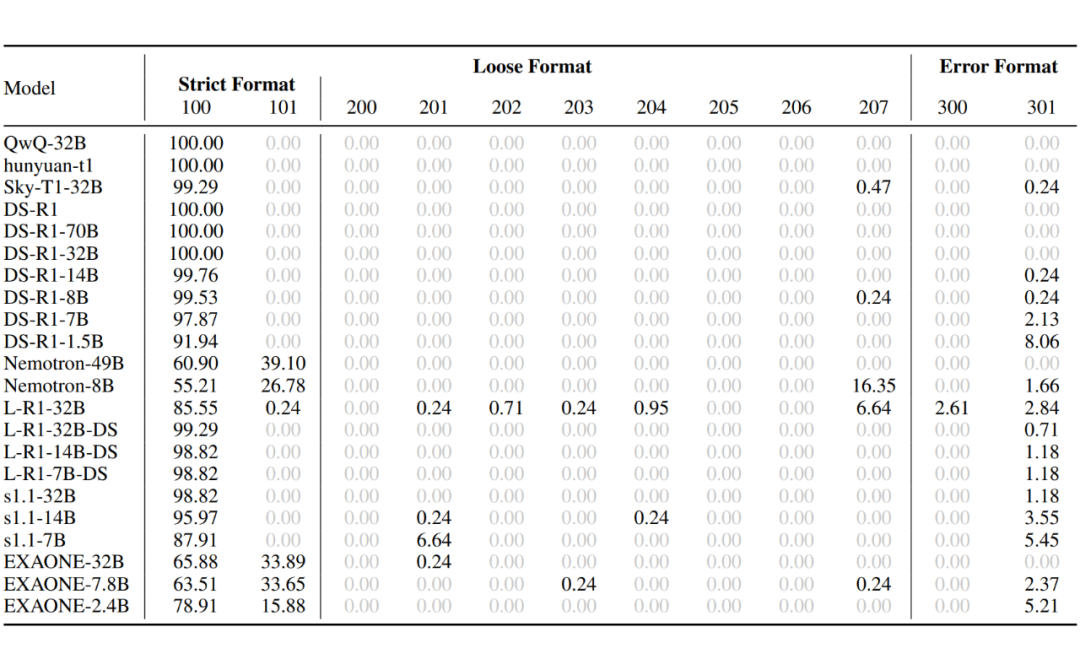
上表展示了 greedy sample 的格式统计。该现象与 top-p 采样大致相似。L-R1-32B 产生了 ID-300,这可能是由于训练方法与低温度之间的兼容性较差。

展望
本文提出的 S1-Bench 可以为后续的思维链压缩工作提供有效的快思考基线。在未来,将 LRM 训练出可以识别快思考问题、缩短思维过程、甚至不思考的能力,是值得探索的方向。
如何更好利用 LRM 对简单问题的预先判断,主动区分简单和困难的问题,是一个值得探索的方向。在 LRM 时代,如何更好平衡性能和效率,将一直作为基础任务被研究。
(文:PaperWeekly)